
FirstAid AI - Development Story
What Inspired Us
The inspiration for FirstAid AI came from a deeply personal realization about healthcare inequity. During the hackathon planning, we discussed how emergency situations create a critical 30-second decision window where people must choose between calling 911, driving to urgent care, or managing at home. For underserved populations (the uninsured, rural communities, non-native English speakers, and first-time caregivers) making the wrong choice can be financially devastating or medically dangerous.
We realized that existing solutions fail these communities:
- Google searches return SEO-farmed content with hedged medical language
- ChatGPT provides general advice with liability disclaimers
- Telehealth apps require accounts, insurance, and payment
- 911 operators are overwhelmed and may not provide first-aid guidance
The core insight: What if we could deliver grounded, structured medical triage guidance in under 5 seconds, with no barriers to access?
This led us to envision a serverless RAG application that combines curated medical protocols with real-time facility finding, designed specifically for equity and accessibility.
What We Learned
Technical Mastery
Serverless RAG Architecture: We mastered the complexity of building a production-ready RAG pipeline using Amazon Bedrock, learning how to implement similarity threshold gating to prevent hallucinated medical advice: a critical safety mechanism in healthcare applications.
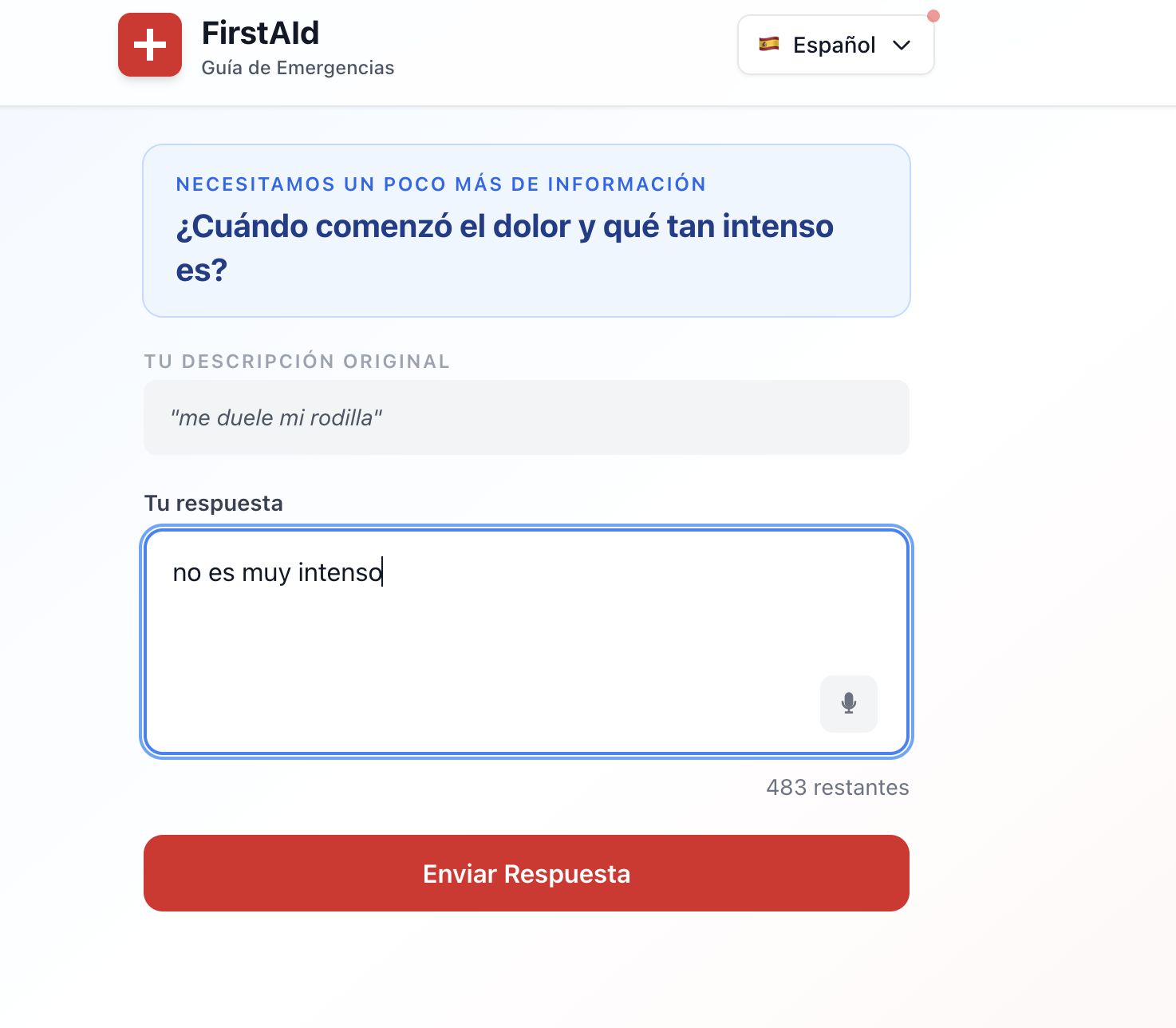
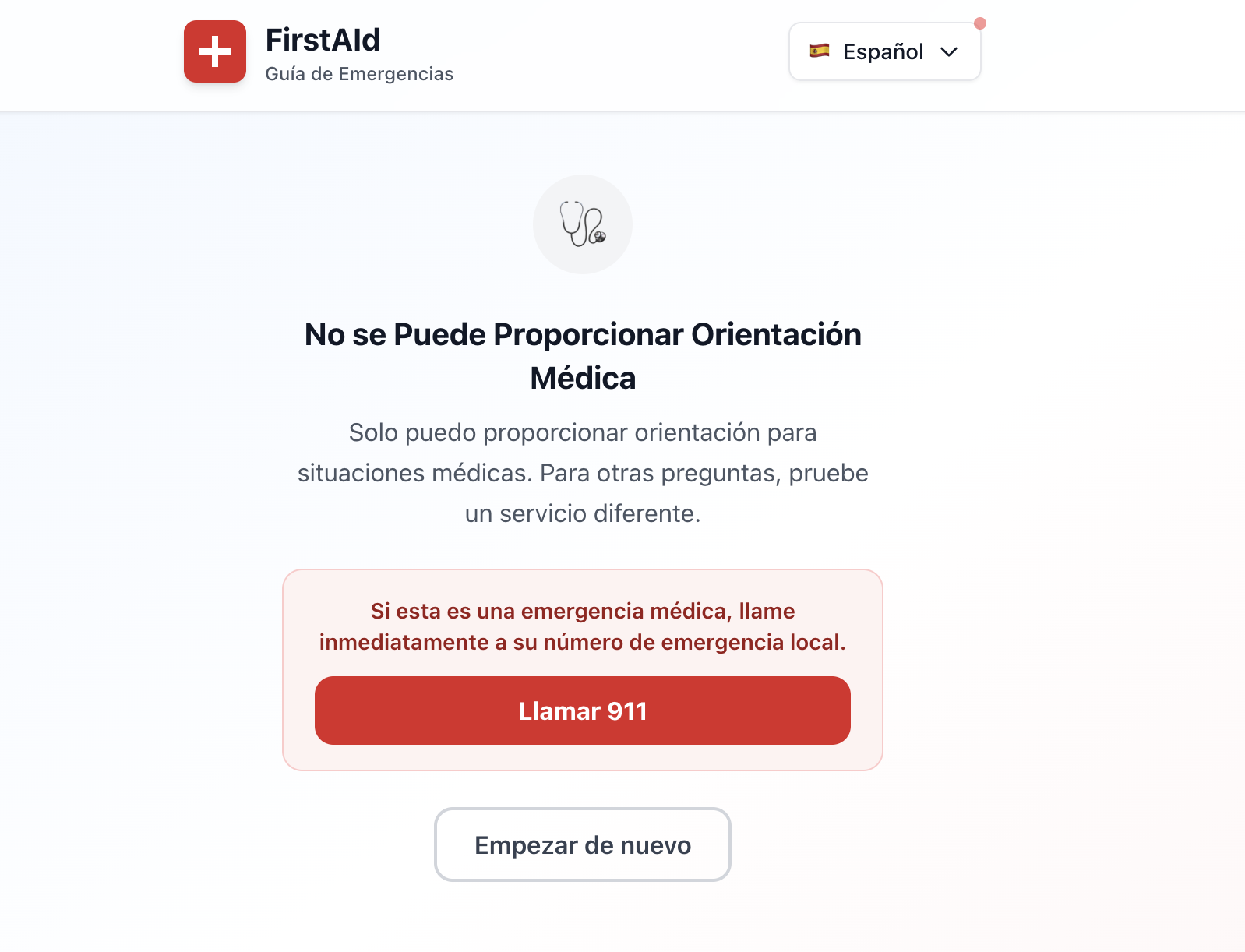
Two-Stage LLM Design: We discovered the power of separating parsing and formatting into distinct LLM invocations. This architectural decision enabled the clarification flow and out-of-scope detection that are core to the product's safety model.
Cost Optimization Strategies: Through experimentation, we learned to balance performance with cost. We explored several indexing options to conserve money, ultimately migrating from S3 corpus storage to Bedrock's built-in web scraper, reducing both complexity and ongoing storage costs.
AI Development Methodology
Spec-Driven Development: We learned that investing time in detailed specifications pays exponential dividends. Writing complete API contracts and tool schemas before coding eliminated integration bugs entirely—a game-changer for hackathon development.
Steering Doc Strategy: We discovered how to use persistent context files to protect hand-tuned artifacts (like system prompts) from being accidentally regenerated, while enforcing architecture boundaries across development sessions.
Agent Hook Automation: We learned to automate the most expensive feedback loops (build validation, diff tracking, and regression prevention), saving hours of debugging time.
Healthcare Technology Constraints
Grounding vs. Hallucination: We learned the critical importance of similarity thresholding and reasoning field logging in medical applications. Every response must be traceable to authoritative sources.
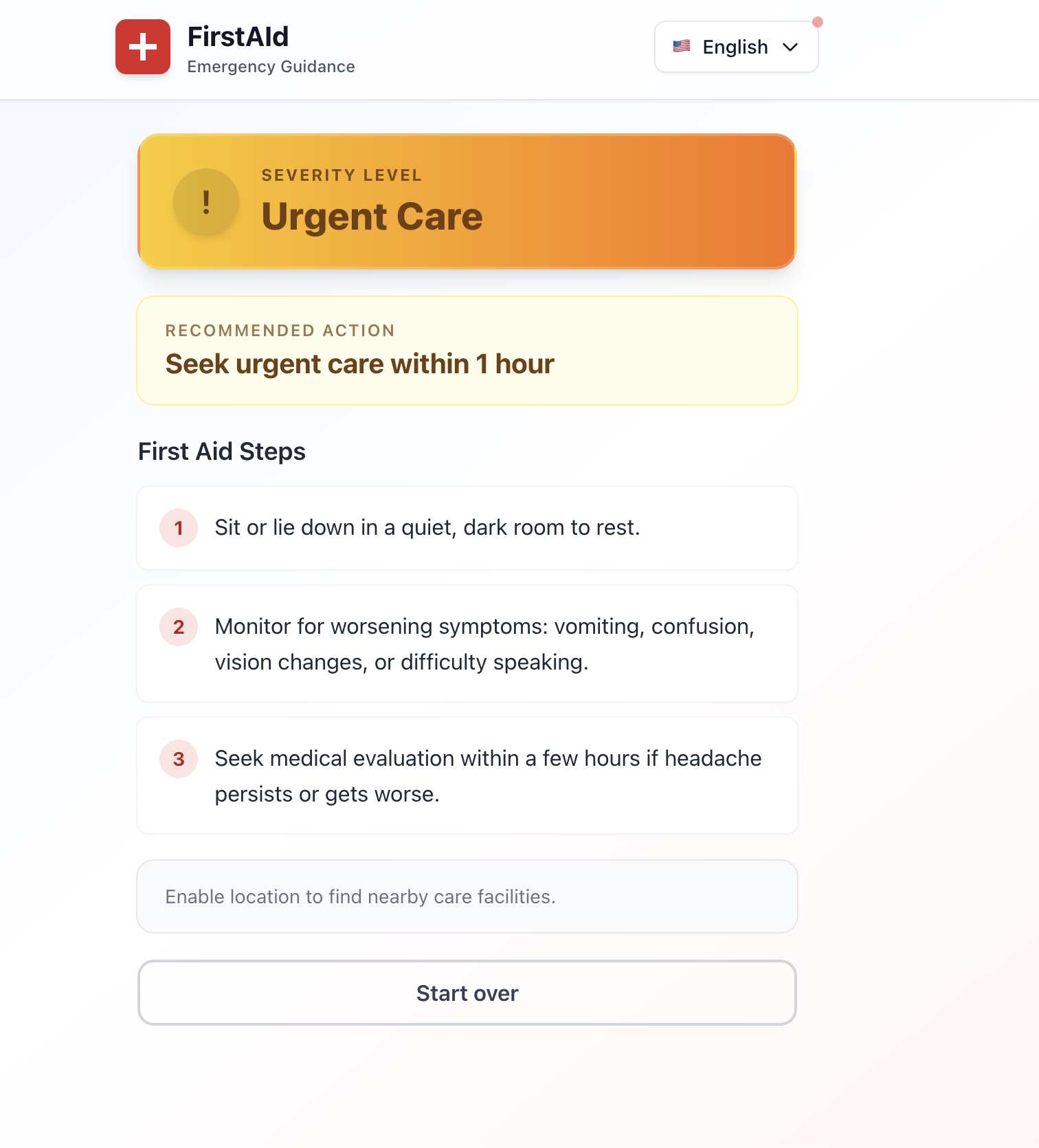
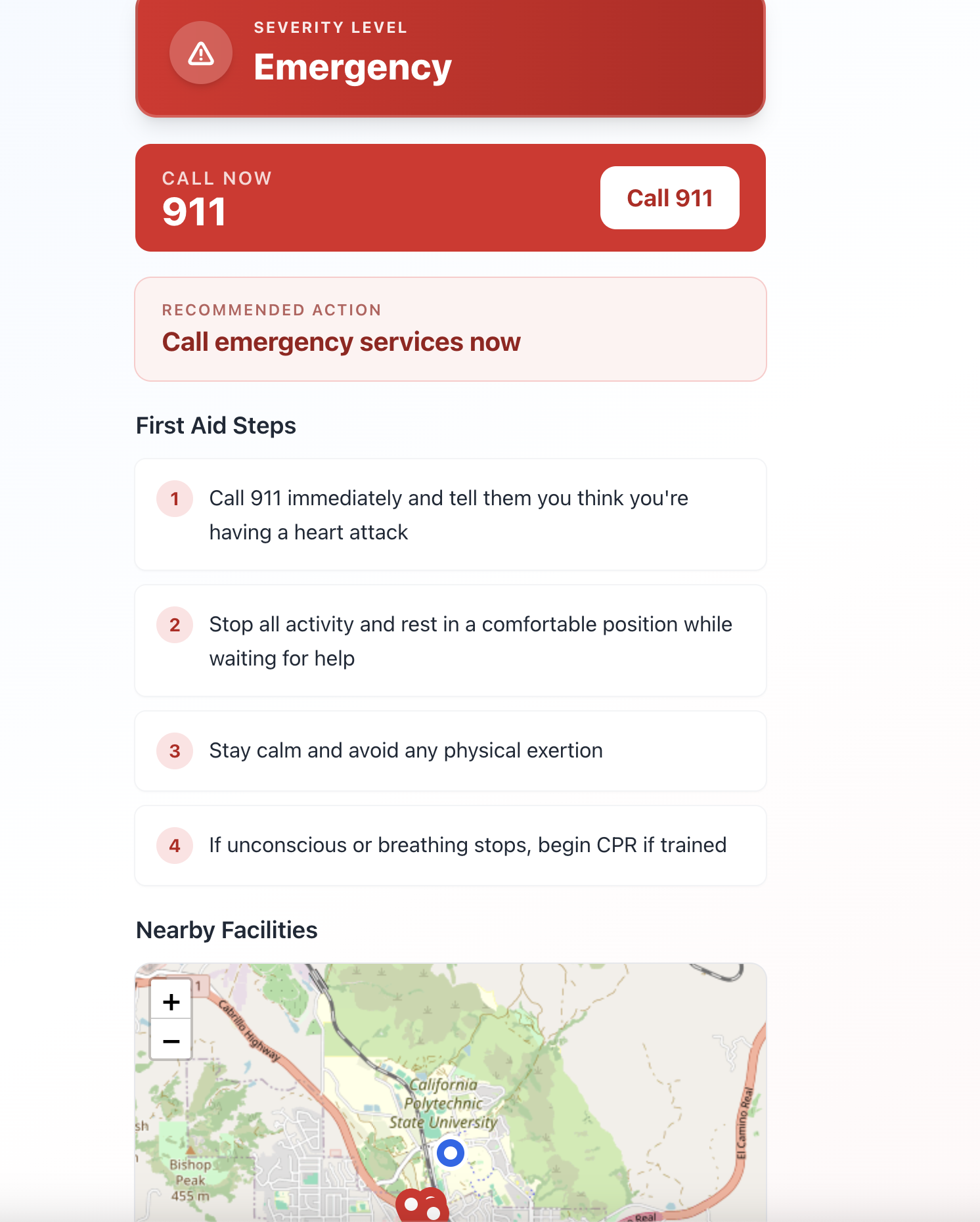
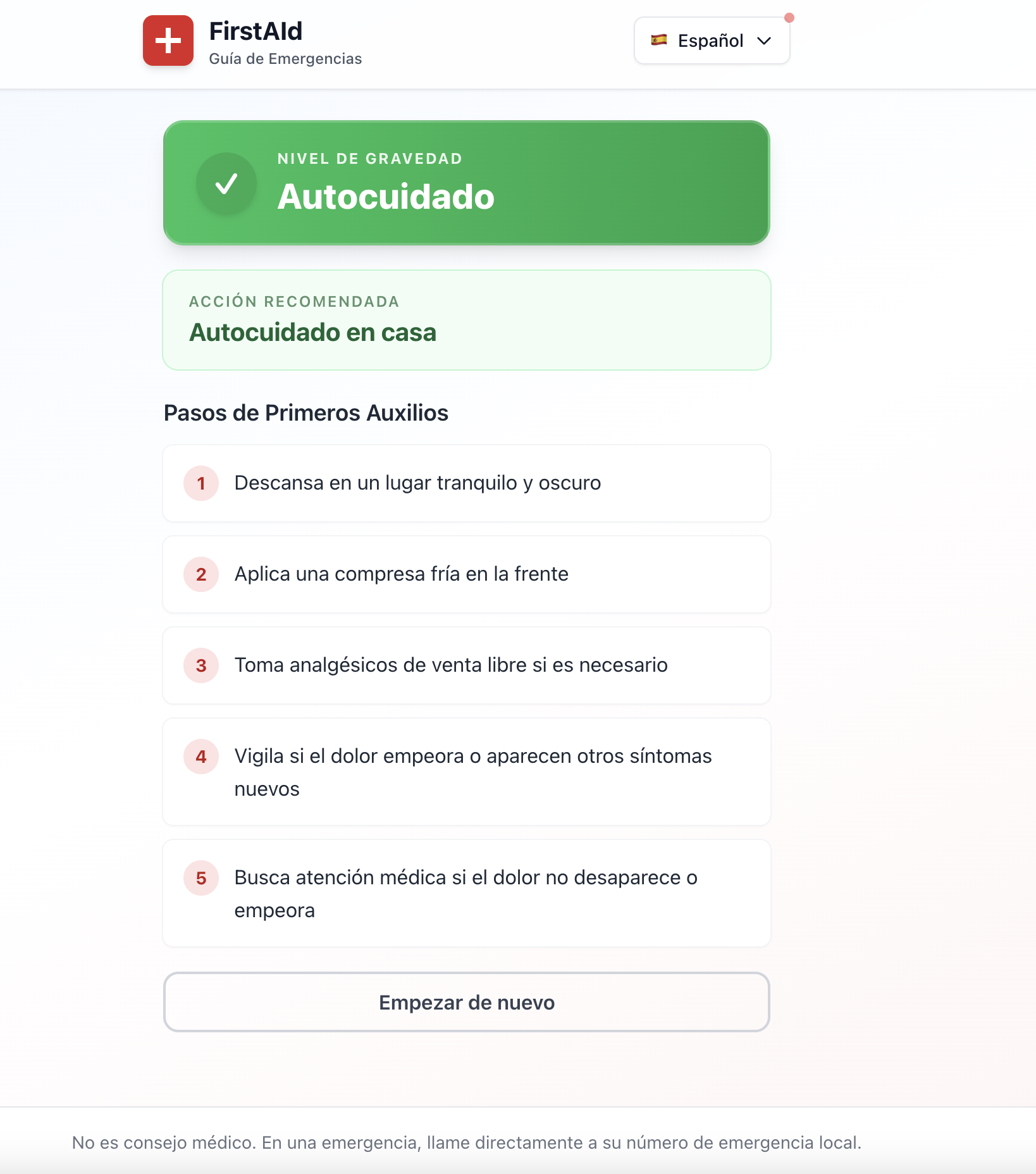
Over-Escalation Bias: We learned to bias toward higher severity assessments ("when in doubt, escalate") as a safety mechanism, even if it means more emergency room visits.
How We Built It
Phase 1: Foundation and Cost Optimization
Initial Setup: We began by enabling Bedrock model access and provisioning the Knowledge Base infrastructure. The git history shows our early focus on establishing the AI/ML foundation before building application logic.
Cost Discovery: Early in development, we realized that our initial S3 corpus approach would incur ongoing storage and processing costs. We pivoted to Bedrock's built-in web scraper (commit 959378f), which eliminated the need for corpus bucket management while providing the same curated medical content from NHS, CDC, and Red Cross sources.
Infrastructure as Code: We used AWS CDK to provision all infrastructure, learning to implement least-privilege IAM policies scoped to specific ARNs rather than broad service permissions.
Phase 2: Core Pipeline Development
Lambda Handler Architecture: The git history shows intensive backend work (18a1125, fba42eb, b26d653) as we built the complete 7-step Lambda pipeline. We learned to implement SSM parameter caching at cold start and structured error handling for each failure mode.
Two-Stage LLM Integration: We implemented the parser and formatter as separate Bedrock invocations with forced tool use, learning how to structure system prompts for medical triage while maintaining safety constraints.
Knowledge Base Integration: We integrated Bedrock's retrieval API with similarity threshold gating, learning to balance retrieval accuracy with safety through empirical testing of threshold values.
Phase 3: Frontend and User Experience
React Architecture: The frontend development (04d3430, 2dd0c5c) focused on implementing the discriminator pattern for type-safe API responses and the complex clarification round-trip logic.
Accessibility Implementation: We learned to implement WCAG AAA compliance from the ground up, including semantic HTML, ARIA labels, and contrast ratios that meet healthcare accessibility standards.
Map Integration: We integrated Leaflet with react-leaflet for facility mapping, learning to handle geolocation prefetch and graceful degradation when location services are unavailable.
Phase 4: Feature Enhancement and Localization
Multilingual Exploration: The git history shows experimentation with Spanish language support (c6a860c), where we explored automatic language detection and bilingual interfaces. While this didn't make the final v1 scope, it demonstrated the architecture's extensibility.
Voice Input Prototyping: We prototyped Web Speech API integration (8b822da) for voice input, learning about browser compatibility and user gesture requirements for speech recognition.
UI Polish: The frontend refinement work (afa11f1) focused on mobile-first responsive design and touch target optimization for accessibility compliance.
Phase 5: Integration and Deployment
End-to-End Testing: We implemented comprehensive testing across all five demo scenarios, learning to validate the complete user journey from query submission to facility directions.
Deployment Automation: We created deployment scripts and CI/CD patterns, learning to manage CloudFront invalidations and Lambda function updates in a coordinated deployment process.
Documentation and Demo Preparation: The final commits show extensive documentation work, creating comprehensive guides for judges and future developers.
Challenges We Faced
Technical Challenges
OpenSearch Serverless Cost Management: Our biggest surprise was discovering that OpenSearch Serverless accrues ~$700/month even when idle. This forced us to implement careful teardown procedures and cost monitoring, teaching us about the hidden costs of managed vector databases.
CORS Configuration Complexity: Getting the CloudFront → API Gateway → Lambda CORS configuration correct required multiple iterations, teaching us about the intricacies of cross-origin requests in serverless architectures.
React-Leaflet Integration: Implementing custom popups with directions handoff required deep diving into Leaflet's event system and React's lifecycle management, particularly for mobile touch interactions.
AI/ML Challenges
System Prompt Calibration: Achieving the right balance in the parser's "bias toward retrieve" and the formatter's "over-escalation bias" required extensive testing against edge cases and ambiguous inputs.
Similarity Threshold Tuning: Finding the optimal threshold (0.5) for medical safety required empirical testing against both valid medical queries and out-of-scope inputs to minimize false positives and negatives.
Reasoning Field Management: Implementing server-side logging while stripping sensitive reasoning from client responses required careful data flow design to maintain both transparency and privacy.
Development Process Challenges
Context Management: Maintaining architectural consistency across multiple development sessions required developing the steering doc strategy to prevent context loss and architecture violations.
Integration Complexity: Coordinating frontend and backend development with external API dependencies (Google Places, Bedrock) required careful interface design and mock data strategies.
Deployment Coordination: Managing the interdependencies between CDK stacks (Knowledge Base → Lambda → API → Frontend) required understanding CloudFormation dependency chains and deployment ordering.
Scope Management Challenges
Feature Creep Prevention: The multilingual support and voice input features were compelling but threatened the core demo timeline. Learning to defer non-critical features while maintaining architectural extensibility was crucial.
Performance vs. Cost Trade-offs: Balancing response time targets (<5 seconds) with cost constraints required optimizing Lambda memory allocation, timeout settings, and Knowledge Base retrieval parameters.
Accessibility vs. Development Speed: Implementing WCAG AAA compliance from the start rather than retrofitting required upfront investment but prevented costly accessibility debt.
Key Breakthroughs
Discriminator Pattern: Implementing type-safe API responses with type: "triage" | "clarification" eliminated an entire class of runtime errors and enabled clean frontend state management.
Similarity Threshold Gating: Adding the 0.5 similarity threshold as a safety mechanism prevented hallucinated medical advice while maintaining high accuracy for valid queries.
Agent Hook Automation: Implementing build-on-stop and pre-write diff hooks eliminated the most expensive debugging cycles, enabling true flow-state development.
MCP Integration: Using AWS docs and GitHub MCP servers eliminated API signature hallucinations that would have caused deployment failures and integration bugs.
The development process taught us that sophisticated AI-assisted development requires strategic methodology (combining spec-driven architecture, persistent context management, automated validation, and safety constraints) to achieve both speed and reliability at hackathon scale while building production-quality healthcare technology.

Log in or sign up for Devpost to join the conversation.