-
-
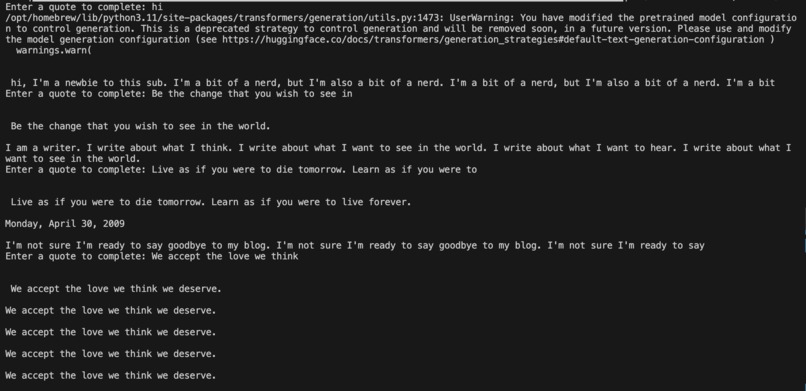
Runs Pt. 2: QA
-
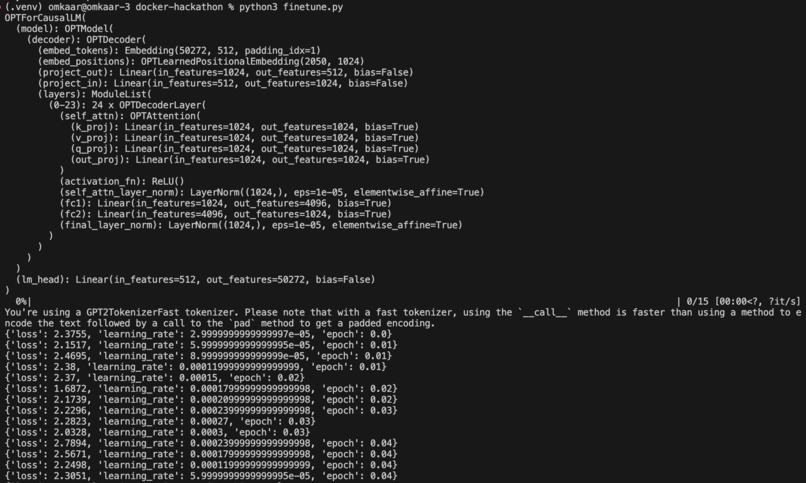
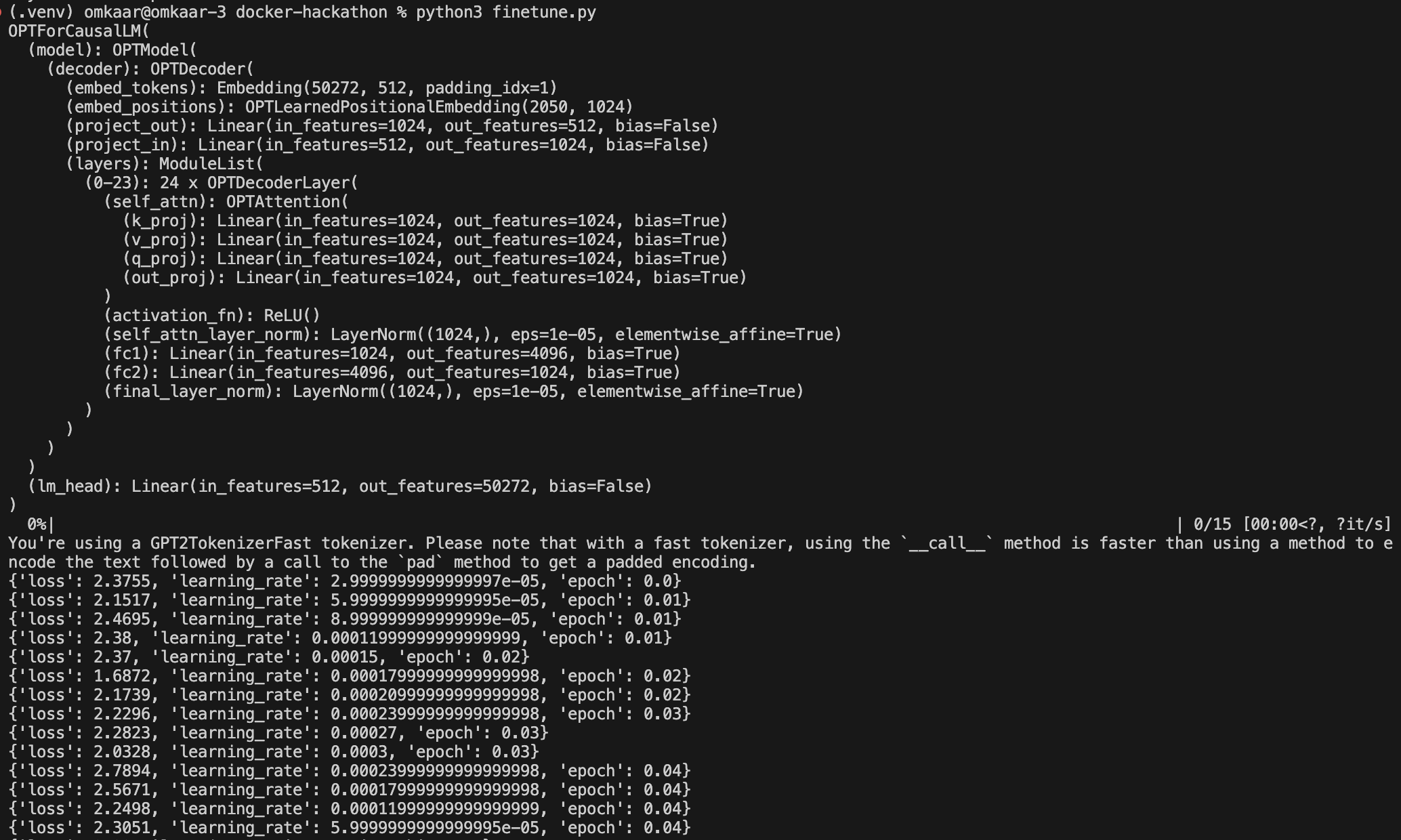
Runs Pt. 1: Model Arch

Inspiration: The concept for this project sprouted from an article on Hacker News, which spoke on the challenges of deploying local LLMs and how such difficulties impede testing and faster iteration. Ollama made strides by simplifying the installation of popular LLMs for users. Building on this, the project aspires to empower developers to fine-tune (PEFT in particular) these models locally, then seamlessly distribute them via Docker, leading to rapid collaboration and iteration within LLM and corporate development teams. Fintetuning on local setups cannot be done unless you have a GPU rig even for smaller models. My contraption makes it possible!
What It Does: Fine-tuning is highly resource-intensive and not something that was conventionally recommended for a personal setup. Recent developments in techniques like Parameter-efficient fine-tuning is what inspired this project. Using my docker image, people can just specify the model and their dataset and finetune models right on their computer!
This initiative equips developers with the tools to fine-tune open-source LLMs, like Meta's LLaMA or SD's Vicuna, using proprietary/custom datasets. The resulting fine-tuned models are encapsulated within Docker containers and stored on dockerhub, ensuring straightforward sharing and deployment. Each container is bundled with all the essential dependencies and scripts, ensuring a consistent and movable environment ideal for model refinement and testing. My vision is for Dockerhub to be the Google Drive for local LLMs (fast and quick sharing unlike a hugging face deployment which is usually after the model is done being iterated on).
How I Built It: The construction of this project is straightforward ongoing. Balancing part-time work and university exams has constricted my time, but despite these constraints, I've made progress by talking with AI engineers and specialists within my network to validate the problem.
Challenges I Ran Into: The intricacies of model fine-tuning present a significant hurdle; simplifying this complexity for users while maintaining efficiency is challenging. Additionally, integrating Docker with local GPUs has been a complex task. Another obstacle is the size of the Docker images; to maintain ease of distribution, helping users compress models via quantization has been a provisional solution. Finally, the lack of a GPU on my computer has made it a little tough for me to use larger, more-effective models.
Accomplishments That I am Proud Of: The journey has been enriching, I have gained deep insights into Docker's workings and the nuances of model fine-tuning, especially PEFT.
What's Next for FineTuneHub: The goal is to see this project through to completion. Regardless of the outcome at the hackathon, there's already a vested interest among my peers who see the potential utility of this tool within their organizations.


Log in or sign up for Devpost to join the conversation.