-
-
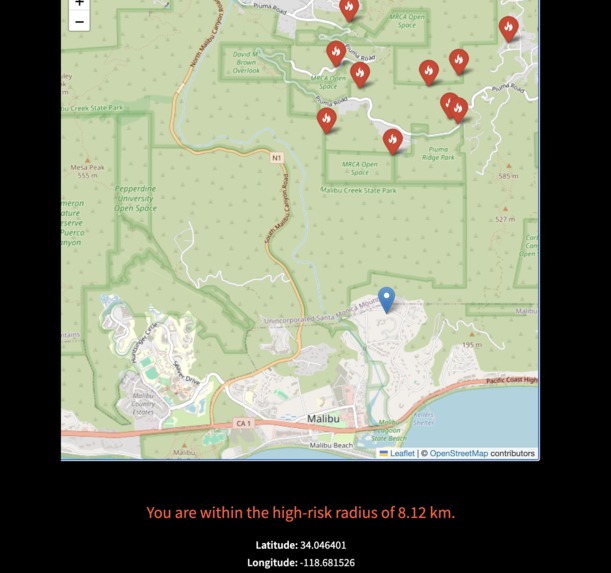
High risk area
-
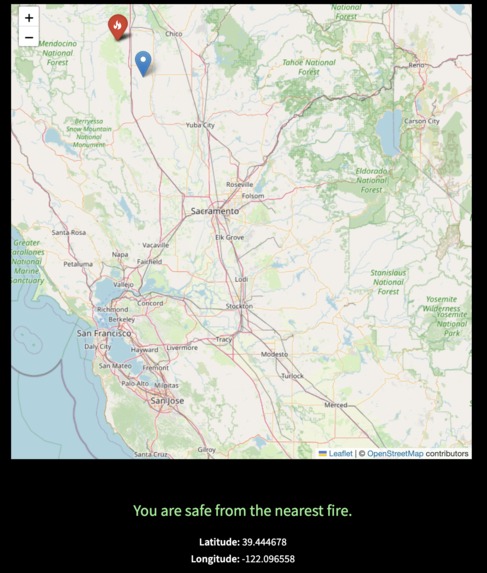
Low risk area
-

Safety Resources



Inspiration
California has always been an extremely fire-prone state. The Palisade Fires hit close to home, especially one of our group members who lives in LA County. With the fires in Palisades affecting millions, we aimed to design a system to better predict fire spread and burn areas. Users could plan to see if they were in danger of being ordered to evacuate and prepare in advance.
What it does
The app displays a map of all current fires, updated daily. When the user clicks on the map, we calculate the risk from the closest fire and output whether the user's location is safe or within the danger zone. The risk is calculated using current weather and geographical data, and if the user is at risk from the closest fire, we output the predicted burn radius.
How we built it
We trained a Random Forest Regressor model on a dataset with information about forest fires and the terrain and conditions surrounding the incident. We used the columns time of year, precipitation, humidity, wind speed, and temperature to train the model. After tuning the hyperparameters, we uploaded the trained model into our Streamlit app, which scrapes data about current weather conditions based on location and feeds those parameters into the model. We also used the NASA FIRMS dataset to gather real-time information about fire location and filtered to show only fires above a certain severity threshold. The model outputted the predicted burn area and we measured the distance between the chosen location and the fire to determine if the user's location was safe or at risk.
Challenges we ran into
We had a lot of trouble finding a dataset for our ML model. Our initial dataset was a TFRecord file with 19 different files. The CNN model we made for this took an unreasonable amount of time to run and while dumping the file to upload to our Streamlit app, errors occurred while downloading and the model would not run correctly. The other option for our dataset was too large and caused the computer to crash multiple times. We solved this by taking only a certain number of rows, but the dataset’s formatting caused the accuracy to drastically reduce. Our last dataset was a CSV file but our initial models had low r2 scores, so we tuned the hyperparameters and tested different models.
Accomplishments that we're proud of
Our model scrapes weather data from the web to provide accurate, real-time information based on only a location on a map. We made the user experience much easier because instead of having a user manually input weather data for the model, they only have to click on an area. The map API also allows the user to zoom in close enough for them to pick a highly specific location, which is more practical than a zip code. Houses closer to the fire will show higher risk while houses farther away could be outside the predicted risk area, which is more accurate than classifying an entire zip code as within the predicted evacuation zone or not.
What we learned
We learned how to scrape data and got experience deploying and using a machine-learning model for implementation in an app with user input and real-time data. While creating the machine learning model, we got to practice with different models and frameworks, such as Convolutional Neural Networks and TensorFlow. We had to work with different types of data, as our initial dataset was formatted in a TFRecord file and our real-time fire data was a CSV file, so we parsed each dataset in different ways. We also worked with different APIs to display the map and find weather data.
What's next for FireWatch
Our next steps are to generate a map of the predicted wildfire spread for each day. This model would take in a map of the fire data from the current day along with the weather and geographical information we scraped from the web. From this map, we could continue to output whether the user was at risk while showing which parts of their community were likely to be affected. We also plan to test other models and add data features to train a model with higher accuracy. When we initially tested CNN, it took an unreasonable amount of time to run with 15 epochs, so we would try a more complicated model like this but optimize it to make it feasible to train and run. We would also continue to improve the website’s interface.
Built With
- beautiful-soup
- python
- random-forest
- streamlit
- tensorflow



Log in or sign up for Devpost to join the conversation.