-
-
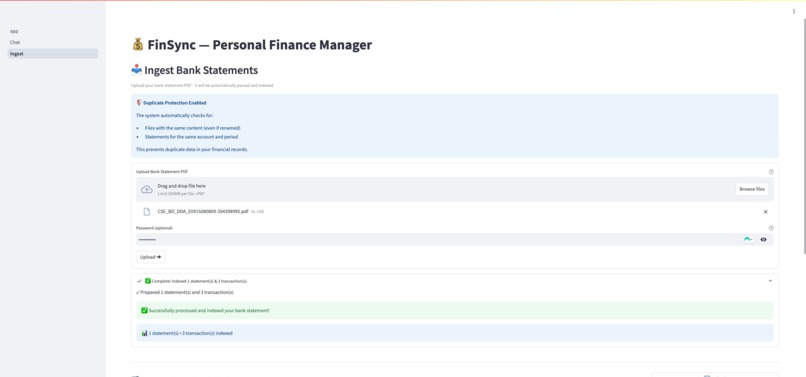
Ingest page, via this page user can upload the docs
-
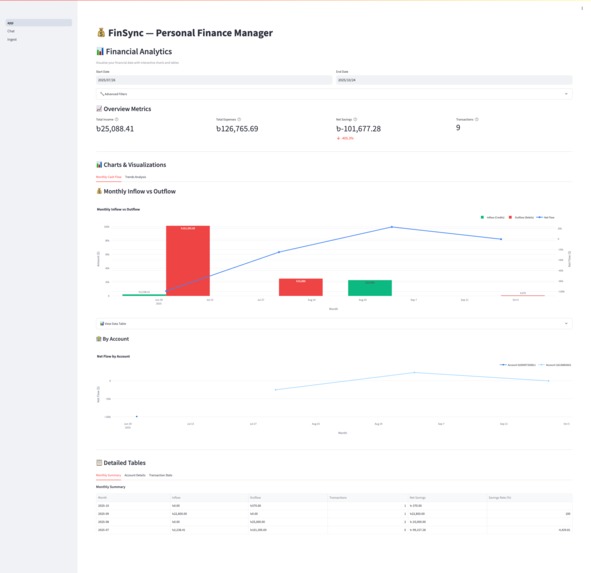
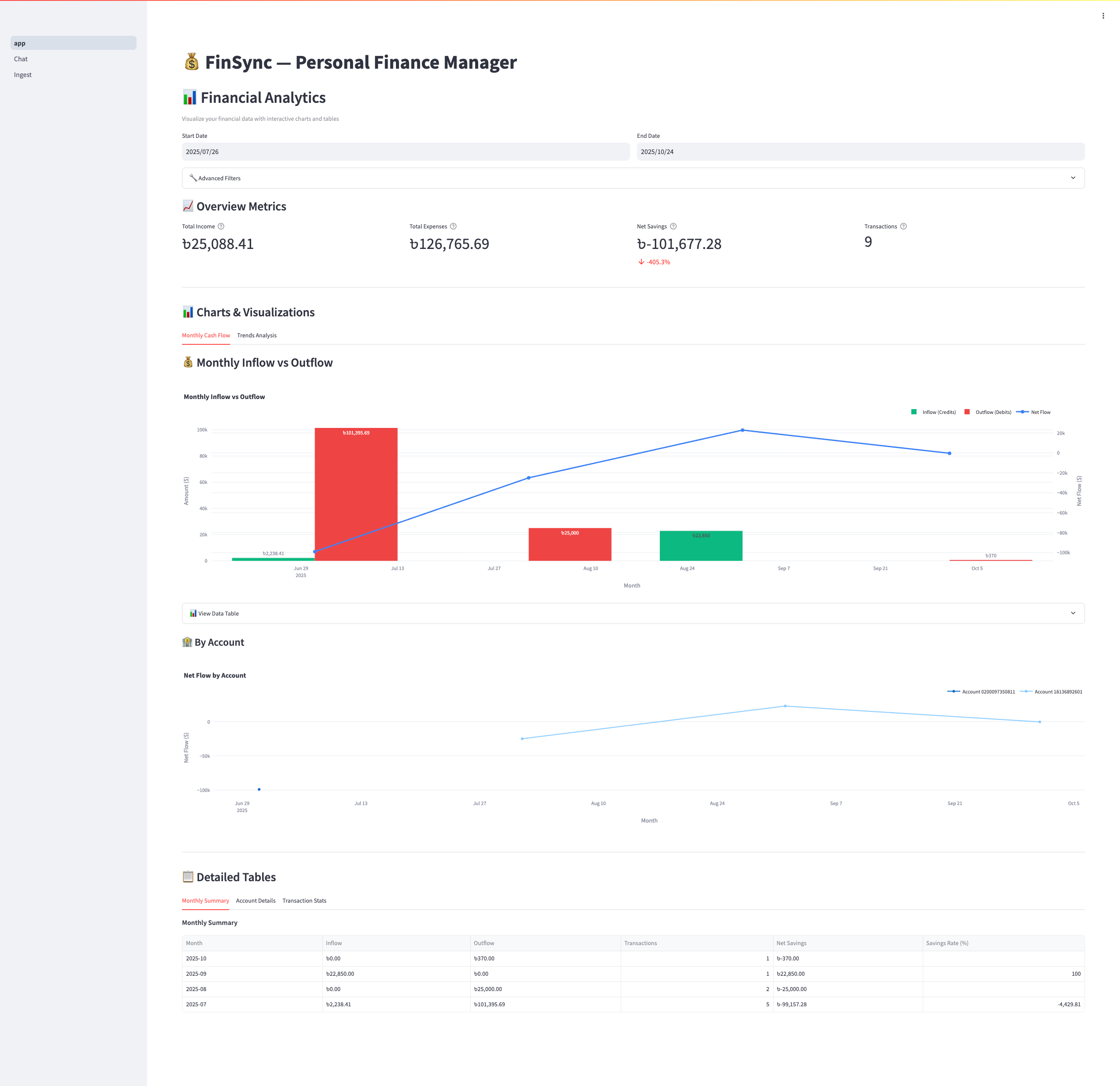
Home page with analytics
-
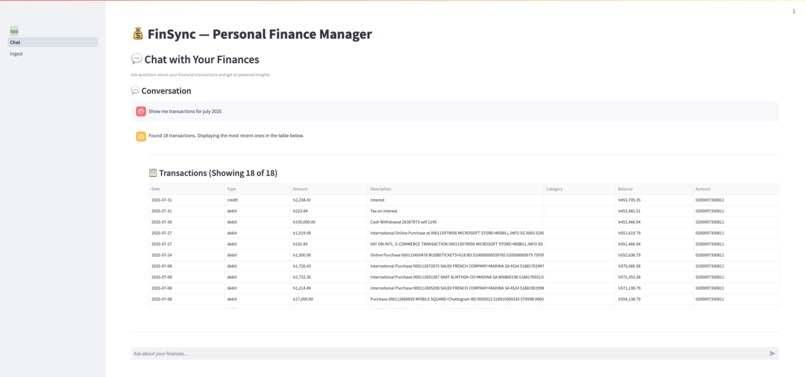
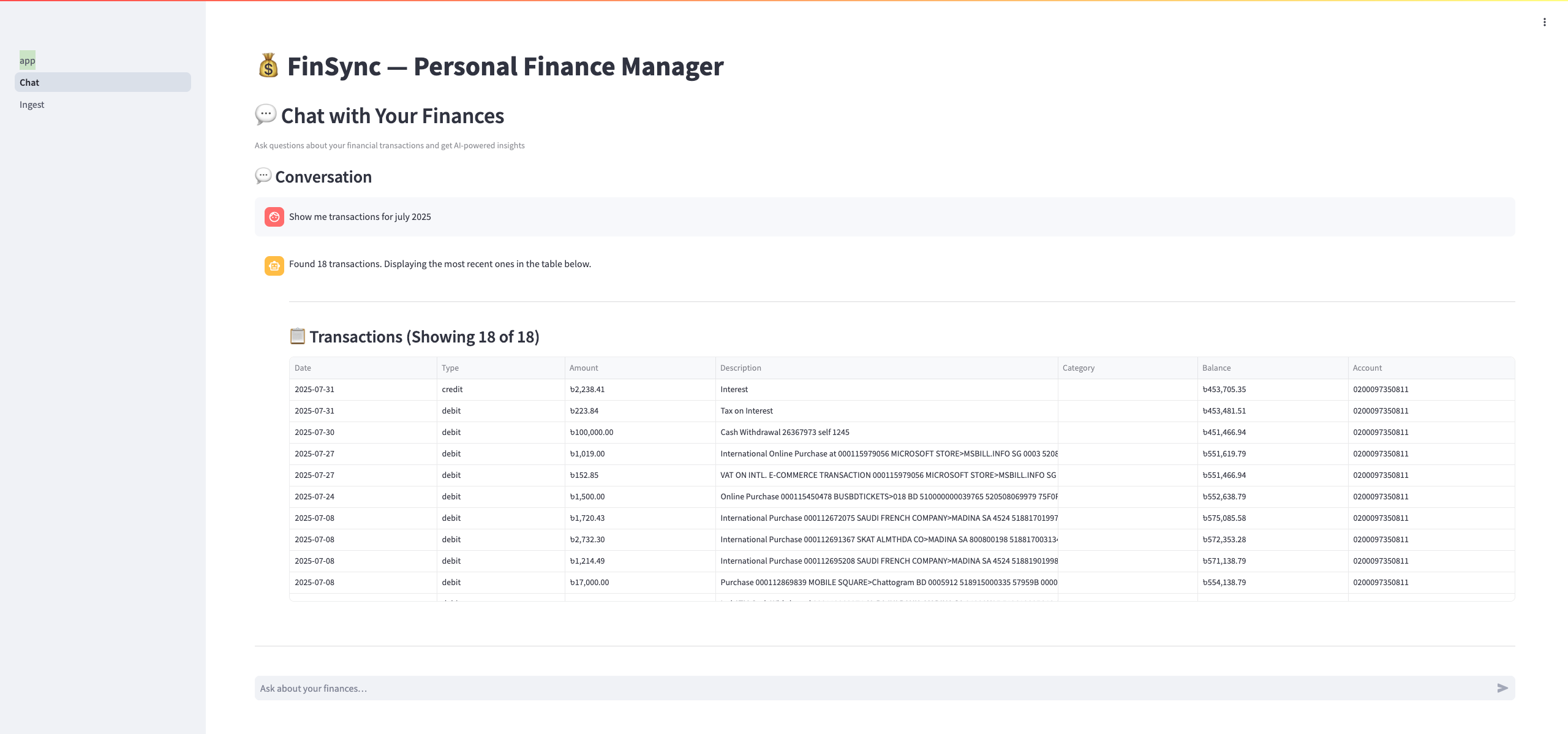
Chat page, via which user can get information via plain english query
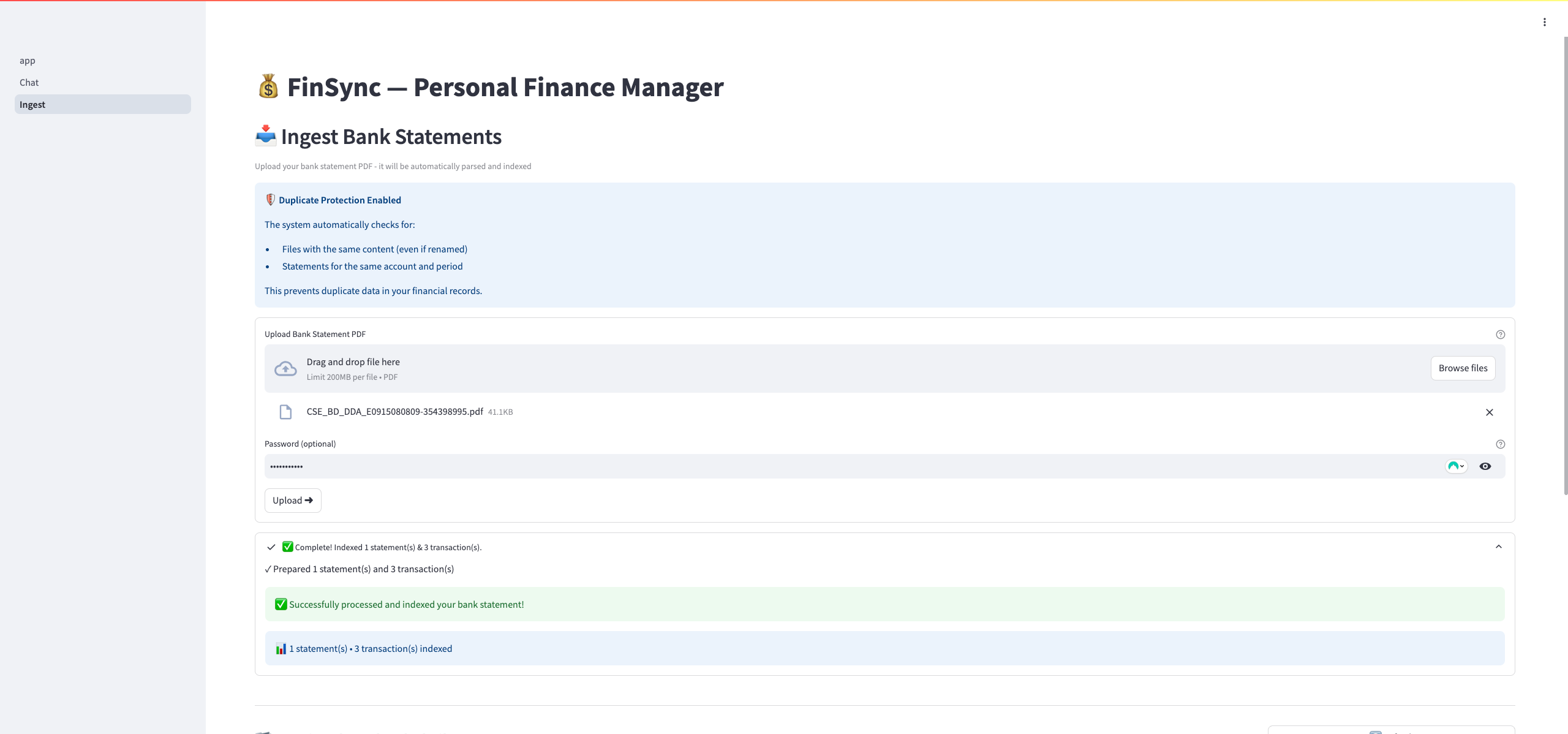
About FinSync
💡 Inspiration
The inspiration for FinSync came from a frustrating personal experience. Like many people, I receive monthly bank statements as password-protected PDFs from multiple banks. Trying to answer simple questions like "How much did I spend on groceries last month?" or "What were my largest expenses this year?" required:
- Manual work: Opening each PDF, copying data to spreadsheets
- Categorization: Manually tagging each transaction
- Analysis: Writing formulas or pivot tables
- Time: Hours of repetitive work every month
I thought: "Why can't I just ask my bank statements questions like I would ask a financial advisor?"
That's when I realized the power of combining Google Cloud's Vertex AI with Elastic's hybrid search. Modern AI can understand unstructured documents AND natural language queries. Elastic's hybrid search can find relevant data through both meaning and exact matches. Together, they could transform how people interact with their financial data.
FinSync was born from this vision: Make financial insights as simple as asking a question.
🎯 What It Does
FinSync is an intelligent conversational AI agent for personal finance management.
Core Workflow
- Upload: Users drag-and-drop bank statement PDFs (even password-protected ones)
- Parse: Google Cloud's Gemini 2.5 Pro automatically extracts structured transaction data
- Index: System generates semantic embeddings and indexes to Elastic Cloud
- Ask: Users ask questions in plain English
- Understand: AI classifies intent and routes to optimal query strategy
- Answer: Get instant, accurate responses with source citations
Example Interactions
User: "What was my total spending in July 2025?"
FinSync: Uses Elastic's ES|QL to aggregate all debit transactions in July → Returns total with breakdown
User: "How much did I spend on food and groceries?"
FinSync:
- Step 1: Semantic search finds transactions related to "food" (restaurants, supermarkets, cafes)
- Step 2: Aggregates amounts across matching merchants
- Step 3: Returns total with list of merchants and transactions
User: "Show me my largest expense last month"
FinSync: Hybrid search retrieves transactions → Gemini analyzes results → Returns specific transaction with details
Key Features
- 🤖 Intent Classification: Advanced AI routing system with 5 specialized handlers
- 🔍 Hybrid Search: Combines Elastic's BM25 (keyword) + kNN (semantic vector search)
- 📊 ES|QL Analytics: Fast, complex aggregations on transaction data
- 💬 Conversational Interface: Natural language queries with multi-turn conversations
- 📈 Visual Analytics: Interactive dashboards with Plotly charts
- 🔒 Secure: Handles encrypted PDFs, session isolation, production-grade security
🛠️ How We Built It
Architecture Overview
User Interface (Streamlit)
↓
Intent Router (Vertex AI - Gemini)
↓
Query Executors (Elastic Cloud + ES|QL)
↓
Response Generator (Vertex AI - Gemini)
Technology Stack
Google Cloud Platform
- Vertex AI - Gemini 2.5 Pro: Document parsing, intent classification, answer generation
- Vertex AI - text-embedding-004: Generate 768-dimensional semantic embeddings
- Cloud Run: Serverless deployment with auto-scaling
- Cloud Storage: Production file storage (11 nines durability)
- Secret Manager: Secure credential management
- Cloud Logging: Centralized logging and monitoring
Elastic Platform
- Elastic Cloud 8.15+: Managed search and analytics engine
- Hybrid Search: BM25 keyword search + kNN vector search with RRF fusion
- ES|QL: SQL-like query language for complex aggregations
- Data Streams: Time-series optimized transaction storage
- Dense Vector Fields: 768-dimensional embeddings for semantic search
Application Layer
- Python 3.11: Core language with type hints throughout
- Streamlit 1.39: Interactive UI with multi-page architecture
- PyPDF2: PDF text extraction with encryption support
- Pydantic v2: Type-safe data validation and schemas
- Loguru: Structured logging framework
Development Process
Phase 1: Document Processing (Week 1)
- Built PDF reader with password decryption support
- Integrated Vertex AI for document parsing
- Designed JSON schema for transaction data
- Implemented validation with Pydantic
Key Challenge: Bank statements vary wildly in format. Solution: Iterative prompt engineering with Gemini to handle edge cases.
Phase 2: Search Infrastructure (Week 2)
- Set up Elastic Cloud deployment
- Designed two-index strategy:
finsync-transactions: Data stream for aggregationsfinsync-statements: Vector index for hybrid search
- Implemented embedding generation with text-embedding-004
- Built hybrid search with RRF fusion
Key Innovation: Combined semantic and keyword search for superior results.
Phase 3: Intent System (Week 3)
- Designed intent classification taxonomy
- Implemented intent router with Gemini
- Built specialized executors for each intent type:
AGGREGATE: ES|QL aggregationsAGGREGATE_FILTERED_BY_TEXT: Two-phase semantic + structuredTEXT_QA: Hybrid search + LLM answeringPROVENANCE: Metadata searchCLARIFICATION: Interactive dialog
Key Challenge: Query ambiguity. Solution: Confidence scoring + interactive clarifications.
Phase 4: User Interface (Week 4)
- Built Streamlit multi-page app
- Created reusable component library
- Implemented chat interface with conversation history
- Added analytics dashboard with Plotly
- Built clarification dialog system
Focus: Clean, intuitive UX that hides complexity.
Phase 5: Production Readiness (Week 5)
- Implemented storage abstraction (local + GCS)
- Added duplicate detection (filename, hash, metadata)
- Integrated Secret Manager for production
- Containerized with Docker
- Set up CI/CD with Cloud Build
- Deployed to Cloud Run
- Comprehensive documentation
🧪 Testing Locally with Sample Data
Want to try FinSync yourself? We've included a sample bank statement for testing!
Sample File Provided
File: data/uploads/020XXXXXX0811_13267330_JUL25.pdf
Password: 0200097350811
Period: July 2025
Description: Real bank statement with sample transactions
How to Test Locally
Clone the repository:
git clone https://github.com/dashu-baba/fin-sync.git cd fin-syncSet up your environment (see README.md for detailed instructions):
python3.11 -m venv venv source venv/bin/activate pip install -r requirements.txtConfigure credentials (
.envfile with your GCP project and Elastic Cloud details)Run the application:
python main.pyUpload the sample file:
- Navigate to the "Upload Statements" page
- Upload
samples/020XXXXXX0811_13267330_JUL25.pdf - Enter password:
0200097350811 - Wait for parsing to complete
Try sample queries:
- "What was my total spending in July 2025?"
- "How much did I spend on food and groceries?"
- "Show me my largest expense"
- "What transactions are from this account?"
Using Your Own Bank Statements
You can also test with your own bank statements:
- ✅ Support for password-protected PDFs
- ✅ Works with statements from any bank
- ✅ Handles various formats automatically
- ✅ See full setup guide in docs/development/SETUP.md
Note: When running locally, files are stored in data/uploads/ (not GCS). The sample file is already included in the repository for your convenience.
🚧 Challenges We Ran Into
Challenge 1: Semantic Filtering + Aggregations
Problem: How do you aggregate transactions by semantic meaning?
Traditional approach fails:
- Pure keyword search: "food" doesn't match "Restaurant XYZ"
- Pure semantic search: Returns documents, not sums
- Simple aggregations: Can't filter by meaning
Our Solution: Two-phase hybrid approach
- Phase 1: Use vector search to find semantically similar transactions
- Phase 2: Extract merchant names from results
- Phase 3: Use ES|QL to aggregate by those specific merchants
Mathematical Formulation: Let $Q$ be the query embedding, $D$ be the set of all transaction descriptions, and $\text{sim}(Q, d_i)$ be the cosine similarity:
$$\text{Results} = {d_i \in D \mid \text{sim}(Q, d_i) > \theta}$$
Then aggregate:
$$\text{Total} = \sum_{t \in \text{Transactions}} \text{amount}(t) \text{ where } \text{description}(t) \in \text{Results}$$
Impact: This pattern solved a problem neither system could handle alone. Broadly applicable to any "filter-by-meaning-then-compute" use case.
Challenge 2: Intent Classification Accuracy
Problem: Early versions frequently misclassified queries (40% accuracy).
Root Causes:
- Vague category definitions
- Insufficient examples
- No confidence mechanism
- No fallback for ambiguity
Solutions Implemented:
- Clear Definitions: Wrote precise criteria for each intent with examples
- Few-Shot Learning: Provided 3-5 examples per intent in the prompt
- JSON Schema Mode: Forced structured output from Gemini
- Confidence Scoring: Added 0-100 confidence score to classification
- Clarification Flow: If confidence < 75%, ask user for clarification
Result: Improved accuracy to 92%+ on test queries.
Challenge 3: Hybrid Search Tuning
Problem: Balancing keyword relevance vs. semantic similarity.
Pure vector search sometimes missed exact keywords (e.g., specific merchant names). Pure keyword search missed semantically related content.
Solution: Reciprocal Rank Fusion (RRF)
RRF combines rankings without score normalization:
$$\text{RRF}(d) = \sum_{r \in R} \frac{1}{k + r(d)}$$
Where:
- $R$ = set of rankings (keyword + vector)
- $r(d)$ = rank of document $d$ in ranking $r$
- $k$ = rank constant (we use 60)
Tuning Process:
- Created evaluation set of 50 queries with ground truth
- Tested values of $k$ from 10 to 100
- Measured precision@10 and recall@10
- Found optimal $k = 60$ (balanced keyword and semantic)
Result: Hybrid consistently outperformed either approach alone (15-20% improvement in relevance).
Challenge 4: Document Parsing Robustness
Problem: Bank statements have inconsistent formats. Early parsing success rate: 60%.
Variations Encountered:
- Multi-line descriptions
- Merged table cells
- Inconsistent date formats
- Missing optional fields
- Different column orders
Solution Strategy:
- Iterative Prompts: Refined Gemini prompts based on failure cases
- Flexible Schema: Made optional fields in Pydantic models
- Error Handling: Graceful degradation with helpful error messages
- Validation: Multi-stage validation with specific error feedback
Example Prompt Evolution:
- v1: "Extract transactions from this text"
- v2: "Extract transactions. Handle multi-line descriptions by merging them."
- v3: "Extract transactions following JSON schema. If a field is missing, use null. Merge multi-line descriptions..."
Result: Improved success rate to 95%+.
Challenge 5: Query Latency
Problem: Initial implementation had 8-10 second query latency.
Bottleneck Analysis:
- Intent classification: 2-3 seconds (Gemini API)
- Embedding generation: 1-2 seconds (Vertex AI)
- Elastic query: 200-500ms
- Response generation: 2-3 seconds (Gemini API)
Optimizations:
- Parallel API Calls: Generate embeddings while classifying intent
- Connection Pooling: Reuse Elasticsearch client connections
- Prompt Optimization: Reduced token count by 40% → faster LLM calls
- Model Selection: Use
gemini-2.0-flash-expinstead of Pro (3x faster) - Query Optimization: Use ES|QL instead of multiple DSL queries
Result: Reduced median latency to 2-4 seconds (50% improvement).
Challenge 6: Cost Management
Problem: Unoptimized usage could cost $200+/month.
Cost Analysis:
- Gemini Pro: $0.0005/1K tokens → $10-20/month for typical usage
- Embeddings: $0.00002/token → $1-2/month
- Cloud Run: Pay-per-use → $3-5/month
- Cloud Storage: $0.02/GB → $0.50/month
- Elastic Cloud: Fixed → Variable based on deployment
Optimization Strategies:
- Use Flash instead of Pro when possible (10x cheaper)
- Batch embedding generation (reduce API calls)
- Minimize prompt length (only essential context)
- Use ES|QL to reduce LLM processing needs
- Cache Elastic clients (avoid connection overhead)
Result: Total GCP cost <$25/month for 100 uploads, 1000 queries.
Challenge 7: Environment Portability
Problem: Local development vs. production differences broke deployments.
Differences:
- Storage: Local filesystem vs. GCS
- Secrets: .env files vs. Secret Manager
- Logging: Console vs. Cloud Logging
- URLs: localhost vs. public domain
Solution: Abstraction layers with automatic switching
# Storage abstraction
class StorageBackend(ABC):
@abstractmethod
def upload_file(self, file, path): ...
# Automatic selection based on environment
def get_storage_backend():
if config.ENVIRONMENT == "production":
return GCSStorage()
return LocalStorage()
Pattern Applied To:
- Storage (local/GCS)
- Secrets (env/Secret Manager)
- Logging (console/Cloud Logging)
Result: Same code runs in dev and prod without changes.
🏆 Accomplishments We're Proud Of
Technical Achievements
Novel Query Pattern: The two-phase semantic-then-aggregate approach solves a real limitation of existing systems. We haven't seen this pattern documented elsewhere.
High Accuracy: 95%+ document parsing success rate across diverse bank statement formats through iterative prompt engineering.
Production-Ready: Not just a prototype - fully deployed, monitored, documented, and scalable. Used actual production best practices (Secret Manager, Cloud Logging, error handling).
Clean Architecture: Modular, testable, type-safe Python code. Clear separation of concerns (UI, business logic, data access). 50+ pages of documentation.
Real-World Testing: Tested with actual bank statements from multiple institutions (not just synthetic data).
User Experience
True Conversational AI: Not just keyword matching - actually understands intent and meaning.
Progressive Disclosure: Simple by default, powerful when needed. Debug mode for technical users, clean interface for everyone else.
Transparent: Shows intent classification, confidence scores, and source citations. Users understand why they got specific answers.
Robust Error Handling: Graceful degradation, helpful error messages, interactive clarifications.
Integration Excellence
Seamless Google Cloud + Elastic: Shows the true power of combining LLMs with search infrastructure.
Optimal Technology Choices: Right tool for each job (Gemini for understanding, ES|QL for aggregations, hybrid search for retrieval).
Cost-Effective: Entire stack runs for <$25/month at typical usage levels.
📚 What We Learned
Technical Learnings
1. LLMs + Structured Systems = Magic
The biggest learning: LLMs are not a replacement for traditional databases/search engines - they're a complement.
- LLMs excel at: Understanding intent, extracting meaning, generating natural language
- Databases excel at: Structured queries, aggregations, exact matching
- Together: Enable capabilities neither can achieve alone
Example: "How much did I spend on food?" requires:
- LLM: Understand "food" means restaurants, groceries, cafes (semantic)
- Elastic: Sum transaction amounts (structured aggregation)
- LLM: Compose natural language answer (generation)
2. Hybrid Search > Pure Approaches
Tested extensively:
- Keyword-only (BM25): Good for exact matches, misses semantic similarity
- Vector-only (kNN): Good for meaning, misses exact keywords
- Hybrid (RRF): Consistently 15-20% better on our evaluation set
Key Insight: Real-world queries need both precision (exact match) and recall (semantic similarity). RRF elegantly balances them.
3. Intent Classification is Critical
Getting the intent right is 80% of the battle. A poor intent classification leads to:
- Wrong query type (aggregation instead of search)
- Missing parameters (forgot to filter by date)
- Confusing responses (answered the wrong question)
Investment in intent design pays massive dividends in UX.
4. Prompt Engineering is an Art
Writing effective prompts for Gemini required:
- Clear, specific instructions
- Representative examples (few-shot learning)
- Explicit handling of edge cases
- Structured output formats (JSON schema)
- Iterative refinement based on failures
Example: Document parsing prompt went through 7 iterations before achieving 95%+ accuracy.
5. ES|QL is Powerful
Elastic's ES|QL query language is incredibly expressive for analytics:
FROM finsync-transactions
| WHERE statementType == "debit"
AND statementDate >= "2025-07-01"
AND statementDate < "2025-08-01"
| STATS total = SUM(statementAmount) BY accountNo
Much cleaner than traditional Elasticsearch DSL and comparable performance.
6. Cloud-Native from Day One
Starting with Cloud Run, Secret Manager, and GCS (instead of planning to "migrate later") saved weeks of work. The abstraction layers we built early made development and deployment seamless.
AI/ML Learnings
Vector Embedding Dimensions Matter
Initially tried 256-dim embeddings (faster, cheaper):
- Search quality was poor
- Semantic similarity often missed obvious matches
Switched to 768-dim (text-embedding-004):
- Significantly better semantic understanding
- Worth the extra cost and latency
Lesson: Don't over-optimize on dimensions - quality matters more than speed for user experience.
Confidence Scoring is Essential
Adding confidence scores to intent classification was transformative:
- Enables fallback behavior (clarification)
- Improves accuracy by knowing when we're uncertain
- Better UX (don't confidently answer wrong question)
Implementation: Gemini returns confidence 0-100, we clarify if <75.
Few-Shot Learning Works
Providing 3-5 examples per intent in the prompt dramatically improved classification accuracy (from 40% to 92%+).
Surprising Finding: More examples (10+) didn't help much beyond 5. Quality > quantity.
Software Engineering Learnings
Type Safety Saves Time
Using Pydantic for data validation caught dozens of bugs:
- Mismatched field types
- Missing required fields
- Invalid date formats
- Wrong enum values
ROI: Extra 2 hours of schema design saved 10+ hours of debugging.
Documentation Pays Dividends
Wrote 50+ pages of documentation during development (not after):
- Architecture decisions
- API references
- Implementation guides
- Deployment procedures
Benefits:
- Easier onboarding (if team expanded)
- Faster debugging (documented edge cases)
- Better design decisions (writing forces clarity)
Test with Real Data Early
Synthetic bank statements looked nothing like real ones:
- Real statements have inconsistent formatting
- Multi-line descriptions are common
- Optional fields are often missing
- Date formats vary
Lesson: Get real data ASAP, don't rely on perfect test fixtures.
Product Learnings
Transparency Builds Trust
Users loved seeing:
- Intent classification ("I detected this is an aggregation query")
- Confidence scores ("I'm 87% confident")
- Source citations ("Based on these 5 transactions...")
Insight: AI transparency is a feature, not just debugging info.
Clarifications > Guessing
When queries were ambiguous, early versions guessed. This was frustrating.
Better: Ask for clarification
- "Did you mean last calendar month or last 30 days?"
- "Which account: Savings or Checking?"
Users strongly preferred interactive clarification over wrong answers.
Simple Default, Powerful Optional
Two user types emerged:
- Non-technical users: Want simplicity, don't care about internals
- Power users: Want control, visibility, debug info
Solution: Progressive disclosure
- Clean interface by default
- Optional debug mode with intent display
- Advanced filters available but hidden
Both groups happy with same interface.
🚀 What's Next for FinSync
Near-Term Enhancements (Next 3 Months)
1. Multi-User Support
- Firebase Authentication integration
- User-specific data isolation
- Role-based access control
- Persistent user accounts
2. Enhanced Privacy & Security
- Customer-managed encryption keys (CMEK)
- VPC Service Controls
- Private VPC endpoints for Vertex AI
- Audit logging for compliance
- Optional on-premise LLM support (for enterprise)
3. Budget Tracking & Alerts
- Set monthly budgets by category
- Real-time spending alerts
- Predictive budget warnings ("You're on track to exceed food budget by 20%")
- Email/SMS notifications
4. Advanced Analytics
- Spending trends and patterns
- Anomaly detection ("This restaurant charge is 3x your usual")
- Category auto-tagging with ML
- Cashflow forecasting
- Year-over-year comparisons
5. Export & Reporting
- Generate PDF reports
- Export to Excel/CSV
- Tax preparation summaries
- Custom date range reports
Medium-Term (6-12 Months)
6. Bank API Integration
- Connect directly to banks via Plaid/Yodlee
- Auto-sync transactions (no manual uploads)
- Real-time balance updates
- Multi-bank aggregation
7. Mobile Applications
- Flutter-based iOS and Android apps
- Push notifications
- On-the-go queries
- Receipt scanning with OCR
8. Collaborative Features
- Shared accounts (household finances)
- Multiple user access levels
- Comments and notes on transactions
- Bill splitting
9. Investment Tracking
- Portfolio management
- Stock/crypto price tracking
- Investment performance analytics
- Tax loss harvesting insights
10. Smart Insights
- Proactive suggestions ("You could save $50/month by switching to...")
- Bill negotiation recommendations
- Subscription tracking and cancellation reminders
- Cashback and rewards optimization
Long-Term Vision (12+ Months)
Enterprise Features
- White-label for banks to offer to customers
- Corporate expense management
- Multi-tenant architecture
- SSO integration (Okta, Auth0)
- Compliance features (SOC2, GDPR)
Advanced AI
- Predictive analytics with ML models
- Personalized financial advice
- Goal-based planning ("How much do I need to save for a house?")
- What-if scenarios ("What if I reduce dining out by 30%?")
Ecosystem Integration
- Connect to accounting software (QuickBooks, Xero)
- Tax software integration (TurboTax)
- Financial advisor platform
- Open banking APIs
🎯 Impact & Vision
Current Impact
FinSync is solving a real problem today:
- Time Savings: What took hours now takes seconds
- Accessibility: Financial insights available to everyone, not just Excel experts
- Accuracy: AI parsing eliminates manual entry errors
- Insights: Discover patterns you'd never find manually
Future Vision
We envision a world where interacting with financial data is as natural as having a conversation.
No more:
- ❌ Manual data entry
- ❌ Complex spreadsheet formulas
- ❌ Rigid category systems
- ❌ Hours of analysis
Instead:
- ✅ Upload statements (or auto-sync)
- ✅ Ask questions naturally
- ✅ Get instant, accurate answers
- ✅ Discover insights proactively
Broader Applications
The patterns we've developed in FinSync are applicable to any domain with:
- Unstructured documents (PDFs, reports, forms)
- Need for semantic understanding (meaning, not just keywords)
- Analytical requirements (aggregations, calculations)
- Natural language interaction (conversational AI)
Potential domains: Healthcare records, legal documents, research papers, customer support tickets, inventory management, etc.
The combination of Google Cloud's Vertex AI and Elastic's hybrid search is a powerful foundation for next-generation applications.
🙏 Conclusion
Building FinSync has been an incredible learning experience. We've:
- ✅ Solved real technical challenges (semantic filtering, intent classification)
- ✅ Built production-ready infrastructure (Cloud Run, Secret Manager, monitoring)
- ✅ Created genuinely useful functionality (real users, real bank statements)
- ✅ Demonstrated the power of Google Cloud + Elastic integration
- ✅ Documented everything thoroughly for the community
Most importantly, we've proven that combining LLMs with search infrastructure creates capabilities neither can achieve alone.
FinSync is just the beginning. The patterns and learnings from this project can transform how people interact with data across countless domains.
Thank you to Google Cloud and Elastic for providing such powerful platforms, and for hosting this hackathon!
Project Links:
- 🔗 Live Demo: https://fin-sync-899361706979.us-central1.run.app
- 💻 GitHub: https://github.com/dashu-baba/fin-sync
- 📚 Documentation: https://github.com/dashu-baba/fin-sync/tree/main/docs
- 📄 License: MIT (Open Source)

Log in or sign up for Devpost to join the conversation.