Inspiration
Modern "agentic" DFIR tools have a dirty secret: they promise to treat evidence as read-only in a system prompt, then hand the model a raw shell with write access. The integrity guarantee is a request, not a constraint — one bad tool call (or one prompt injection) away from altering the very evidence it's examining.
At the same time, the smartest attackers don't smash and grab — they lie to the disk. They backdate a file's timestamp so it looks old and trusted (timestomp, T1070.006), or drop a binary named svchost.exe somewhere it doesn't belong (masquerade, T1036). Look at any single source and you're fooled.
We wanted to fix both problems at once: an agent that cannot modify evidence — not because we asked it nicely, but because the capability doesn't exist — and that catches the lie by cross-referencing what the disk claims against what memory proves.
What it does
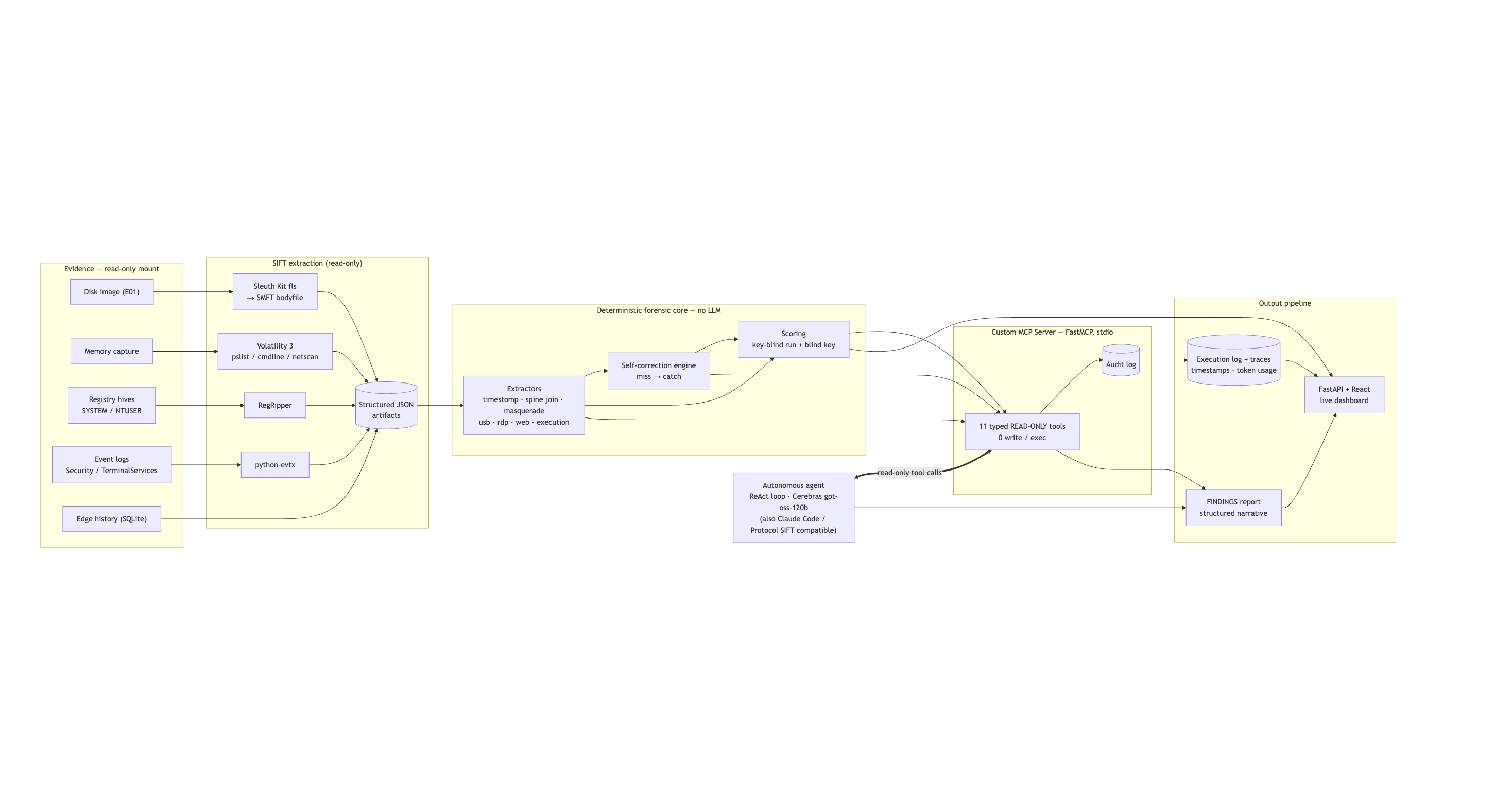
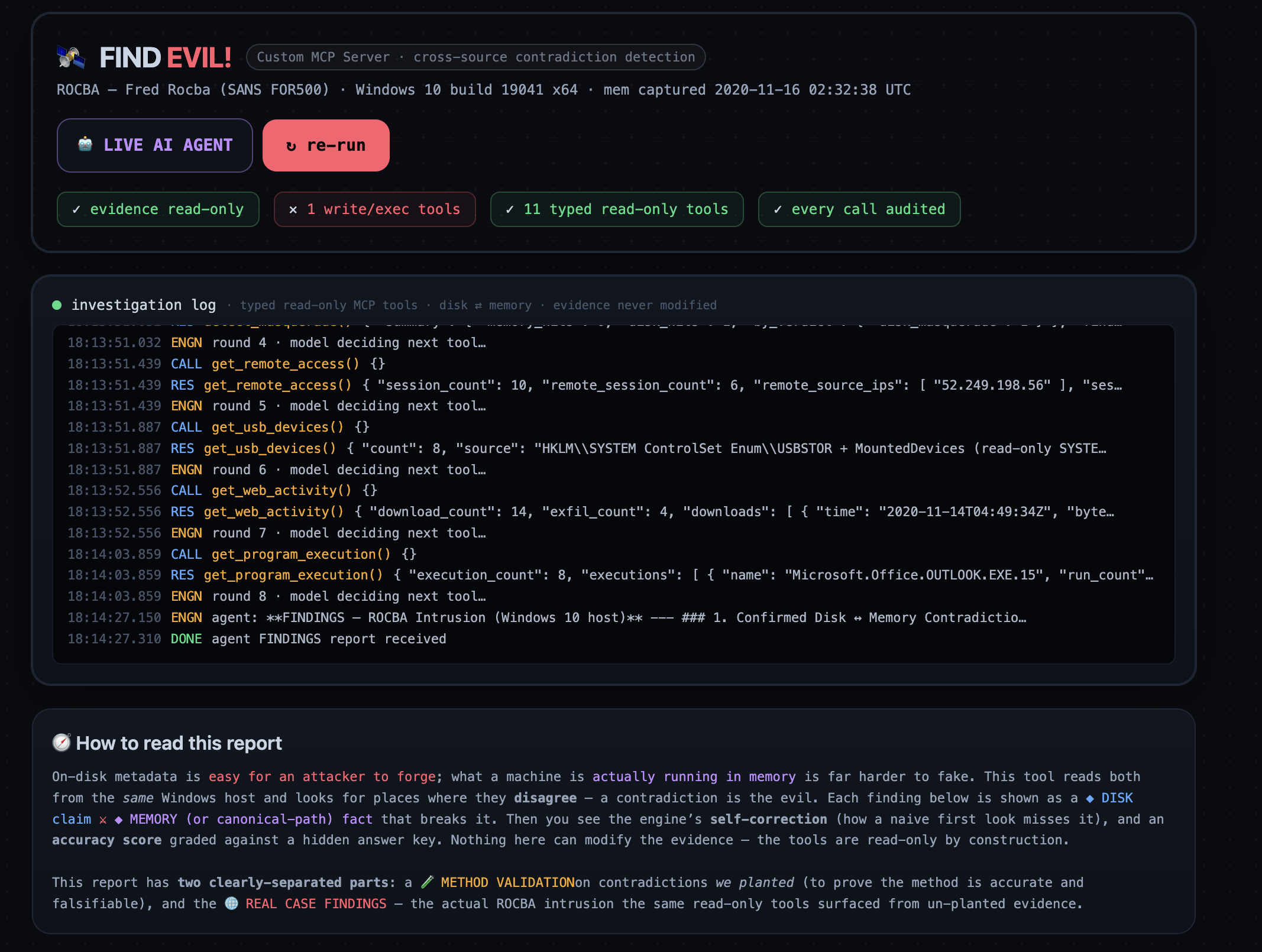
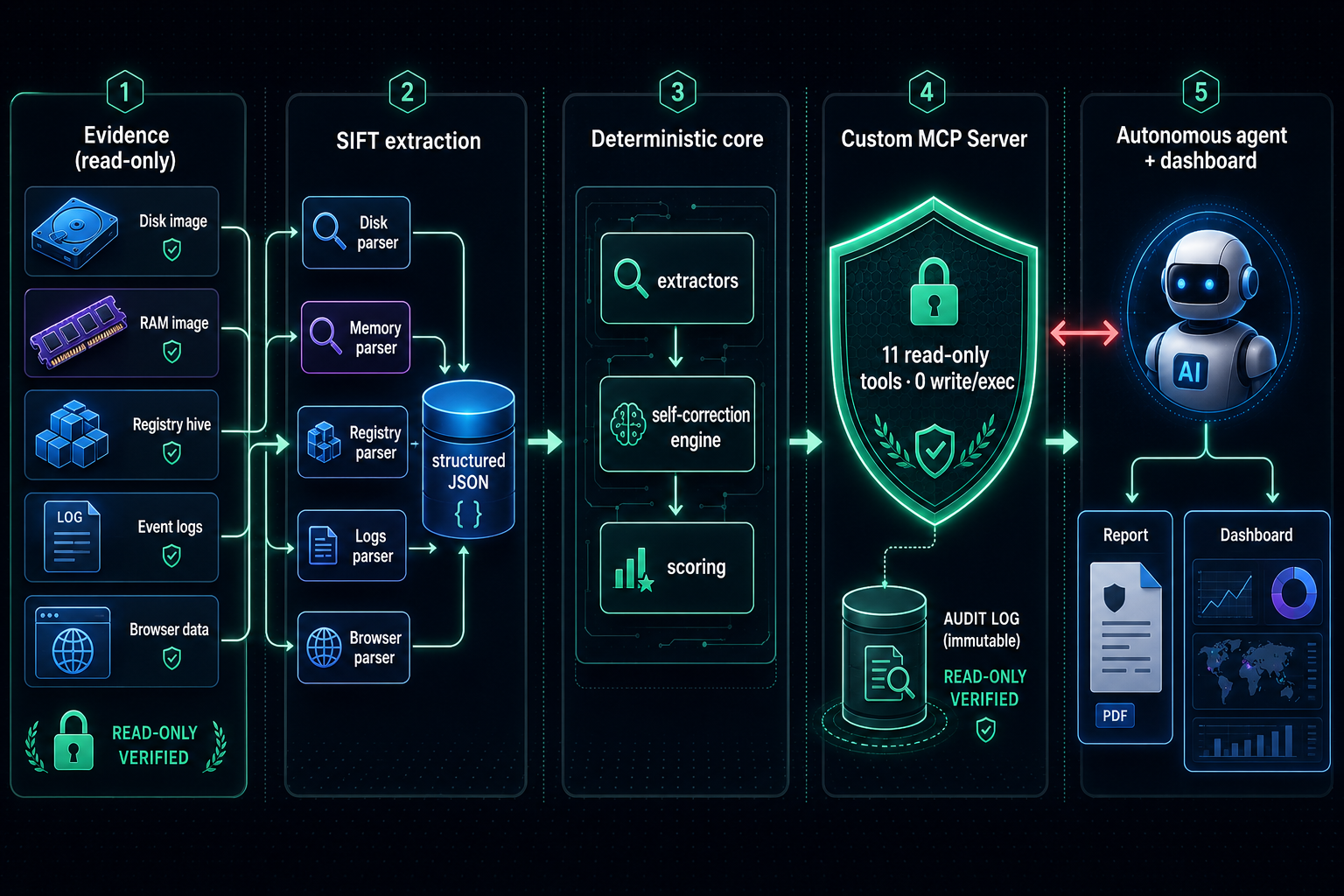
FindEvil is an autonomous DFIR agent built on a Custom MCP Server that exposes only typed, read-only forensic tools. There is no run_shell, no write, no delete — so evidence integrity is architectural, not a promise. The agent (a model-agnostic ReAct loop running on Cerebras gpt-oss-120b — no Claude/Anthropic dependency) can call those getters or nothing.
It works the SANS FOR500 "Fred Rocba" / Stark Research Labs case (disk image + memory capture from host SRL-FORGE) and does two things:
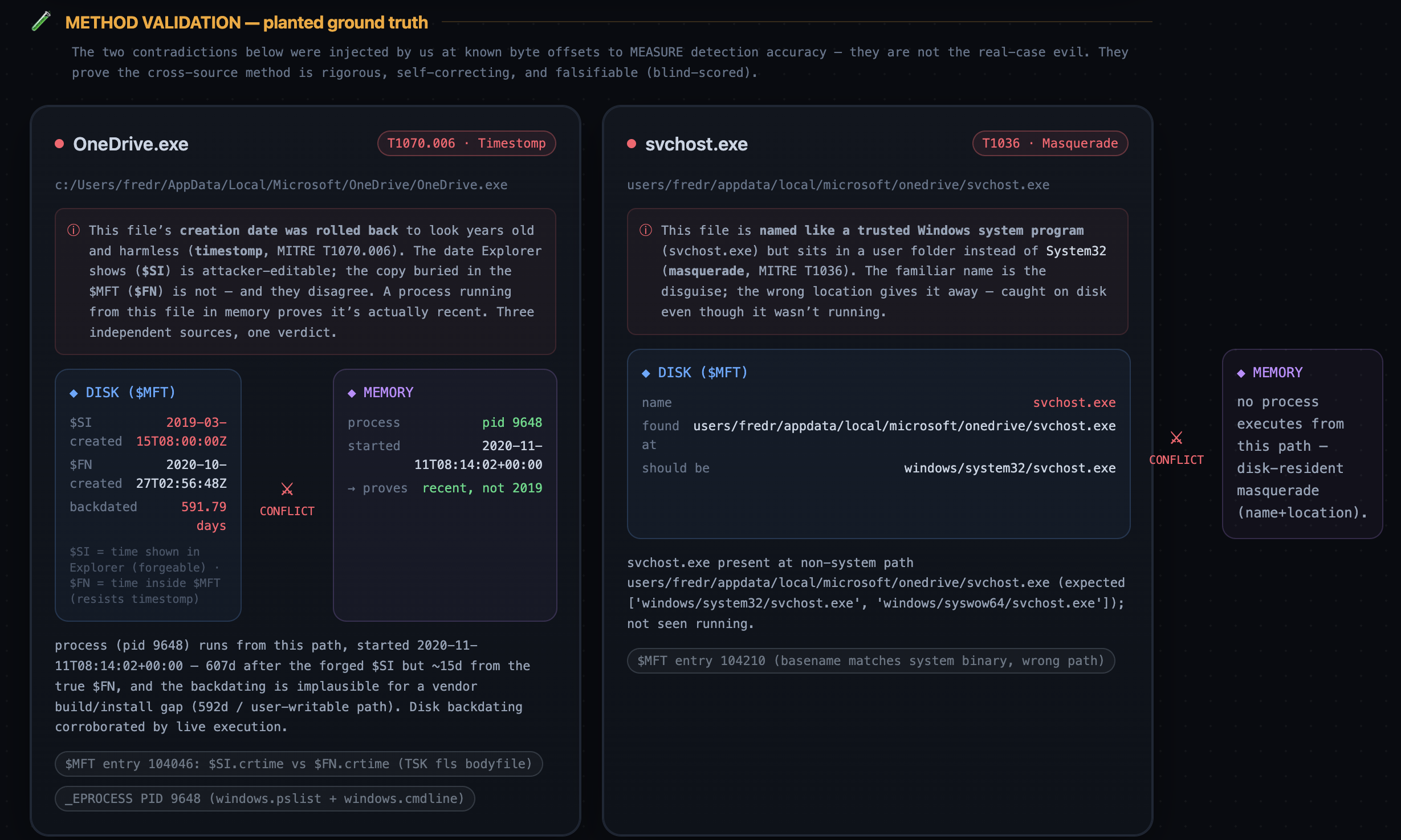
1. Catches planted contradictions — and proves it (blind-scored validation). We inject two known adversary-style contradictions at known byte offsets, then score detection against a ground-truth key the model never sees:
- Timestomp:
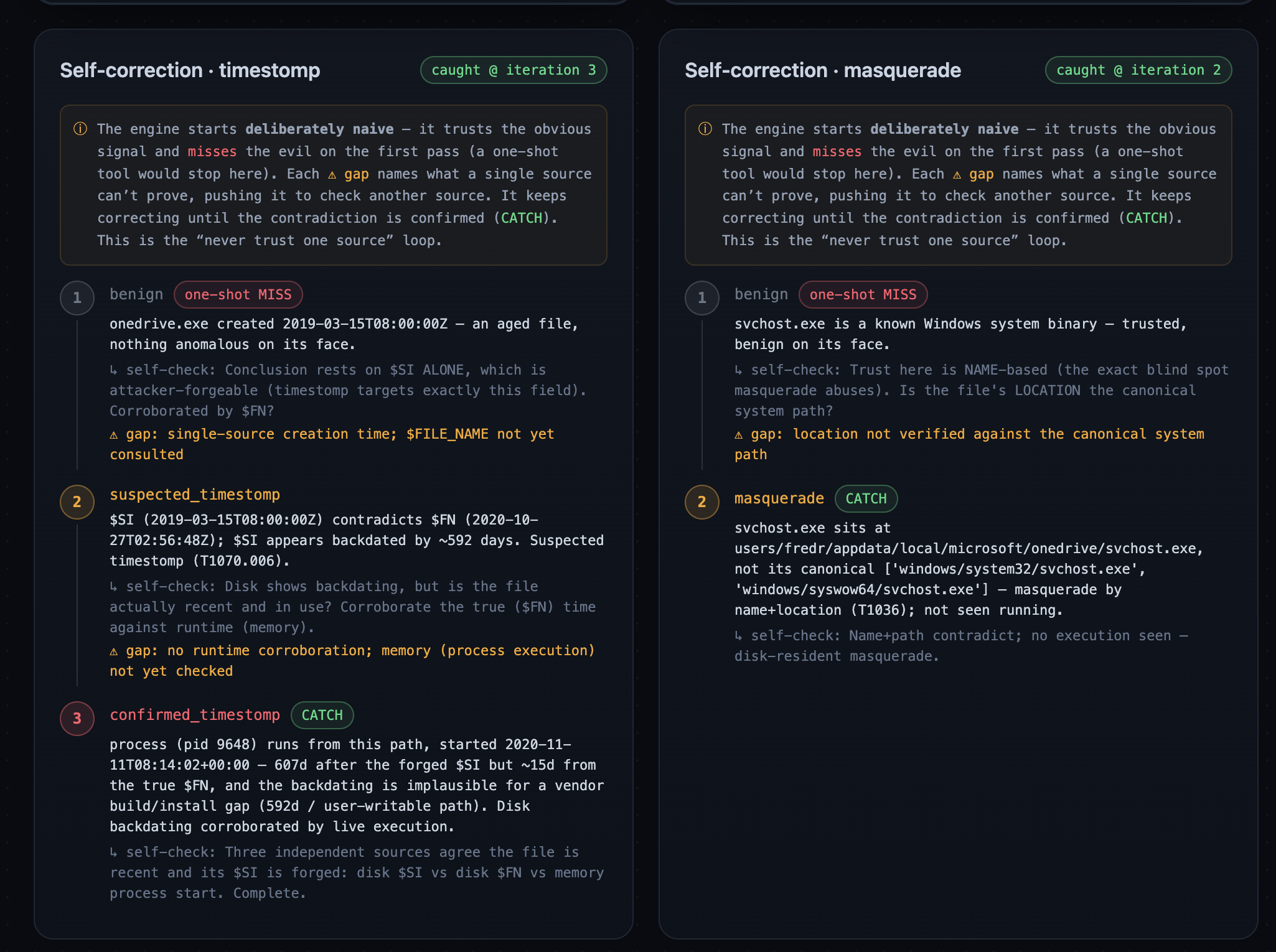
OneDrive.exewith$SIcreation backdated 591.79 days (2020‑10‑27 → 2019‑03‑15) — caught by comparing the forgeable$SIagainst the tamper-resistant$FN, then corroborating with a live process (PID 9648) running from that path. - Masquerade:
svchost.exesitting in a user OneDrive folder instead ofSystem32.
A self-correction engine reproduces how a one-shot look misses these and iterates to a catch:
$$\text{benign} \rightarrow \text{suspected} \rightarrow \textbf{confirmed}$$
Scored against the blind key:
$$\text{catch@iter1} = \frac{0}{2}\ (0\%) \quad\longrightarrow\quad \text{catch@final} = \frac{2}{2}\ (100\%)$$
…with 0 false positives and 0 false negatives across 35 real timestomp candidates it also scanned.
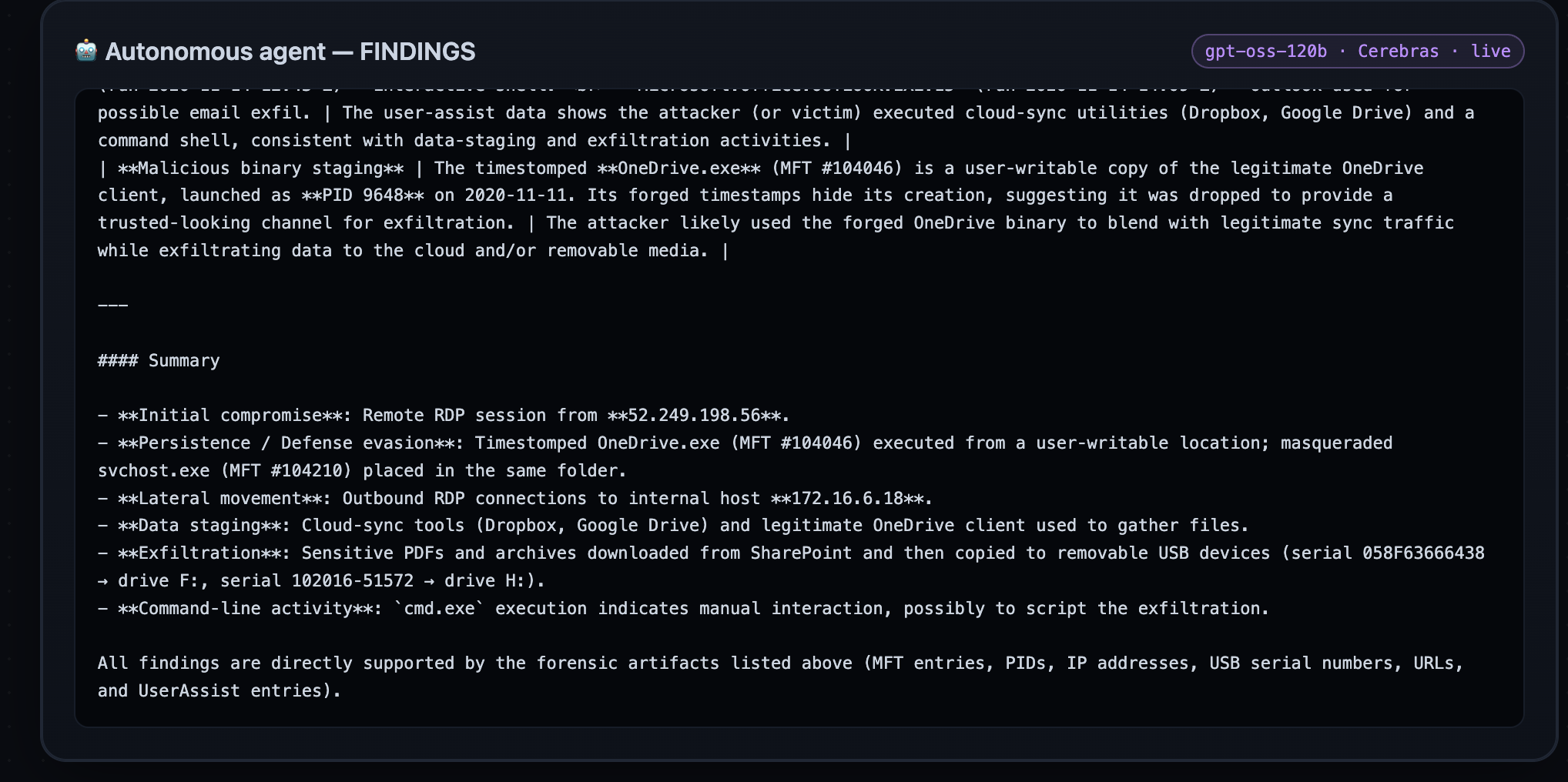
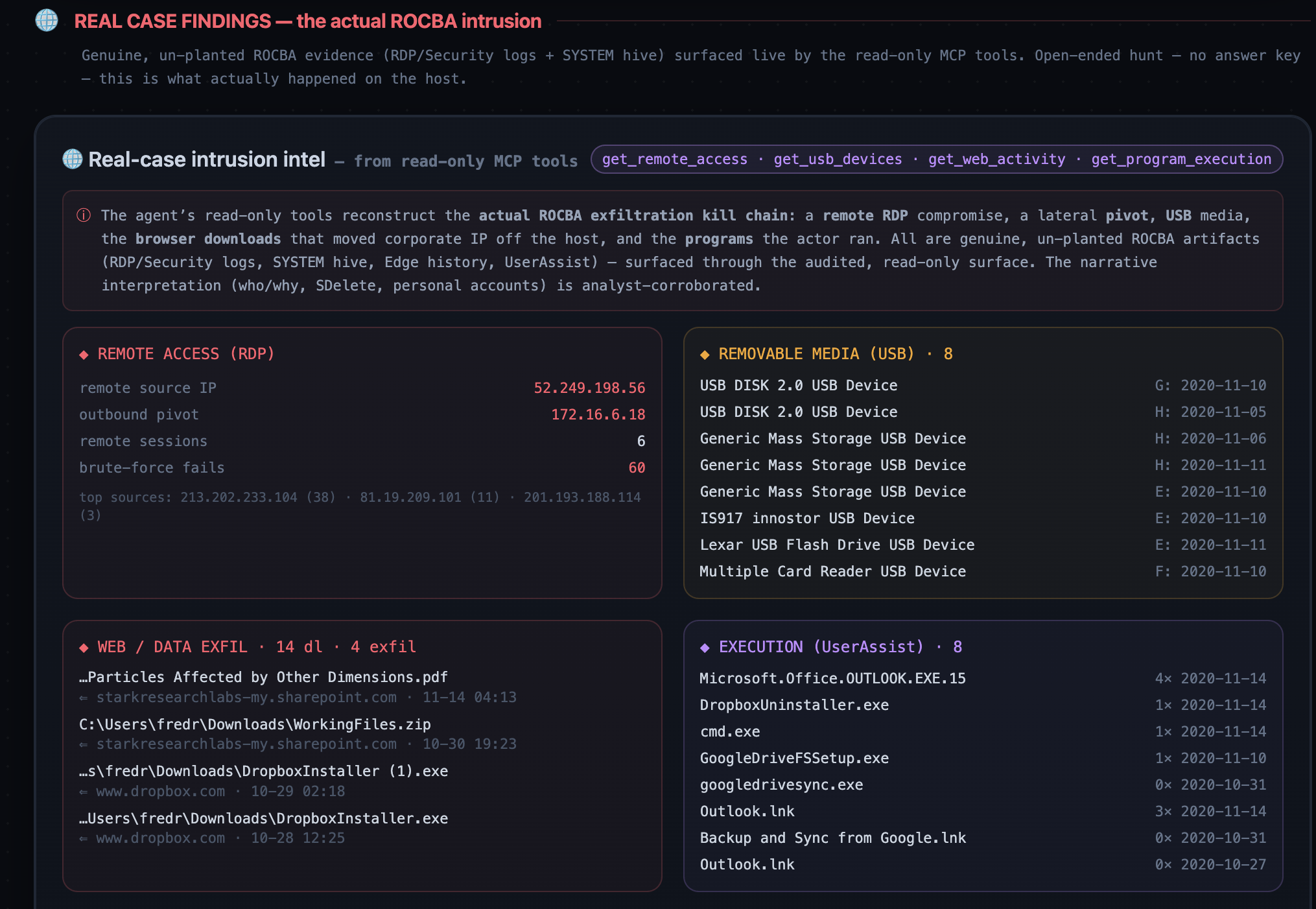
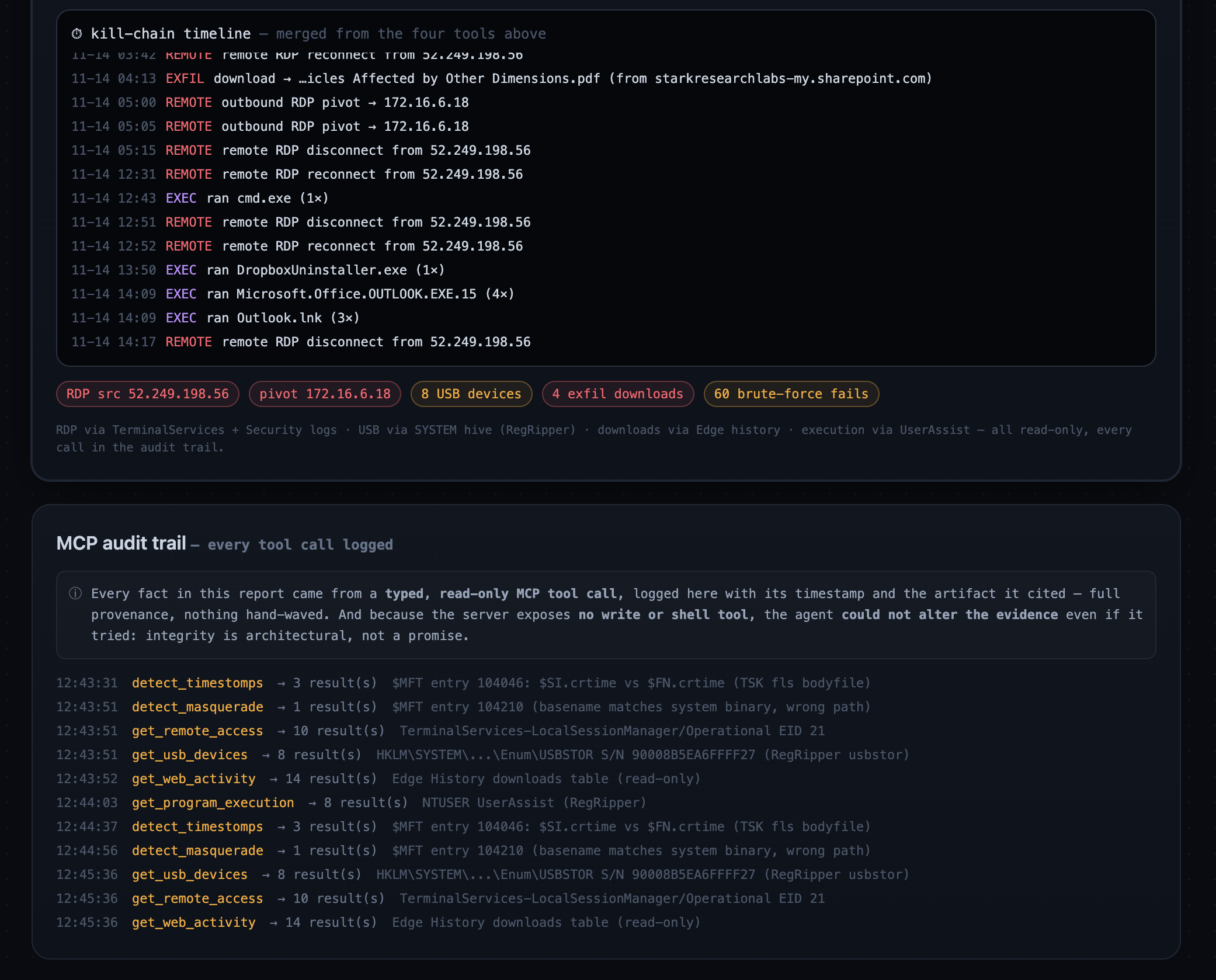
2. Reconstructs the real intrusion. Using the same read-only surface, the agent surfaces the genuine ROCBA kill chain:
- Remote RDP compromise from source IP
52.249.198.56(underfredr, while Fred was on vacation), with a lateral outbound RDP pivot to172.16.6.18. - Data exfil: a colleague's SharePoint document (
Quantum Particles Affected by Other Dimensions.pdf) pulled toF:\Files from SRL system(removable media), plusWorkingFiles.zipand cloud-sync installers. - 8 USB devices, 60 internet RDP brute-force attempts (top source
213.202.233.104), and execution evidence (GoogleDriveFSSetup.exerun from USB,cmd.exeon the break-in night).
Every tool call lands in an audit trail (timestamp + the exact artifact it cited), and a live React dashboard narrates the whole investigation step by step.
How we built it
- Evidence prep (SIFT Workstation on a cloud VPS): mounted the E01 read-only, parsed the
$MFTinto a TSKflsbodyfile, ran Volatility 3 (pslist,cmdline,netscan) over the memory image, and pulled registry/log artifacts with RegRipper, python-evtx, and the Edge history (SQLite). - Deterministic forensic core (the oracle): Python extractors for timestomp ($SI/$FN pairing + false-positive suppression), a disk⇄memory "spine join," masquerade detection, and the self-correction engine. All the hard reasoning lives here, not in the model.
- The Custom MCP Server (FastMCP, stdio): 11 typed, read-only tools —
detect_timestomps,detect_masquerade,get_remote_access,get_usb_devices,get_web_activity,get_program_execution, … — each audited. The registry contains zero write/exec tools by construction. - The agent: an OpenAI-compatible ReAct loop on Cerebras
gpt-oss-120b, with retry/backoff for free-tier rate limits. It decides which read-only tool to call; the tools decide the truth. - Anti-leakage scoring:
run_case.pyis key-blind;score.pyis the only component that ever reads the ground-truth key. - Live dashboard: FastAPI + a single-file React UI (streaming "investigation console," contradiction cards, self-correction ladders, scoreboard, audit trail, and a real-case kill-chain timeline), served as a
systemdservice.
Challenges we ran into
- A truncated NTFS volume wouldn't mount — the filesystem declared ~6 sectors more than the image had, and the box had no
ntfs3kernel module. We fixed it with adm-linearzero-pad over a read-only loop device. - 157,536 timestomp "hits." A naive $SI-vs-$FN check drowns in false positives (null-
$SIcache files, installer clusters sharing one$SI). We added discrimination — null-$SIexclusion, cluster detection, user-writable gating, vendor build-vs-install logic — getting to 2 high-confidence with 0 FP. - A legitimate Adobe service almost got flagged. Tightening "confirmed" to require a large backdate or a user-writable path killed the last false positive.
- The honesty reckoning. Our flashy demo was on planted contradictions. Rather than blur that with the real case, we (a) labeled the planted part explicitly as validation, and (b) wrapped the real artifacts (RDP, USB, web, execution) as actual read-only MCP tools so the agent genuinely reconstructs the intrusion — instead of us claiming it did.
- The agent kept stopping early, declaring victory after the contradictions. We made calling the real-case tools a mandatory step before it's allowed to conclude.
Accomplishments that we're proud of
- Evidence integrity you can verify, not trust: the MCP surface exposes 0 write/exec tools — modification is impossible by design.
- 100% catch@final, 0 FP / 0 FN on blind-scored ground truth, with transparent miss→catch traces.
- A non-Claude, open-source model (
gpt-oss-120b) autonomously driving an entire forensic investigation through the MCP server. - We didn't stop at the planted demo — we reconstructed the real ROCBA kill chain (remote RDP → pivot → SharePoint-to-USB exfil) through the same audited, read-only tools.
- A runnable, self-narrating dashboard anyone can open and watch.
What we learned
- Permissions beat prompts. "Read-only" in a system prompt is meaningless if the toolset can write. Constrain the capability, and integrity becomes a property of the architecture.
- Single-source trust is the blind spot both timestomp and masquerade exploit — and cross-source corroboration ($SI vs $FN vs memory; name vs canonical path vs execution) is the cure.
- Put the hard logic in deterministic tools and let the model orchestrate. This made the system model-agnostic, cheap, and reproducible — the accuracy doesn't depend on the LLM.
- Forensic honesty matters. Separating measured claims (blind-scored) from interpretive ones (analyst-corroborated) makes the whole submission more credible, not less.
What's next for FindEvil: the DFIR agent that can't alter evidence
- More contradiction types: process hollowing (memory image path ≠ disk path), ghost/orphan processes (running in memory, gone on disk), and parent-process spoofing.
- More read-only tools: shellbags, Prefetch,
$UsnJrnl, full browser history, and anti-forensics detection (e.g., SDelete) — promoting today's analyst-corroborated threads into first-class tool findings. - Package it for real workflows: a drop-in read-only MCP server any DFIR analyst (or Claude Code) can point at an evidence mount — turning "trust me, I won't touch it" into a guarantee.

Log in or sign up for Devpost to join the conversation.