-
-
Landing Page
-
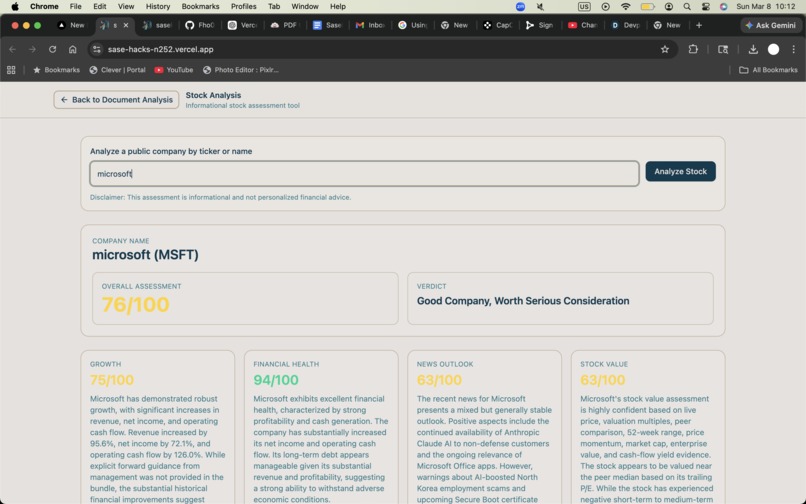
Stock Analysis
-
PowerPoint Generation
-
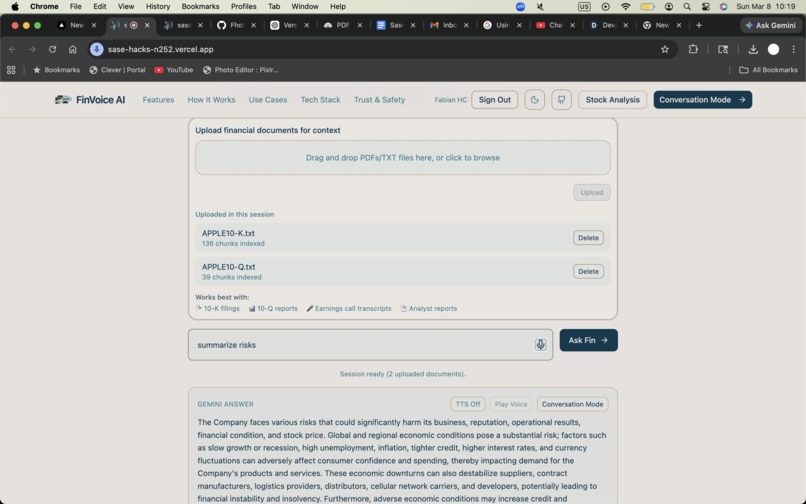
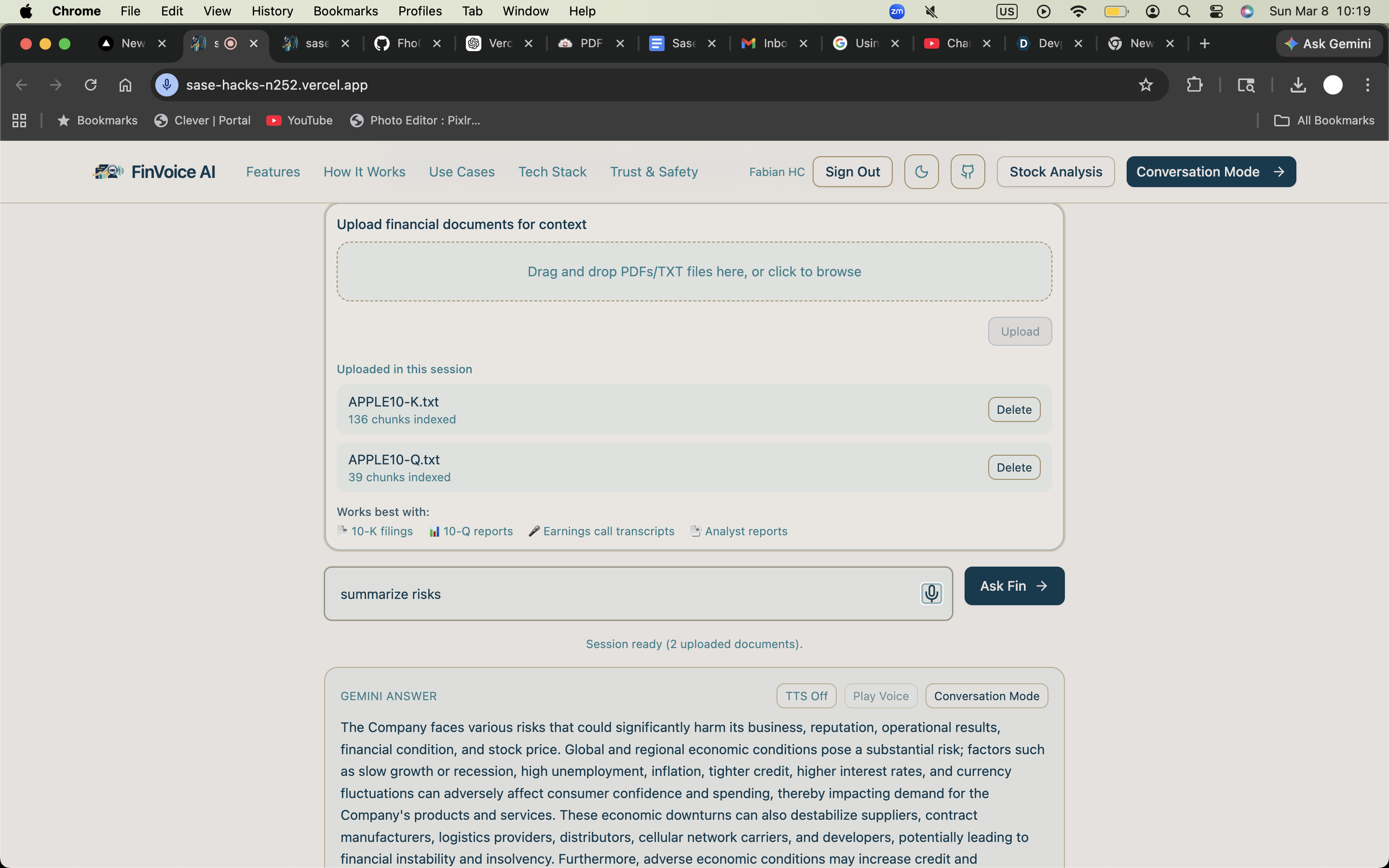
Summary and session file upload. Prompt box for user requests.
-
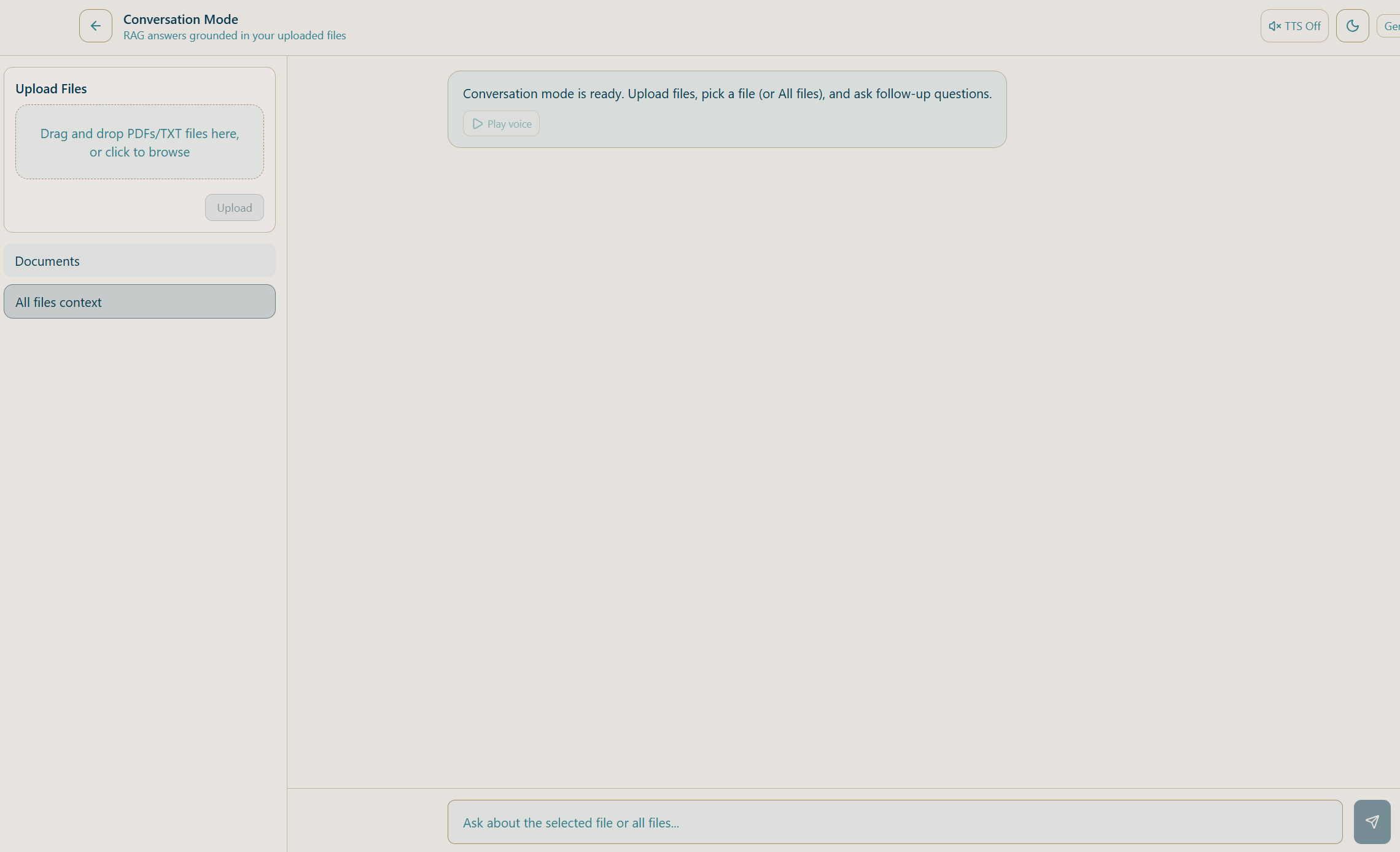
Conversation mode
About the project
Inspiration
FinVoice AI was inspired by a simple problem: financial research is slow, fragmented, and often hard to trust. Important information is buried across long filings, reports, articles, and market data sources, while generic AI tools often produce answers that sound confident but are difficult to verify. We wanted to build something more useful for due diligence: a copilot that helps users move faster without losing trust, context, or source visibility.
That led us to build a platform where users can upload financial documents, ask natural-language questions, get citation-backed answers, generate structured briefings, listen to responses, and analyze public companies through a more explainable stock-analysis workflow.
What it does
FinVoice AI is a financial document intelligence platform and research assistant. It allows users to:
- Upload financial documents securely under their authenticated account
- Ask questions about those documents and get grounded, citation-backed answers
- Generate AI financial briefings from long reports
- Listen to answers through text-to-speech
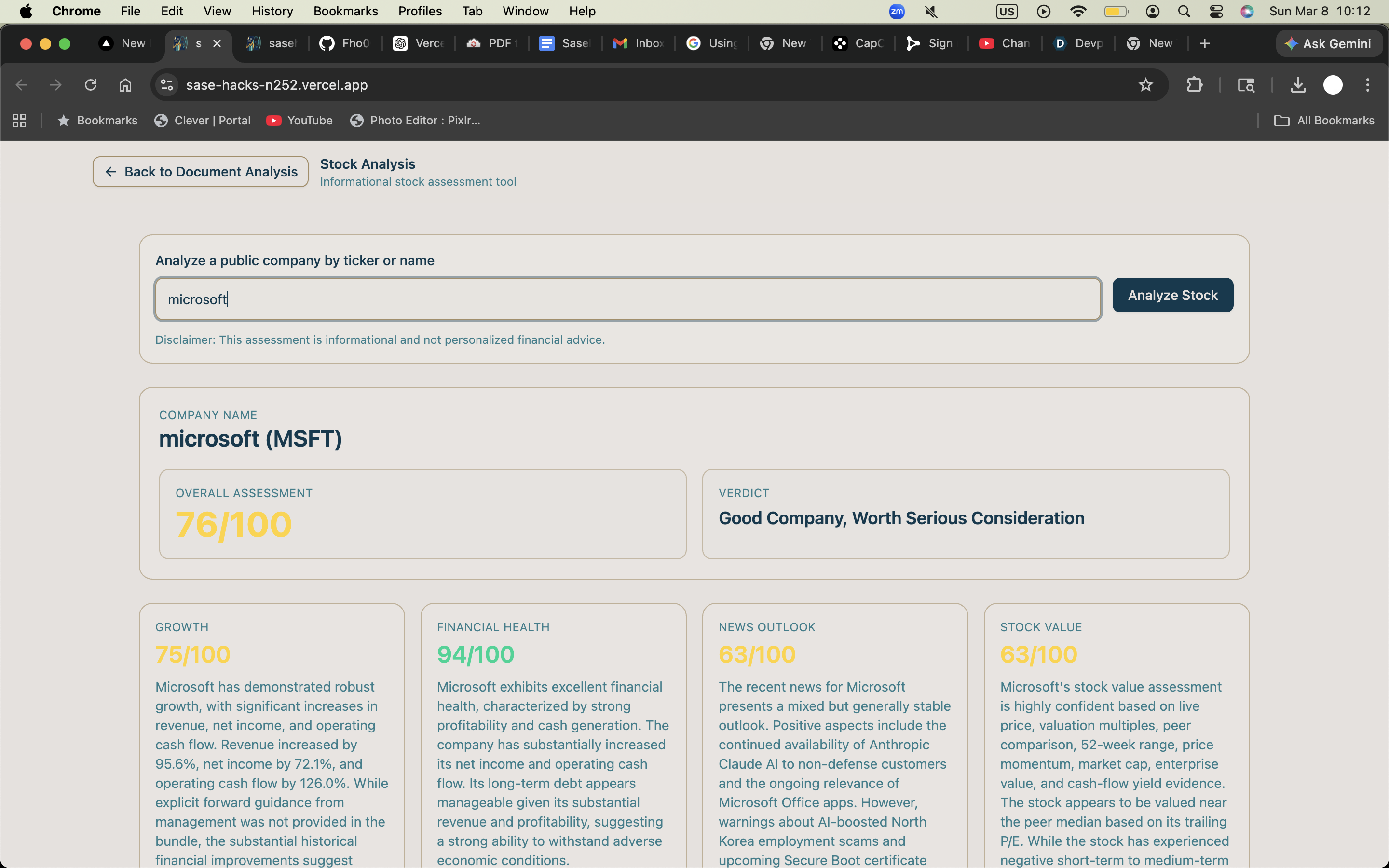
- Analyze public companies by ticker or name using news, SEC filings, market data, and peer comparison
- View scored outputs across Growth, Financial Health, News Outlook, and Stock Value
The goal is not to replace judgment or provide personalized investment advice. The goal is to make research faster, more organized, and more explainable.
How we built it
We built FinVoice AI with a Vite + React + TypeScript frontend and a Node.js + Express backend. Authentication is handled with Firebase, while data storage and retrieval are powered by MongoDB Atlas, including Atlas Search and Atlas Vector Search.
For the document intelligence side, uploaded files are parsed, chunked, embedded, and stored. When a user asks a question, the backend uses a hybrid retrieval pipeline that combines semantic retrieval and keyword search, then fuses the results before sending only the relevant evidence to Gemini. That keeps answers grounded in retrieved material instead of letting the model answer from thin air.
For the stock analysis workflow, the backend resolves a company by ticker or name, gathers evidence from news sources, extracted article text, SEC filings, market data, and peer valuation, then sends a normalized evidence bundle to Gemini for structured reasoning. After that, the backend applies deterministic scoring formulas to compute the final category scores and overall assessment. We intentionally kept scoring and weighting in backend code so the most important business logic would stay stable, inspectable, and consistent.
We also added ElevenLabs for text-to-speech, plus provider fallbacks, caching, and a modular portfolio pipeline to keep the system resilient and easier to extend.
Challenges we ran into
One of the biggest challenges was working around the limitations of LLM behavior, especially in structured financial workflows. Gemini is strong at reasoning, summarization, and turning messy evidence into readable analysis, but it is still a model, which means it can be inconsistent if you rely on it too heavily for hard logic. A major challenge was making sure outputs stayed in a predictable shape and that scores remained consistent from run to run.
We solved that by using strict JSON prompting, output normalization, and backend validation, while keeping arithmetic, weighting, and verdict logic deterministic in code instead of leaving them entirely to the model. That was an important design decision.
Another challenge was dealing with external data variability. News providers, SEC data, market data coverage, and extracted article text do not always arrive cleanly or consistently. Some providers may be unavailable, fields may be missing, and article extraction can fail depending on the source page. To make the experience more robust, we built fallback paths, source ranking and deduplication, and optional caching with Redis/Upstash plus in-memory fallback.
We also had to balance usability with trust. It is easy to build something flashy, but much harder to build something users can actually inspect and rely on. That is why citation-backed answers, source lists, authenticated data ownership, and disclaimer-based positioning were all important parts of the project.
Value to users
FinVoice AI contributes value in five main ways:
- Speed — it compresses long research workflows into a conversational experience.
- Trust — it grounds answers in retrieved evidence and surfaces citations and sources.
- Explainability — it does not just output a verdict; it shows category-level scoring, positives, risks, and supporting sources.
- Accessibility — users can move between reading, chatting, summarizing, and listening in one place.
- Practicality — it helps users process information overload without pretending to be a black-box replacement for judgment.
In short, FinVoice AI turns financial documents and market signals into a more usable, traceable, and explainable research workflow.
Built With
- altas-vector-search
- elevenlabs
- express.js
- firebase
- fmp
- geminiapi
- marketdataapi
- mongodb
- mongodb-atlas
- multer
- newsapi
- node.js
- pdf-parse
- pptxgenjs
- rag
- react
- redis
- sec
- shadcn/ui
- sharp
- tailwind
- typescript
- vite


Log in or sign up for Devpost to join the conversation.