-

-

Home Page
-
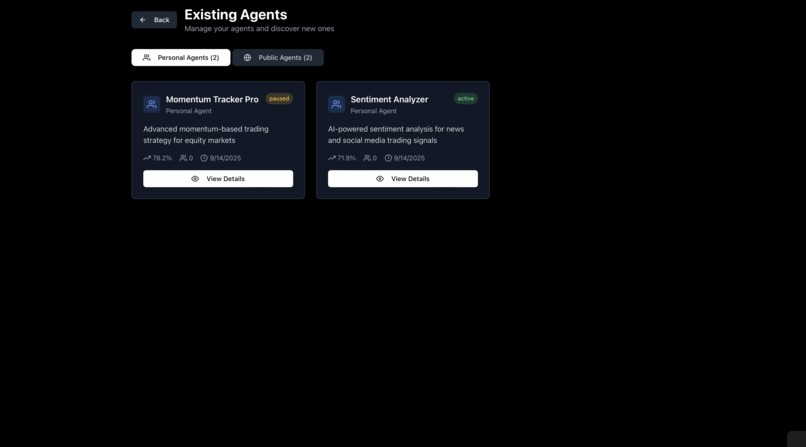
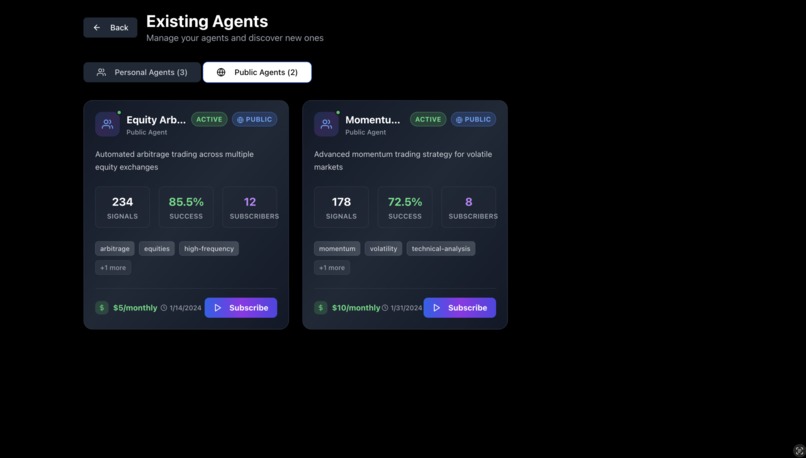
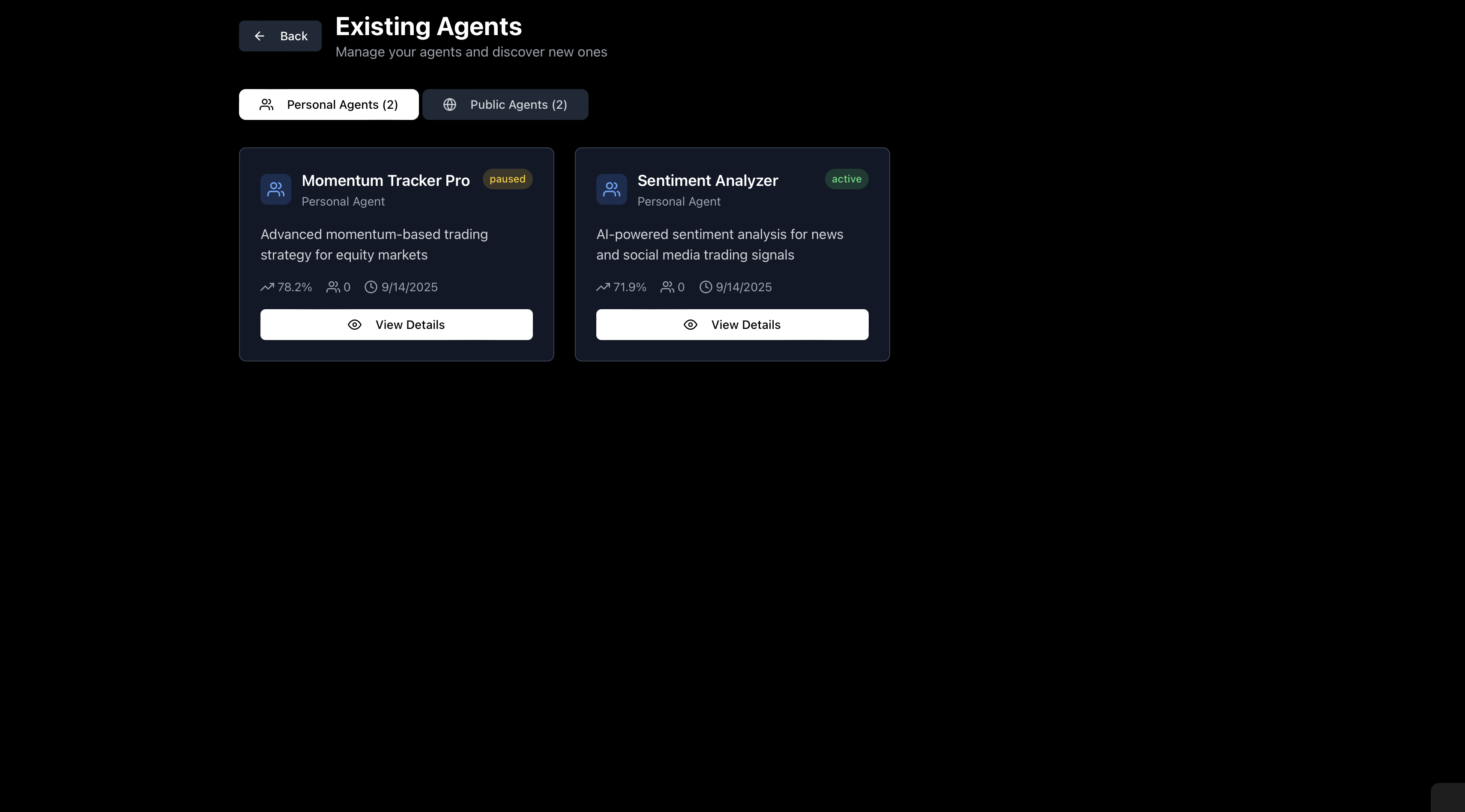
Viewing Your Agents
-
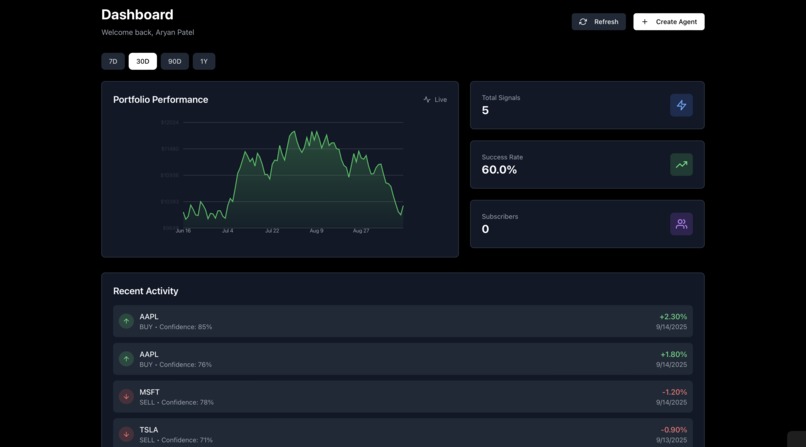
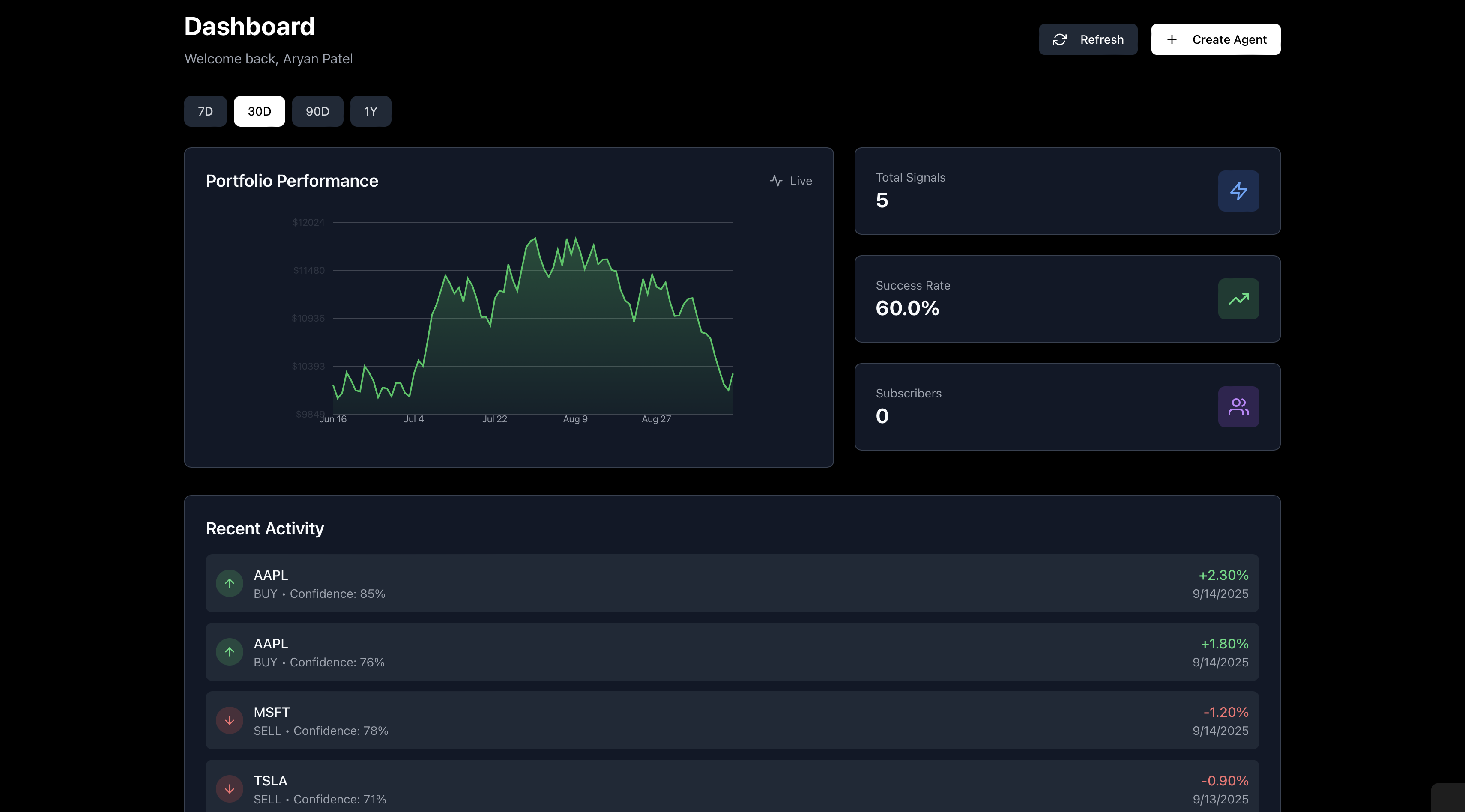
Dashboard
-
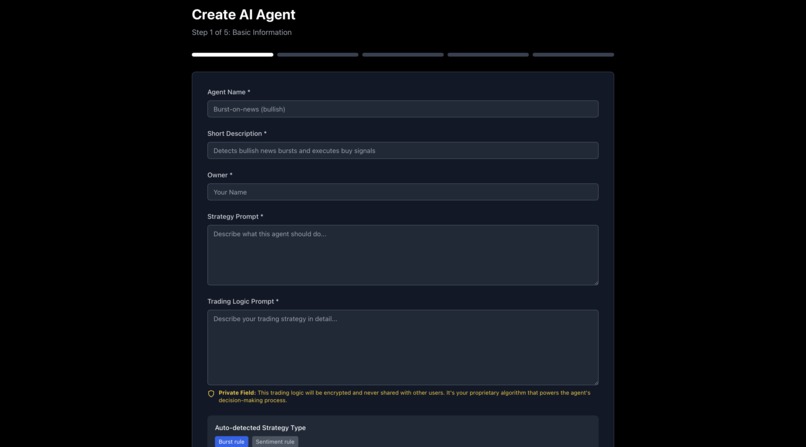
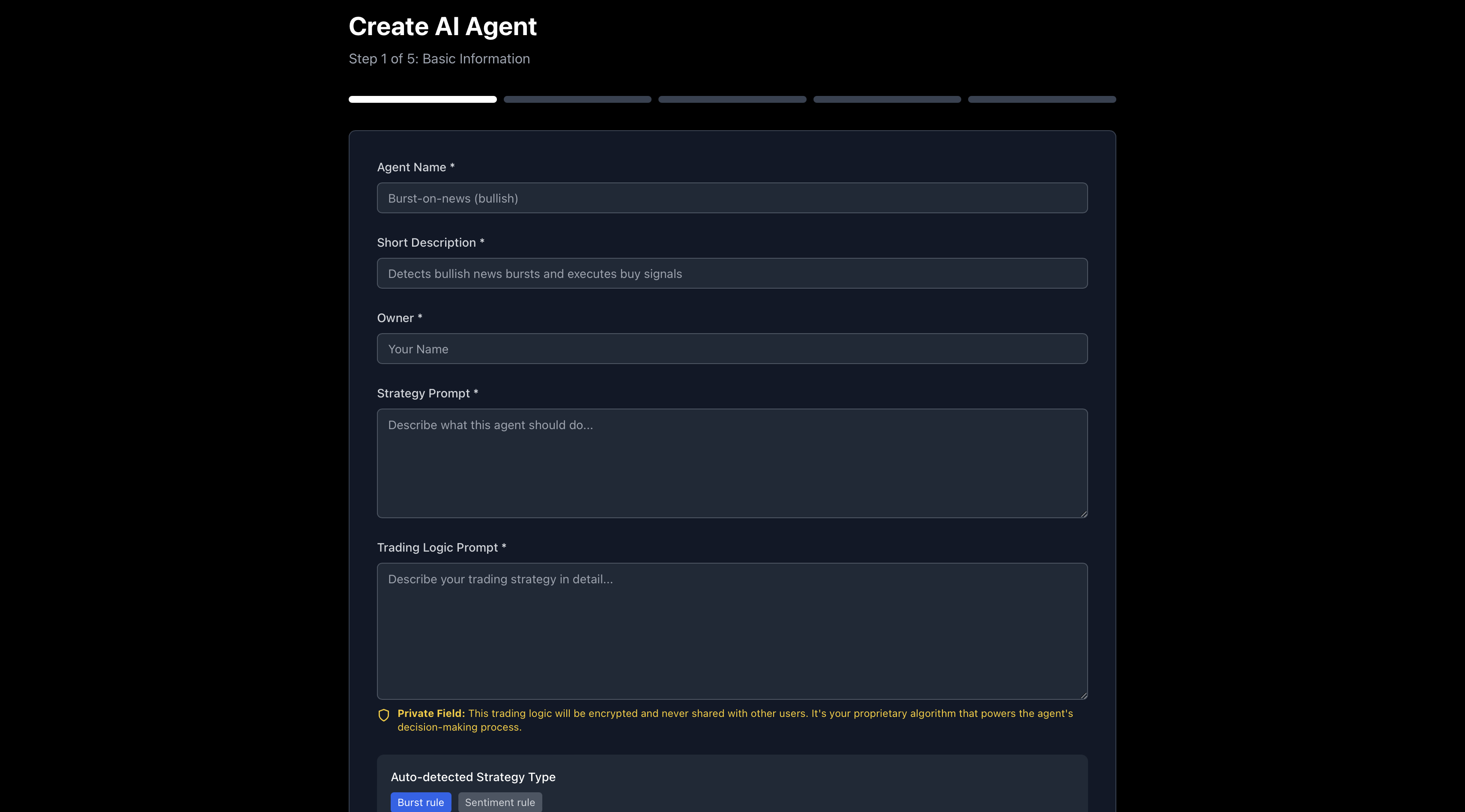
Creating Your Own Agent
-
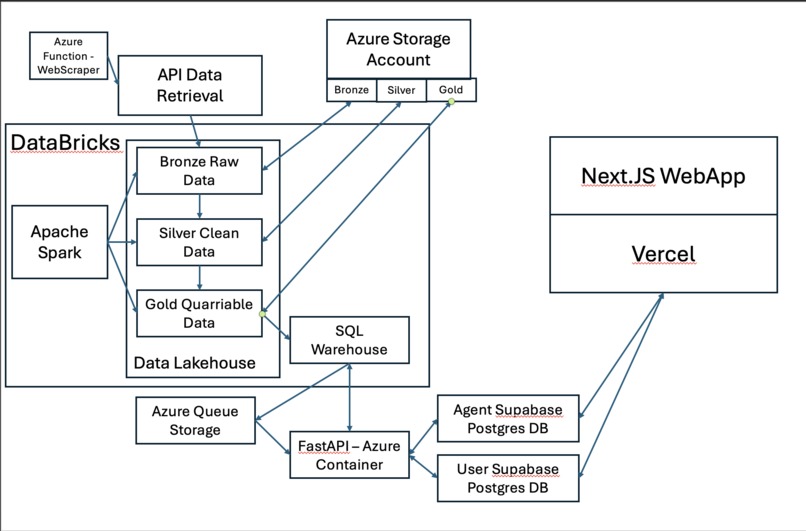
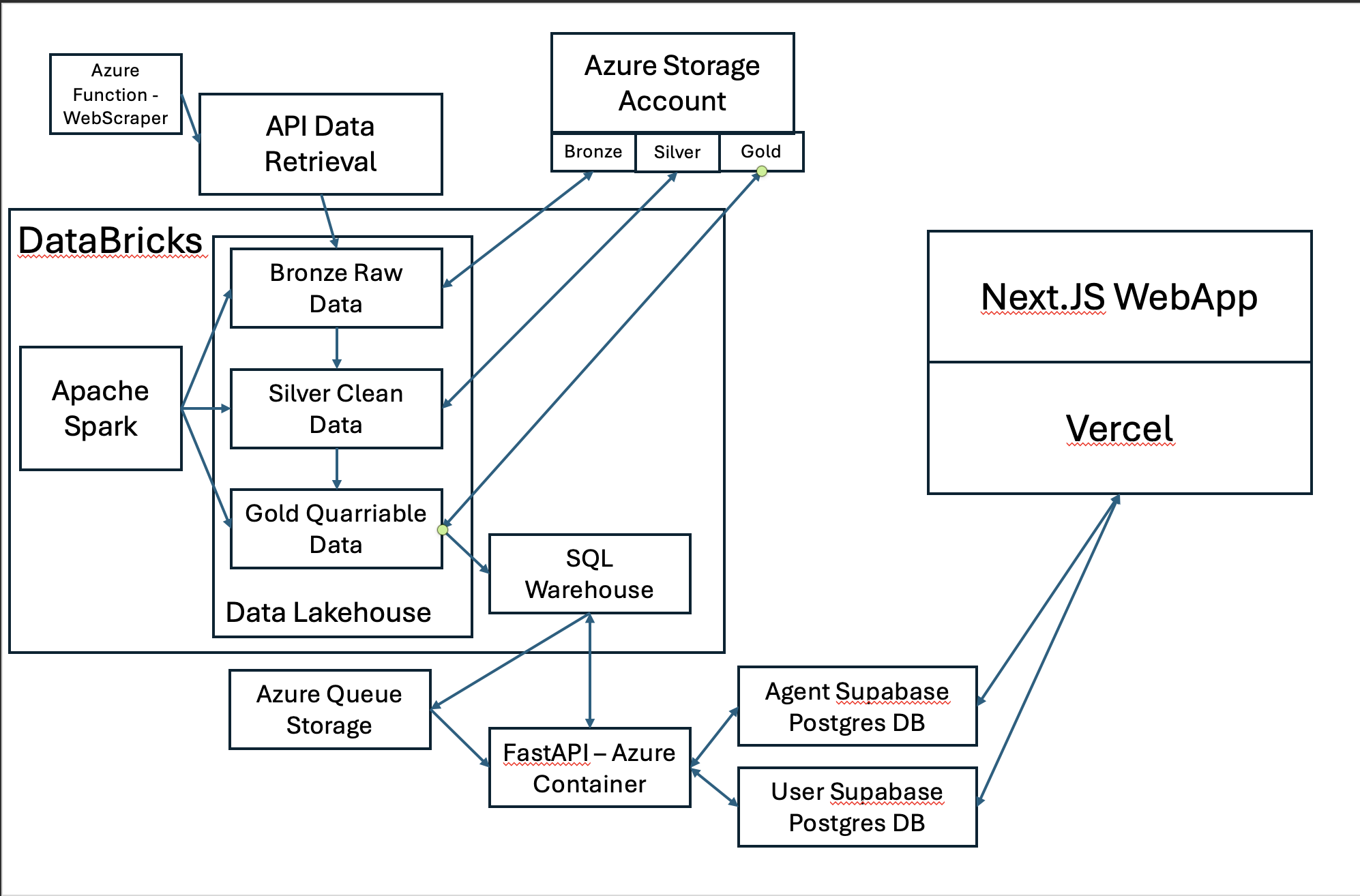
Architecture
-


Inspiration
We set out to redefine investing and trading by pairing large-scale data processing with agentic trading bots available to everyone. Traditional trading often requires expensive tools, constant monitoring, and complex setup for algorithms and indicators, but we wanted to change that. FinLake handles the entire data pipeline, from ingestion and refinement to agent creation, so all you need to do is describe how you want to trade. Whether it’s something simple like buying one promising stock per week or creating complex strategies around ETFs and S&P 500 options, users can implement their trading ideas with a single prompt while FinLake manages the heavy lifting.
What it does
FinLake ingests over 1,000 financial news sources per minute via APIs and scrapers, and processes them on Databricks with Apache Spark in a Medallion architecture (Bronze → Silver → Gold). The result is a continuously updated, queryable Delta Lakehouse stored in ADLS. Users then provide natural-language prompts to generate event-driven LangGraph trading agents. These agents query the Gold tables for real-time sentiment context, apply trading logic, and execute strategies. Users can monitor their agents, track performance, and switch between paper trading and live execution.
How we built it
We used Databricks, Apache Spark, Delta Lake, and Azure for the ingestion pipeline and data refinement. Processed data is stored in ADLS and exposed through Databricks SQL Warehouse. On the agent side, we built a Next.js full-stack web app hosted on Vercel, with Supabase Postgres for agent storage and FastAPI for orchestrating queries to the Gold tables and executing agents. Sentiment models provide fast and accurate scoring, while agents are event-driven through LangGraph.
Challenges we ran into
Learning curve: This was our first time using Databricks, and setting up a full Medallion pipeline with Spark, Delta Lake, and SQL Warehouse from scratch required extensive trial and error. Real-time performance: Handling minute-level ingestion and ensuring the pipeline remained stable under constant updates was a major engineering hurdle. Agent orchestration: Designing agents that could reliably query Gold tables, apply trading logic, and persist state across Supabase and FastAPI required balancing flexibility with reliability. Integration overhead: Connecting many moving parts (Databricks, ADLS, Supabase, FastAPI, Next.js) while keeping latency low was more complex than expected.
Accomplishments that we're proud of
This was our first time working with Databricks, and going from zero to a functioning large-scale pipeline with Medallion architecture was a huge accomplishment. We’re also proud that FinLake can spin up trading agents from simple prompts, bridging big data engineering and user-friendly AI trading.
What we learned
How to design and implement the Medallion Data Architecture with Delta Lake and Spark to handle high-throughput financial data. How to integrate LangGraph agents into a production-style stack, combining data pipelines with AI-driven orchestration. How to build a system that balances real-time performance, governance, and user accessibility, making big data usable for end-users. The importance of auditability and risk guardrails when simulating financial trading systems.
What's next for FinLake
Bot marketplace: Enable users to share and rent each other’s bots while keeping intellectual property hidden. Expanded datasets: Incorporate additional financial data sources (earnings calls, SEC filings, social media) to improve signal quality. Deeper analytics: Build dashboards for PnL tracking, sentiment indices, and portfolio performance using Gold tables. Scalability & cost optimization: Move from hackathon infrastructure to a more cloud-native production setup with autoscaling and optimized costs.
Built With
- azure
- data
- data-lakehouse
- databrick
- next
- node.js
- postgresql
- python
- supabase
- vercel



Log in or sign up for Devpost to join the conversation.