Inspiration
As university students, we despise the budgeting process after a big weekend grocery haul: cataloging every details of the waves of receipts that we take home just to spend a big chunk of time punching in numbers, calculating budget, and figuring out the good ol' question of whether "ketchup" should be in the condiment category or truly, it should be in the fruit section because it's basically a smoothie if you put adequate thought into it. Regardless, this seemingly rudimentary task should not be this overwhelming that leaves us drained and countless into-the-receipt-pile receipts.
Thus, we thought of an idea: what if we create a platform where an AI could tell us all the necessary information just from an image of a receipt? That's where FINVOICE comes in.
What it does
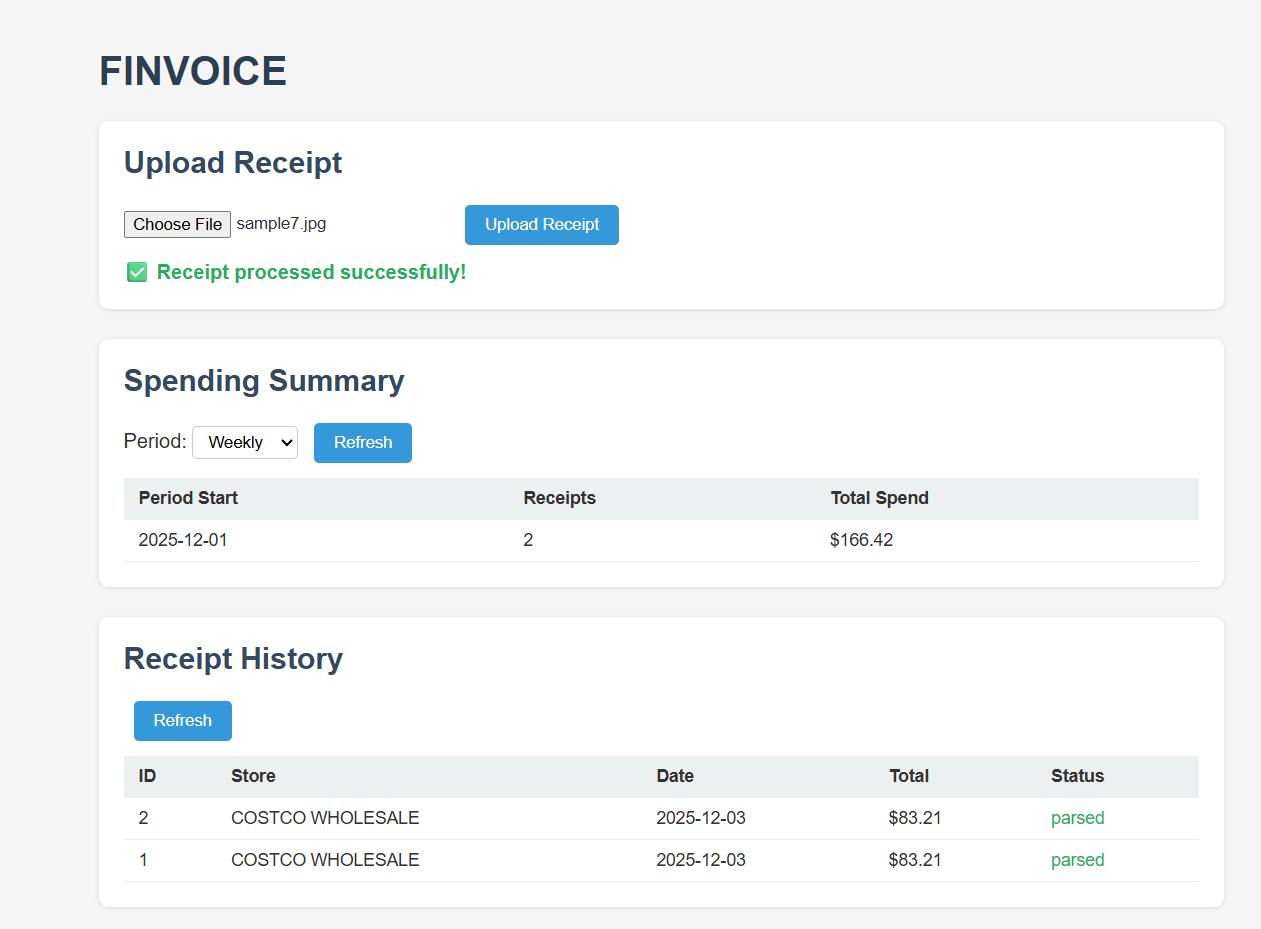
FINVOICE is a web application that allows users to upload receipt images, automatically records those data and summarizes their expenses. The system extracts key info such as store name, purchase date and total amount using Tessaract OCR and Google Gemini, then stores the data in a SQLite database.
How we built it
Our project was split into 3 main tasks done simultaneously.
The first task is to process uploaded receipt images using OpenCV techniques such as grayscale conversion, resizing and thresholding to improve Tessaract OCR accuracy. The preprocessed images are then passed through such model (Tessaract OCR) to extract text content.
The extracted text is then sent to the Google Gemini API, which helps with identifying key receipt details. We implemented validation logic using Pydantic schemas to ensure that the reponses from such LLM conform to a structured JSON format, with retry logic to handle malformed outputs.
Then parsed receipt data is stored in a SQLite database. The frontend implemented using JavaScript, HTML and CSS retrieves this data to display receipt history and generate weekly spending summaries through 2 boards.
Challenges we ran into
The biggest challenge was that receipt images vary widely in formatting, lighting conditions and layout, which made OCR extraction inconsistent. We had to apply image image preprocessing techniques to improve text recognition accuracy across different receipts. Although we implemented validation checks and retry prompts to handle invalid outputs and maintain consistent database storage, ensuring that the AI model returned structured JSON data reliably was also a big challenge. Another problem that we faced was accepting the fact that we were limited to the knowledge and technical skills each of us are capable of bringing to the table, along with the amount of resources and APIs that we had on hand. Therefore, this has been an immense, albeit necessary and actually positive, learning curve for us
Accomplishments that we're proud of
Nevertheless, we still take pride in what we have designed and created. Despite the randomness of the text analysis, our product can still display the correct total and date at the end (given a few variables of the receipt images). Moreover, our team work was surprisingly well maintained, there were little to no team disagreement and even if we do, were able to give constructive criticism and have meaningful conversations.
What we learned
Through this project, we learned how to integrate OCR and large language models into a production-style workflow. We also gained experience designing REST APIs, validating AI-generated outputs, and building responsive dashboards that communicate effectively with backend services.
What's next for FINVOICE
We are planning on supporting PDF files and adding more insight features





Log in or sign up for Devpost to join the conversation.