-

Poster
-

Attention Weights for Transformer Model Predictions

Inspiration
Over the past several years, increasingly devastating wildfires have posed a growing threat around the world. In California alone, over 8800 fires burned approximately 2.5 million acres of land in 2021, causing unprecedented economic and safety risks. Early detection and real-time monitoring of wildfire spread is crucial to both prevent and mitigate the damage caused by these large-scale natural disasters. Sensor-based tracking technologies have recently been deployed for monitoring multiple environmental stressors, resulting in immense amounts of useful information; unmanned drones, in particular, can serve as a rich source of visual data, as they are capable of capturing detailed aerial images of actively burning areas. In this project, we leverage the vast image data collected through these devices to detect the presence of wildfires, with the aim of producing a deep learning ensemble model that be applied to recognized fires in real-time on an Unmanned Aerial Vehicle.
What it does
We build upon state-of-the-art image classification techniques on predicting wildfire presence from aerial-view photographs, comparing the effectiveness of transformer models against traditional CNN-based architectures in tackling the problem of wildfire detection.
We tackle the problem of predicting whether a wildfire is present or absent in an aerial-view image taken by an Unmanned Aerial Vehicle, or UAV. Our approach considers this problem as a classification task, where the two classes predicted by our model are “Fire” and “No Fire”. In this vein, our model and baseline take in JPG color images from over burning and non-burning locations in forested areas (sourced from the FLAME dataset) as input. The output of our models consists of binary classification scores. We examine classification accuracy and F1 score as the primary metrics of evaluation for our approach, both overall and within individual classes. We additionally consider model efficiency as measured by memory consumption and inference time.
How we built it
In our transformer-based architecture, we fine-tune a Vision Transformer model pretrained on Imagenet. We additionally introduce data augmentation to improve model generalizability, introducing flipped, rotated, and color-jittered images into our training dataset. We also leverage pretrained Resnet and Densenet pretrained CNN architectures as feature extractors, training linear classifiers on these features using our FLAME data.
Beyond comparing the performance and tradeoffs of these approaches, we explore model ensembling techniques to further boost performance. These include a voting scheme between our three most performant models, a confidence-based approach in which outputs with larger normalized scores are chosen, and a feature concatenation approach where a linear classifier is trained on the combined outputs of multiple models.
Challenges we ran into
- Distribution shift between the validation and test sets - in the FLAME dataset, images from the training and validation sets are taken on a different type of drone than images from the test set. The associated differences in camera type as well as angle, drone height, and scenery made it difficult to achieve comparable classification accuracy on the validation and test sets. However, these differences also imply that a model that is performant on the test set can also successfully generalize across the variety of UAV hardware and remote sensing methods used in practice.
- Fine-Tuning the right model: Deep Learning, especially on images has rapidly evolved in recent years, with a plethora of new architectures and techniques. One other challenging task during the course of this project was to explore and figure out the right models and deep learning techniques that increase the performance of this task. With the limited compute and data available to us, it was a challenge to explore multiple architectures and improve their performance.
Accomplishments that we're proud of
- Significantly outperforming the published FLAME Xception network baseline accuracy of 76% to achieve 81% classification accuracy on the test set
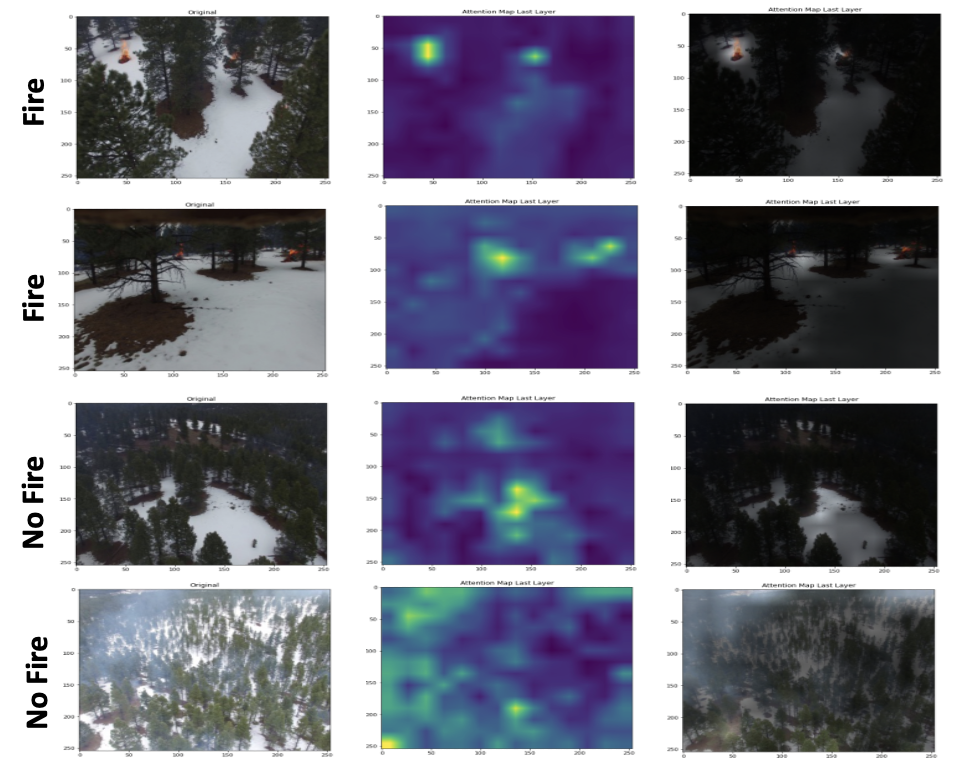
- Generating qualitative attention weight visualizations that provide deeper insight into how our model works and what parts of an image it focuses on for classification. This provides explanations and interpretability of the model and also improves the credibility in its predictions.
- Successfully combining results from a variety of CNN and Transformer architectures into a cohesive ensemble model
What we learned
Through this project, we learned how to adapt existing state-of-the-art Deep Learning architectures for computer vision to address real-world challenges. In particular, we were able to explore how pretraining can serve as a powerful foundation upon which to develop specialized architectures tailored to perform well on the task of wildfire detection. We also had the opportunity to delve deeper into the benefits and drawbacks of different forms of ensembling and data augmentation, discovering that using techniques that aligned with our model's application enabled us to create models that could adapt to substantial variation in image data.
What's next for FireSight: Transformers for Wildfire Classification
The next step in our approach is to implement model compression. Large machine learning models like Transformers are not easy to deploy and run on Unmanned Aerial Vehicles, due to their limited storage capacity and must additionally produce real-time results from a continuous stream of aerial images. To combat this, we would like to prune our proposed model to both shrink the memory required and to reduce inference time. We plan to explore the tradeoffs between memory requirements and classification accuracy.



Log in or sign up for Devpost to join the conversation.