-
-
Home Page
-
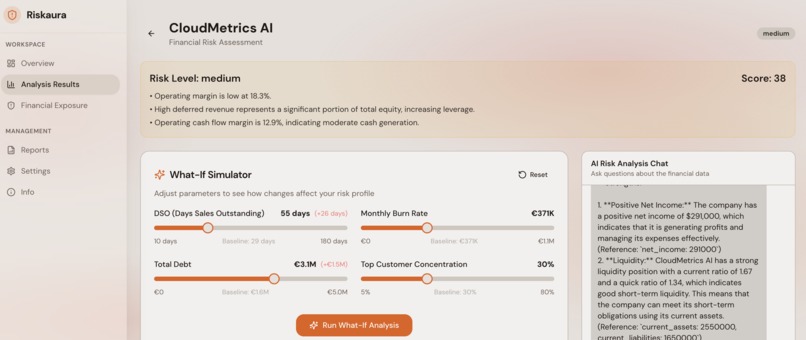
Analytics Screen Preview
-
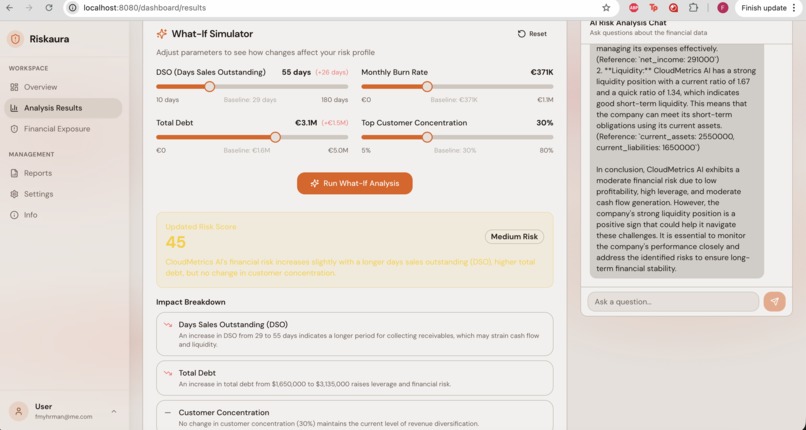
Feature: "What-If", Adjustable sliders for scenario monitoring



About Riskaura
Inspiration: Access to credit remains one of the biggest barriers for small and medium enterprises (SMEs). Traditional underwriting is slow, opaque, and expensive. We wanted to build a tool that democratizes financial risk assessment, thus making it transparent, instant, and accessible to anyone with a set of financial documents.
What It Does: Riskaura lets users upload financial statements (income statements, balance sheets, cash flow reports, even PDFs) and instantly generates the following:
- Structured financial extraction via AI
- Automated risk scoring across five dimensions: profitability, liquidity, leverage, efficiency, and cash flow
- Interactive what-if simulations to model scenarios like revenue changes or debt restructuring
- Conversational AI chat for deeper analysis
- The overall risk score is derived from a weighted combination of individual risk dimensions (profitability, liquidity, leverage, efficiency, cash flow) scored on a 0–100 scale.
How We Built It: Frontend: React + TypeScript + Tailwind CSS + Recharts for data visualization Backend: Lovable Cloud with Edge Functions for serverless AI processing AI: Lovable AI (Gemini) for document extraction, risk assessment, what-if analysis, and conversational chat PDF Processing: pdfjs-dist for client-side PDF text extraction before sending to AI Caching: Content-hash-based deduplication. Re-uploading the same documents returns cached results instantly
Challenges: Structured extraction from unstructured documents. Financial statements come in wildly different formats. We iterated heavily on the extraction prompt to handle edge cases like multi-language documents, varying period formats (monthly/quarterly/annual), and summary rows that shouldn't be treated as separate periods. Merging multi-document data. When users upload separate files (e.g., income statement + balance sheet), the AI analyzes each independently and we merge results by matching periods, a non-trivial alignment problem. Reliable JSON from LLMs. Getting consistent, valid JSON from language models required careful prompt engineering, markdown fence stripping, and defensive parsing. Credit management. Balancing AI quality vs. cost by choosing appropriate model tiers and caching aggressively to avoid redundant API calls.
What We Learned: Prompt engineering is as much about constraining output as enabling it Client-side PDF extraction dramatically reduces backend load and latency Content-hash caching is a simple but powerful pattern for AI-heavy applications Transparent methodology builds trust. Our Info page explains every metric so users understand why they got a particular score
Built With
- gemini-ai
- lovable-ai
- lovable-cloud
- pdfjs-dist
- react
- react-router
- recharts
- shadcn/ui
- supabase-edge-functions
- tailwind-css
- typescript
- vite
- zod
- zustand

Log in or sign up for Devpost to join the conversation.