-
-
Datasets used
-

Methodology
-
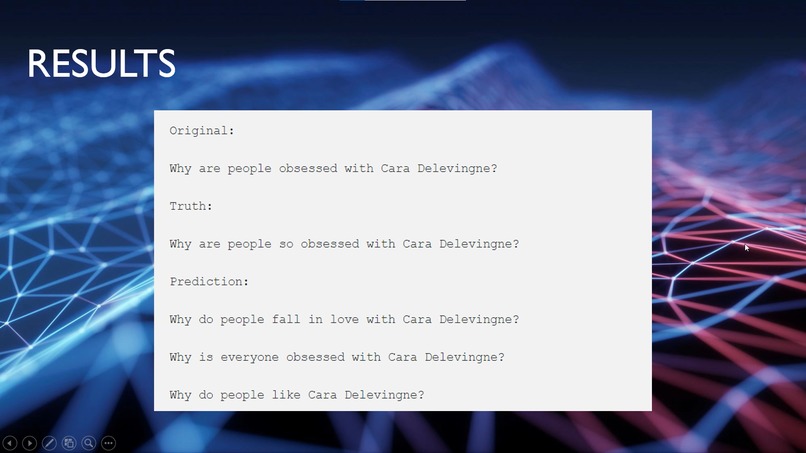
Results (one example)
-
Objective of hackathon - Training the model on Amazon EC2 DL1 instance


Inspiration
The inspiration of this project, as is of any AI project, is the vision of a more automated and insightful world of technology. It's truly amazing how we can leverage natural language to build tools and technologies that improve the quality of our lives. This project targets the niche application of paraphrasing which can be useful in automating FAQs, build better plagiarism check systems and more.
What it does
This model is trained on three large, authentic and consistent datasets of pairs of sentences along with human annotations indicating semantic equivalence. The Facebook-BART-large model has been finetuned to generate one truth and three paraphrases of a given sentence. All predictions can be stored in a new file for validation. Alternatively, users can test the model for their own sentences, and the code for this can be found in the linked GitHub repository. To mitigate the inefficiencies of having duplicate question pages at scale, an automated way of detecting if pairs of question text actually correspond to semantically equivalent queries is required. This is exactly what the model does.
How I built it
The model was built by fine-tuning the pretrained BART model. Python was used as the scripting language. Tensorflow was the main framework. Libraries like simpletransformers and torchvision were used to build the seq2seq model. The model was trained on all 8 Gaudi accelerators on the new Amazon EC2 DL1 instances which proved to be extremely efficient. Training was completed in close to an hour, whereas a normal CPU would have taken days to work with a dataset of this size. Habana Deep Learning Base AMI was used with the latest tensorflow image. The model, publicly available on GitHub was cloned and trained on the instance with the help of it's advanced features.
Challenges I ran into
I was completely new to AWS and Habana and had to go through many tutorials to familiarize myself with the environment. It took some time to understand how to migrate an existing model on the instance and use the correct drivers and frameworks. However, with the help of the Slack Community and the resources provided the project went smoothly.
Accomplishments that I'm proud of
I'm proud that I was able to effectively use the powers of the Gaudi accelerators to train a model that would have taken days to train otherwise on a normal CPU. I'm proud that I was able to learn the technologies involved in the project from scratch on my own.
What I learned
I learnt how to navigate the AWS console and how to create, launch and manage instances. I learnt how to migrate an existing model on a new instance. I learnt how to train a model with the Tensorflow and Pytorch image provided by Habana. I learnt how what specifications are best while creating a virtual machine. Lastly, I learnt how to edit videos haha ;)
What's next for Finetuning BART for paraphrasing applications
The future scope of this model lies in applications such as Automated FAQs. Sites such as Quora have thousands of new questions posted daily, and it would be of great convenience to hosts and users if such users were automatically guided to similar questions that have already been answered. Similarly, sites that provide trainings and have FAQ channels, Companies that have service-request portals can all use the same technologies. Another application of this could be better plagiarism checker systems. Systems should be able to check if two sentences are semantic duplicates or not, rather than simply checking for word-to-word matches. There is tremendous work involved in this project beyond just the training of the deep learning model and I hope to integrate it soon with various softwares and websites through APIs.

Log in or sign up for Devpost to join the conversation.