-
-

Thumbnail
-
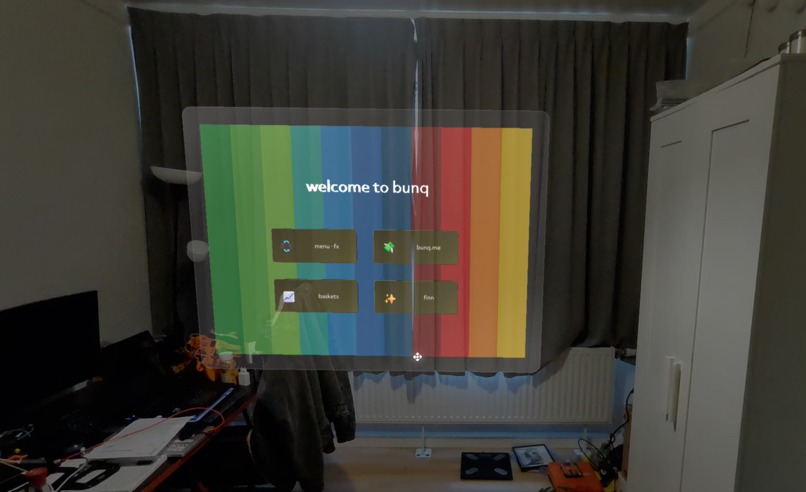
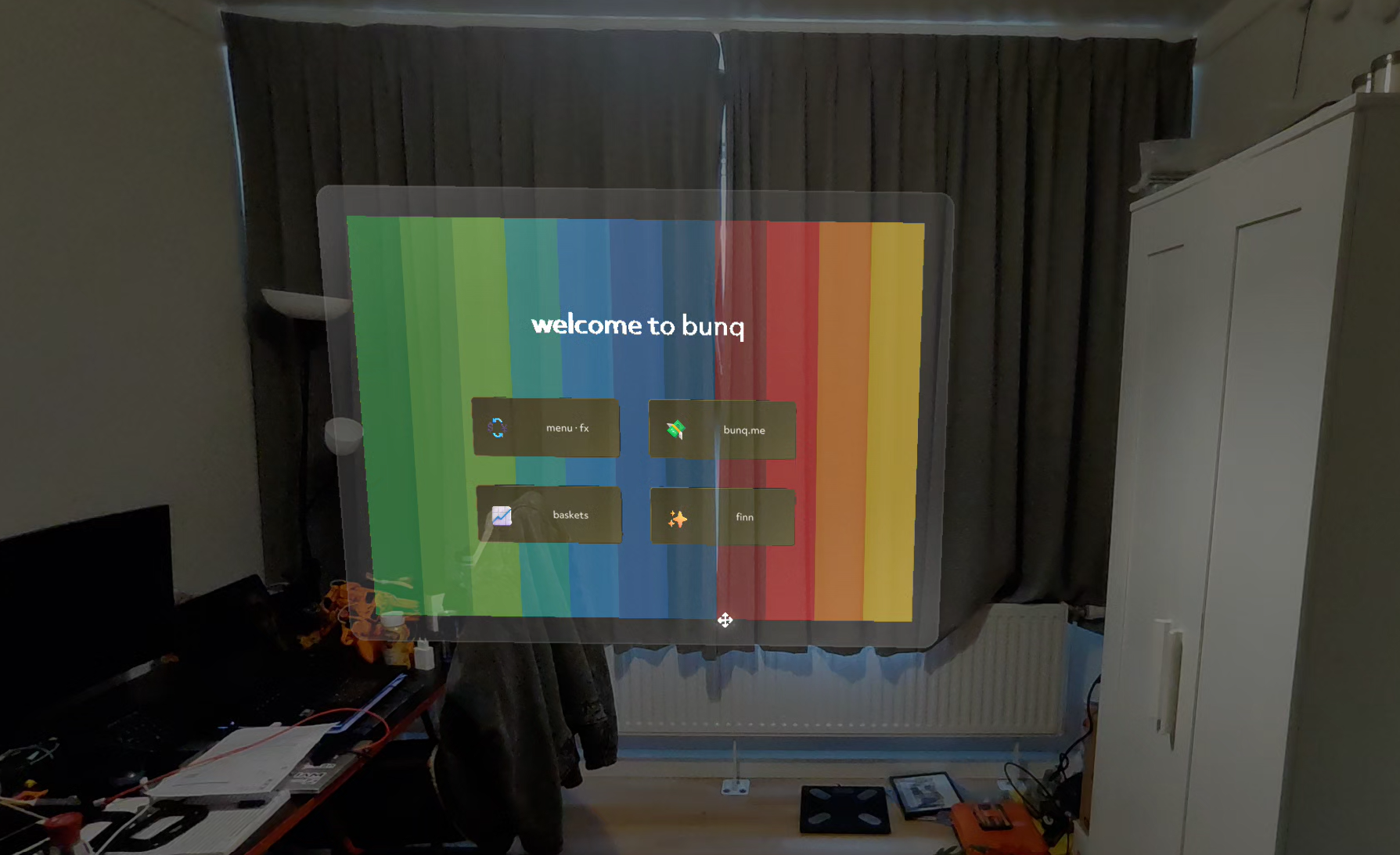
Main landing page
-
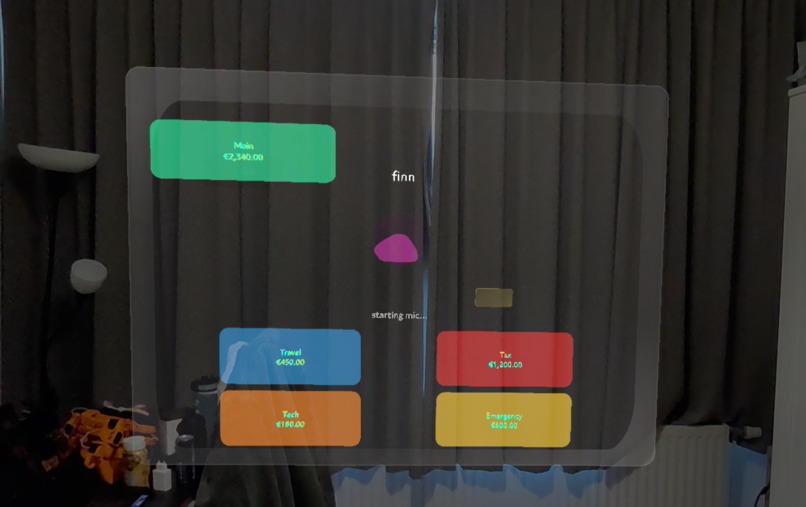
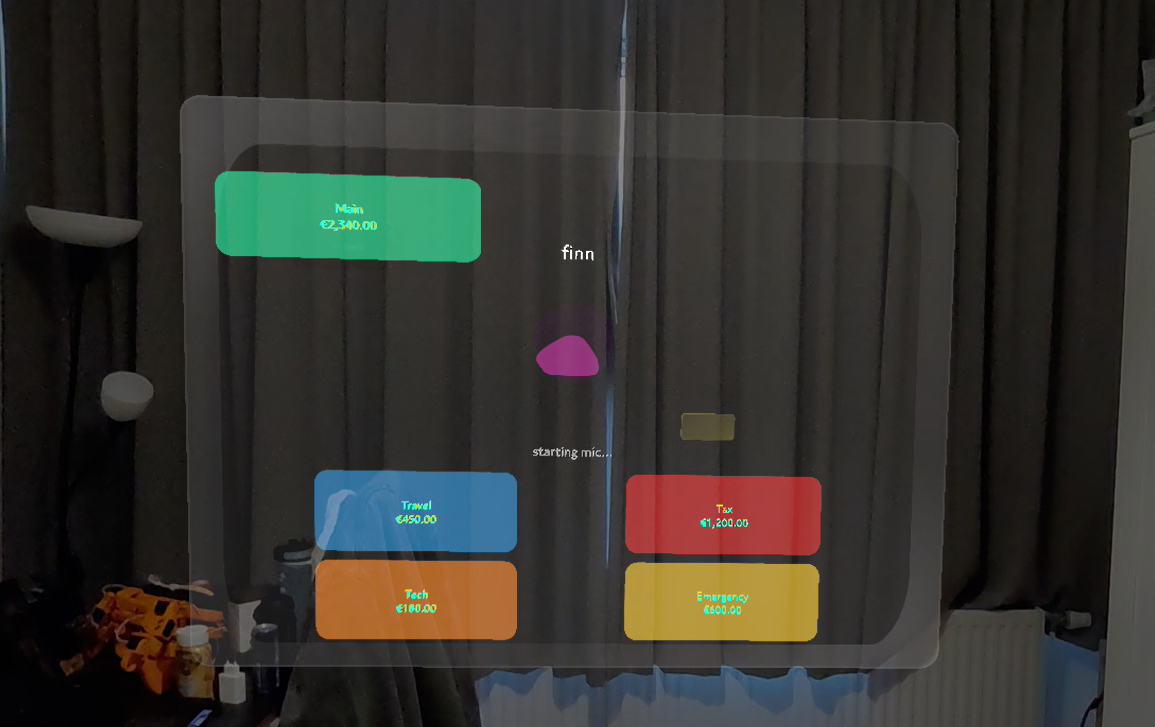
Finn overview with account info
-
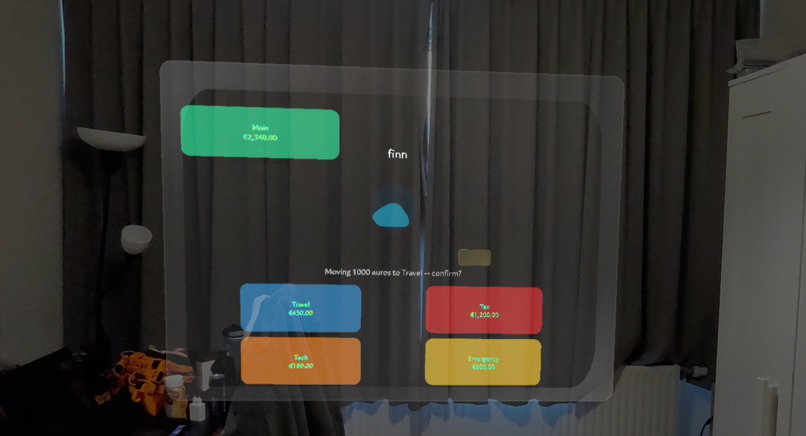
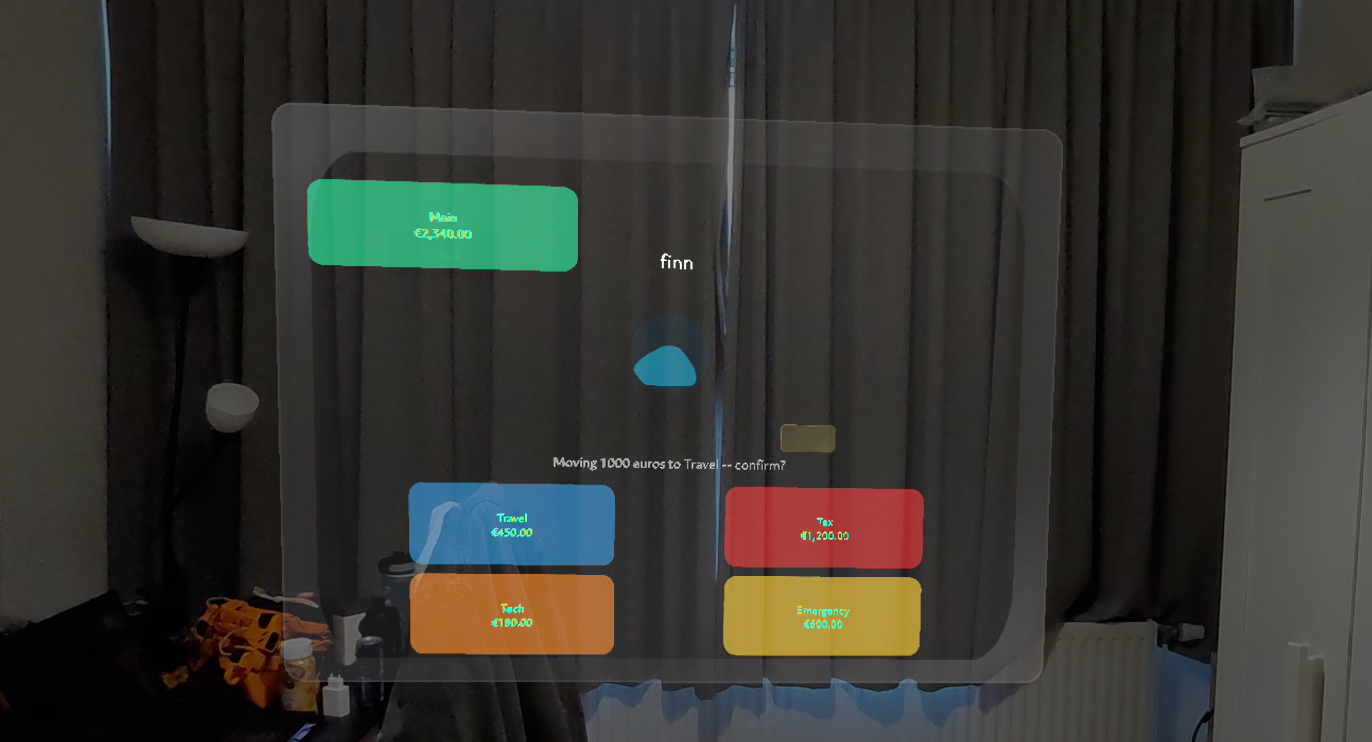
Confirmation of transfer
-
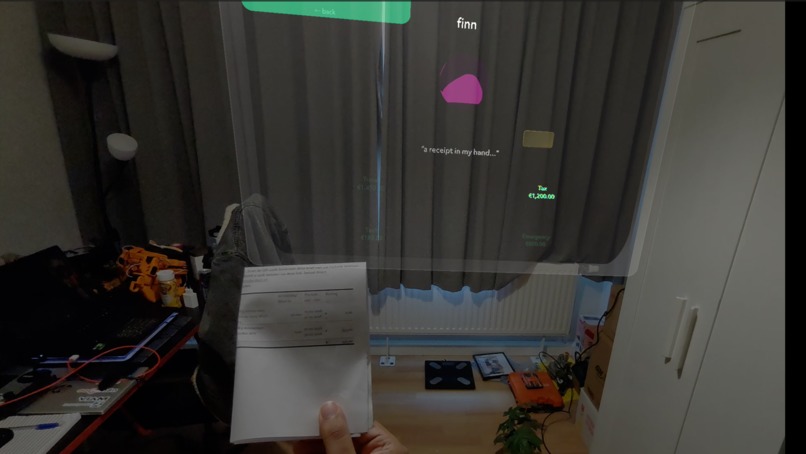
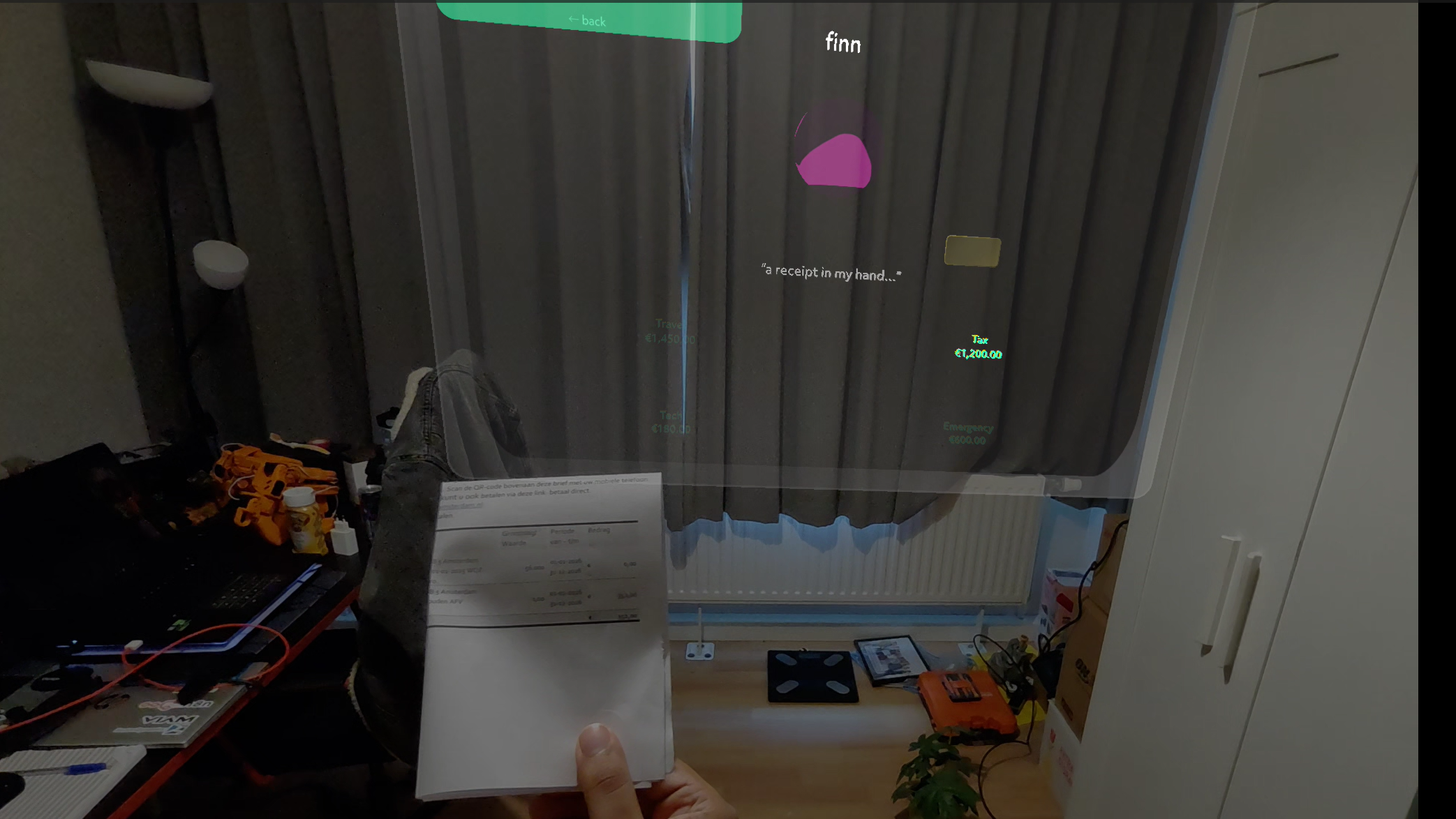
Computer vision for automatically reading receipts

Inspiration
bunq's December 2025 update shipped Finn, a multimodal AI agent that already handles ~97% of customer support across 35 languages, with image recognition and speech-to-speech translation. But Finn lives inside a phone — and bunq's actual user, the location-independent professional (digital nomads, expats, cross-border SMEs), almost never has their hands free. They're carrying luggage, a passport, sometimes a child, and crossing a currency border every week.
Our pitch line:
bunq already built the AI agent for 20M borderless users. It's trapped in a phone. We put it where your eyes are.
Every concept we built is grounded in bunq's real 2026 direction (Updates 30 and 31) — no sci-fi, just existing Finn capabilities given a body through Snap Spectacles.
What it does
A heads-up "welcome to bunq" hub, world-locked 1.2 m in front of you, with four feature surfaces accessed via pinch gestures:
We were not able to implement all features for this round but focused on implementing Finn.
- menu · fx — Look at a foreign menu, prices overlay in your home currency. (Pending)
- bunq.me — Glance at a friend's QR, voice-pay in any currency. (Pending)
- baskets — Investment portfolios as floating spatial cards. (Pending)
- finn — A breathing orb that listens, sees, and moves money on confirmation.
The Finn screen is the headline: voice → GPT-4o → typed intent → confirm-gated transfer → mock ledger update → Sasha speaks back. Plus camera scan: point at a receipt, GPT-4o vision categorizes it into the right basket.
How we built it
Stack. Lens Studio 5.15.3, Snap Spectacles (2024), TypeScript. Voice via VoiceMLModule, TTS via TextToSpeechModule (Sasha), camera via CameraModule, GPT-4o (text + vision) via Snap's Remote Service Gateway.
Architecture decisions worth naming:
- Finn proposes, user confirms. Single safety rule: we never go from utterance straight to a ledger mutation. Every action is two human moments — Finn proposes, user says "confirm."
- Typed
FinnIntentenvelope between the LLM and the state machine:interpret(text) → { action, source, dest, amount, speak, confidence }. The controller stays dumb; the LLM owns parsing. - Buffer-on-settle for fragmented voice finals. The VAD chops conversational speech every ~700 ms of silence. We accumulate fragments for \( \Delta t = 1.2\,\text{s} \) then dispatch one full utterance. Control verbs ("confirm", "cancel") fast-path past the buffer for instant response.
- Keyword pre-filter before any LLM call: transcripts that don't contain move / transfer / basket / euros / finn / … get dropped silently. No paid LLM call, no random Sasha reply on ambient chatter.
Visual. A procedurally-generated bunq rainbow backdrop (sampled stripe colors from the actual logo, regenerated as a clean stripe-only PNG), a SUIKit Frame-wrapped movable window, a breathing orb that lerps color on state transitions
$$ s(t) = s_0 \cdot \left(1 + 0.05\sin!\left(\tfrac{2\pi t}{2\,\text{s}}\right)\right) $$
magenta → cyan → green, plus color-coded cards (Main green, Travel cyan, Tax red, Tech orange, Emergency yellow).
Unusual workflow note: the entire scene scaffold — hub, four screens, navigation routing, ~30 SceneObjects, ~15 materials, all the wiring — was built via Lens Studio's MCP server driving the editor programmatically from Claude Code. We wrote zero click-through guides; we wrote prompts.
Challenges we ran into
- VAD fragmentation.
VoiceMLModule.ListeningOptionsexposes no endpoint-silence-threshold knob. Discovered mid-build that the module is deprecated —ASRModuleexposessilenceUntilTerminationMsdirectly — but migration didn't fit the timebox. Buffer-on-settle was the workaround. - TTS silently fails on non-ASCII. Em-dash, ellipsis,
€all fireerr 13with no audible cue — perfect way for a demo to degrade on stage without anyone realizing. Defense in depth: sanitize at the speak boundary AND tell the LLM in its system prompt to emit plain ASCII. - Spectacles back-face culling. Rotated planes and Text3Ds vanish at certain head angles unless
twoSided=trueon every material — easy to miss in editor, brutal on-device. OnEnableEventdoesn't propagate. A SceneObject's enable event only fires when its ownenabledflips, not its ancestor's. So we couldn't start the mic on screen-enter; voice has to start inonAwakeand stay always-on.- Frame component vs content positioning. SUIKit's
FramedefaultsautoScaleContent: trueandrelativeZ: true, both of which silently rescale child Z values and re-introduce z-fighting. Both must be disabled.
What we learned
- Spectacles AR isn't a phone with extra steps — it's a different surface where glanceability beats density and voice + confirm beats touch.
- The hard part of an LLM agent isn't the LLM call; it's the boundary code — the buffer, the gate, the typed envelope, the safety confirm. The LLM is one line.
- Lens Studio's MCP server is genuinely transformative for AR development — letting an agent drive scene composition lets you iterate on layout at the speed of language instead of the speed of clicks.
Built with
Tag list (paste one-per-line into Devpost's "Built with" field):
typescript
lens-studio
snap-spectacles
spectacles-interaction-kit
spectacles-ui-kit
voiceml-module
text-to-speech-module
camera-module
remote-service-gateway
openai
gpt-4o
gpt-4o-vision
mcp
claude-code
powershell
bunq-api
Built With
- lensstudio
- snap
- typescript.




Log in or sign up for Devpost to join the conversation.