-
-

AI Generated Photo for Project
-
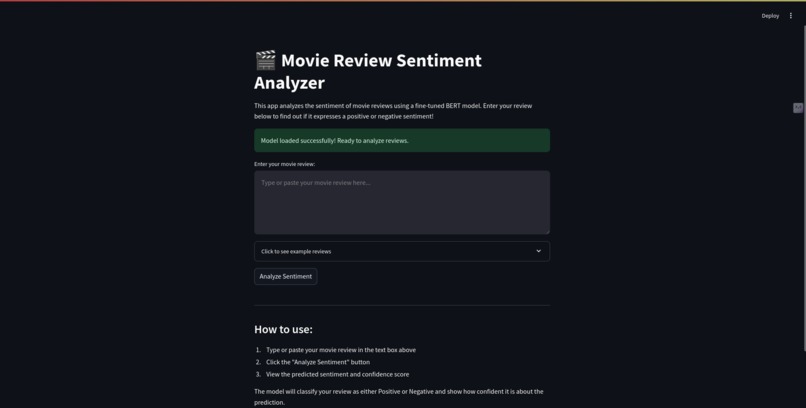
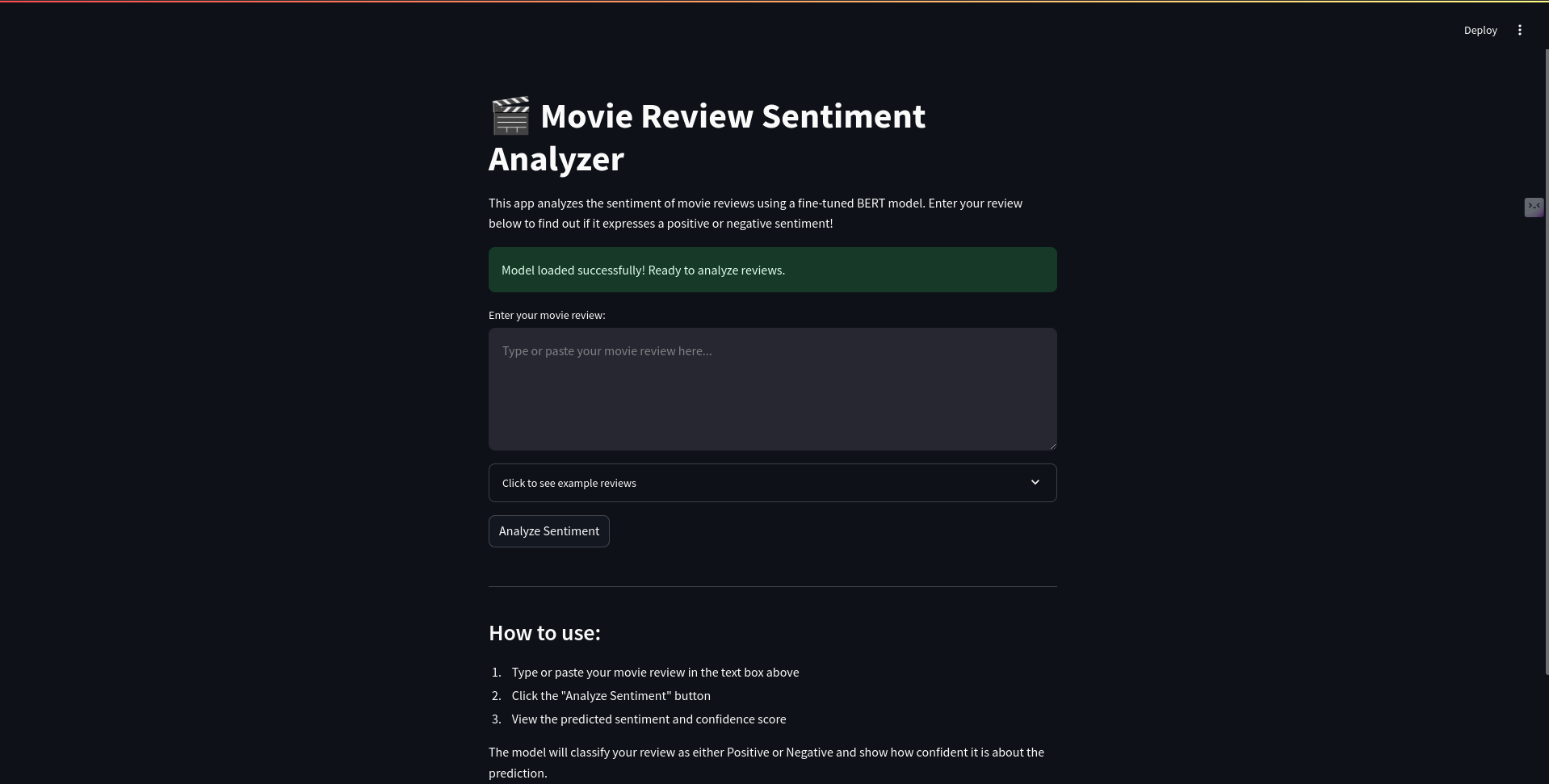
UI for frontend

Inspiration
The ever-increasing number of movie reviews online makes it challenging for viewers to gauge the sentiment accurately. Inspired by the need to automate this process, we designed this project to explore how fine-tuning pre-trained models like BERT can be used to classify sentiments with precision while optimizing for computational efficiency.
What it does
This project fine-tunes a pre-trained BERT model to classify movie reviews into positive or negative sentiments. Using Parameter-Efficient Fine-Tuning (PEFT) and Low-Rank Adaptation (LoRA), the model achieves high accuracy with reduced computational costs.
How we built it
1. Dataset : The IMDb movie review dataset was used for training and testing.
2. Pre-processing : Tokenization and padding were performed using Hugging Face's tokenizer.
3. Model : We fine-tuned the BERT base model with LoRA adapters using PyTorch and Hugging Face Transformers.
*4. Training Optimization : * PEFT and LoRA helped in reducing the number of trainable parameters, making the model lightweight and faster to train.
*5. Evaluation : * Accuracy, F1-score, and confusion matrix metrics were used to evaluate the model's performance.
6. Deployment : The model was deployed using Streamlit for a user-friendly interface where users can input a review and get instant feedback on its sentiment.
Challenges we ran into
1. Data Imbalance : Managing an imbalanced dataset where positive reviews outnumbered negative ones required techniques like oversampling and weighted loss functions.
2. Computational Constraints : Fine-tuning BERT models requires significant computational resources. Implementing LoRA and PEFT allowed us to reduce training overhead.
3. Overfitting : Regularization and dropout techniques were crucial to prevent overfitting during fine-tuning.
Accomplishments that we're proud of
Successfully fine-tuned a complex model like BERT with significantly fewer parameters using PEFT and LoRA. Achieved over 90% accuracy on the IMDb dataset, surpassing baseline models. Created an interactive web application to demonstrate the project’s real-world usability.
What we learned
The importance of using parameter-efficient techniques to optimize large language models. Practical insights into fine-tuning transformer-based architectures like BERT. Best practices for building robust and efficient sentiment analysis pipelines.
What's next for Fine-Tuned BERT for Movie Reviews
Multilingual Support: Extending the model to classify reviews in multiple languages. Real-Time Deployment: Deploying the model as an API for integration with existing platforms. Improved Interpretability: Adding visualization tools to explain the model’s predictions. Data Augmentation: Using synthetic data to further improve performance on smaller datasets.

Log in or sign up for Devpost to join the conversation.