-
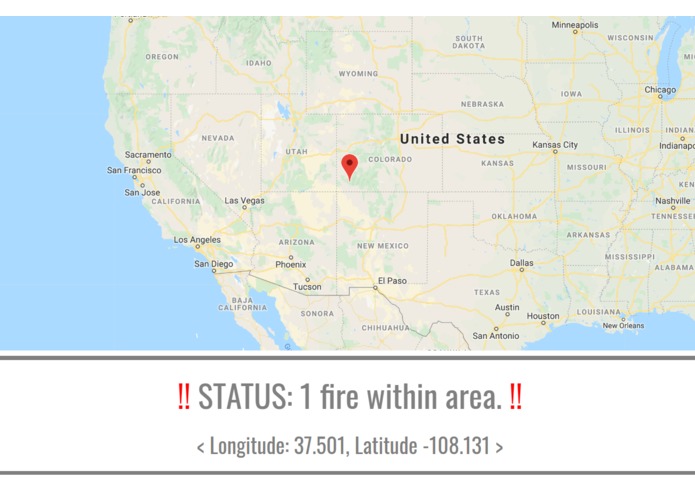
Alert System.
-
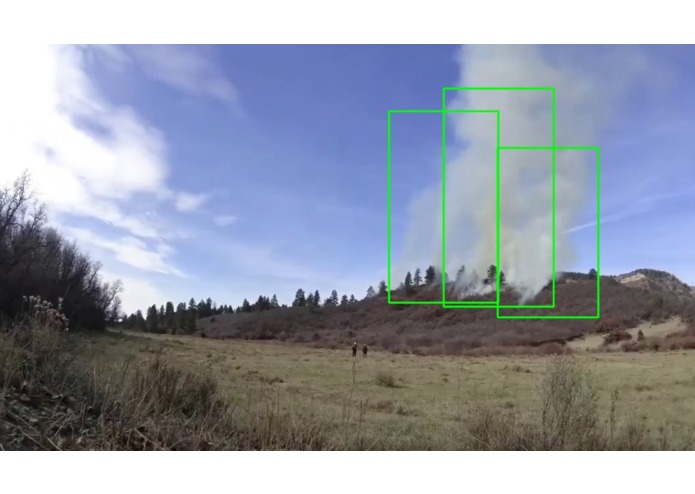
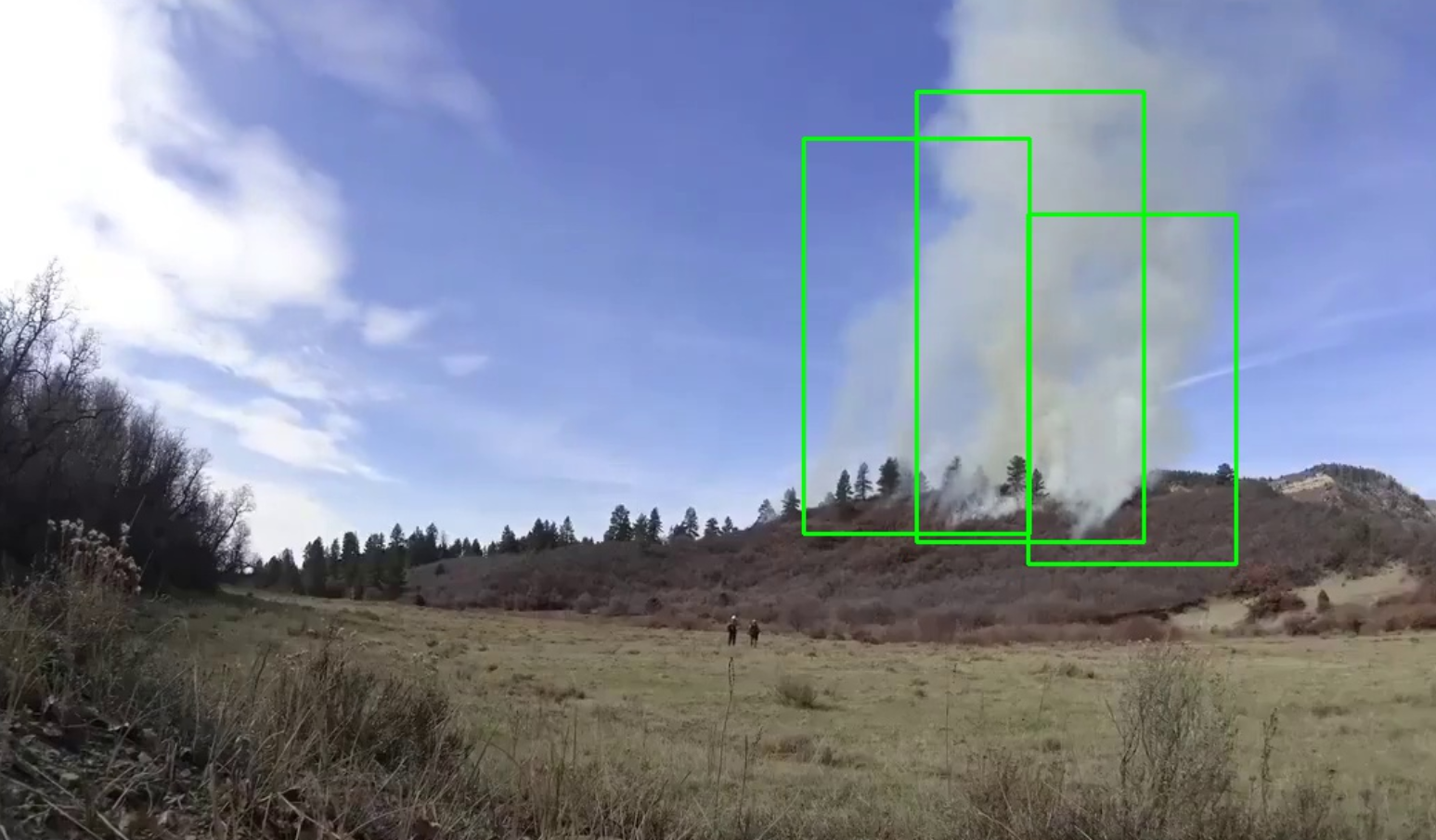
Smoke recognition using CV.

Inspiration
Fire detection systems are essential safety devices that have been around for some time now. Of these, traditional particulate-based smoke-detection devices are the most common, yet unfortunately, these are not always suitable for use in certain areas. Namely, large open areas such as national parks require staffers in fire lookout towers to observe the surrounding landscape for signs of smoke or fire throughout the year; however, it costs money and time to hire these staffers and build fire lookout towers.
What it does
In response to this issue, we have used computer vision and machine learning algorithms to automate the process of surveying these kinds of areas for signs of fire. This way, only a few cameras placed sparsely apart are needed to monitor the surrounding wilderness, drastically reducing the cost of this operation. Whenever a camera sees an image that the algorithm recognizes as a fire, it notifies the central system immediately with information about the fire's coordinates, allowing rangers to respond quickly and efficiently.
How we built it
We tried to recognize smoke as our main part of a project, since the first indicator of a forest fire is the smoke rising from the ground. The main processing part of the project was built using Google Cloud. We used the Auto-ML machine vision library to recognize and supply the bounding boxes for any smoke that was detected. Our model was a custom trained one, which required us to upload large numbers of sample images, and manually mark them. After that was done, we simply sent a request to the Google Cloud server based on each frame of our video feed and parsed the results to display the video on our website in real-time.
Another significant part of our project was the real time tracking of data that had been identified by Auto-ML. Since each camera is fixed, we know the GPS coordinate of that camera. When the camera detects smoke, a notification pops up on our website, indicating that a certain number of fires were found, as well as a detailed Google Maps panel pointing to the fires. This makes monitoring the system extremely easy.
Challenges we ran into
One major challenge we faced was how our model was incorrectly recognizing background clouds as smoke. We tried a few things. First, we converted the image into binary black/white, and only recognize parts where the whiteness of the smoke was seen over the black background. This however, proved to be too unreliable due to the varying thicknesses of the smoke involved. Second, since smoke starts from the ground, we attempted to filter out results based on whether it crossed the horizon in our image, but we realized smoke that was already far up in the air would be classified as clouds in this process. We finally decided to train another model, based upon only the starting location of the smoke, intentionally capturing some of the surrounding ground in the process. This proved to be the most reliable model throughout our tests.
Accomplishments that we're proud of
Although we did not accomplish all of the goals we set out to do, we are still glad that we were able to get pretty far. This was the first time that both of us worked with Google Cloud, computer vision, and web development, let alone all three in the same project. We learned many new skills, such as interacting with servers, building websites, and training and optimizing machine learning models, all within a span of 24 hours. Lastly, both of us had trouble before integrating our separate parts into one coherent project, but this time, we collaborated more efficiently, and were able to do this more seamlessly due to long term planning, and preventative coding.
What we learned
In terms of technical skills, we learned two main skills at this hackathon: web design and basic computer vision. For the former, we had to code in three new languages, Javascript, CSS, and HTML, and we learned how data is kept secure when interacting with a server. For the latter, this hackathon was the first real exposure both of us had to computer vision, and we learned how images were represented, how to perform operations on them, image editing within python, and simple algorithms. We also had to deal with some advanced material, such as training and optimizing machine learning models, which required us to do some research into both the theory and the accepted practices that people use.
What's next for FireVision
Currently, the main limitation of our project is how we rely on visual data to detect smoke. This means that our ability to detect smoke during the night is severely restricted. A possible solution to this would be to incorporate not only just visual data into our algorithm, but also infrared data based on the temperature gradient between rising smoke and the air around it.


Log in or sign up for Devpost to join the conversation.