FindeskAI — Project Story Inspiration India has a ₹87 trillion formal credit market, yet the underwriting process at most NBFCs and banks looks almost identical to what it did in 2005 — a credit analyst manually pulling GST returns, reconciling bank statements, calculating ratios on Excel, and typing a Credit Appraisal Memo (CAM) from scratch. A single mid-market loan appraisal takes 3–7 working days, involves 4–6 people, and produces a document that is often inconsistent across analysts.
The trigger for FindeskAI was a conversation with a credit manager at a mid-sized NBFC in Pune. He showed me a stack of 23 pending appraisals — each a folder of PDFs, Excel sheets, and printed bank statements — and said: "The bottleneck isn't capital. It's bandwidth."
That stuck. The question became: what if a single analyst with AI could do in 30 seconds what a team does in 7 days?
I was also fascinated by how the DeFi ecosystem — Goldfinch, Credix, Maple Finance — was trying to unlock real-world credit on-chain, but lacked the rigorous off-chain underwriting layer to make it trustworthy. FindeskAI was built to be exactly that bridge: a credit intelligence engine that could serve both traditional lenders and on-chain liquidity pools.
What I Learned
- Multi-Agent AI is not a gimmick — it's genuinely better for credit decisions The most important insight was that a single LLM prompt produces overconfident credit recommendations. When I implemented the Hawk / Dove / Owl debate architecture (three agents with distinct risk mandates arguing to a synthesis), the output quality improved dramatically — the Owl (synthesis) agent caught contradictions the other two missed, and the structured disagreement surfaced nuances that a single-pass analysis buried.
This mirrors how real credit committees work: the RM is bullish, the risk team is bearish, and the CCO synthesises. The AI replicates the information structure of a committee, not just the conclusion.
- GST data is the most powerful underwriting signal in India that nobody is using properly The GST 3B vs 2A mismatch is essentially a free audit of declared revenue. The formula is simple:
GST Mismatch %= GSTR-3B Revenue ∣GSTR-3B Revenue−GSTR-2A Verified Revenue∣ ×100 A mismatch above 10% is a red flag. Above 20% is near-disqualifying. Yet most lenders accept the borrower's ITR at face value. Building the GST forensics module showed me that document cross-verification, not AI, is the hardest and most valuable part of underwriting.
- Benford's Law works — and it's underused in Indian credit Benford's Law states that in naturally occurring financial datasets, the leading digit d appears with probability:
P(d)=log 10 (1+ d 1 ) So digit 1 should appear ~30.1% of the time, digit 9 only ~4.6%. When I ran this against fabricated bank statement data, the distribution was immediately visually wrong — too many round numbers, too flat a distribution. The chi-squared test statistic:
χ 2 = d=1 ∑ 9
E d
(O d −E d ) 2
gave a p-value < 0.001, flagging fraud that would have been invisible to ratio analysis alone.
- Monte Carlo simulation gives credit risk a distribution, not a point estimate Traditional stress testing asks: "What if revenue falls 20%?" Monte Carlo asks: "Across 1,000 plausible futures, what is the probability distribution of outcomes?" The DSCR simulation uses:
DSCR simulated = Debt Service⋅(1+ϵ i ) Revenue⋅(1+ϵ r )⋅EBITDA%⋅(1+ϵ m )
where ϵ r ,ϵ m ,ϵ i ∼N(0,σ 2 ) are independent Gaussian shocks to revenue, margin, and interest rate respectively. Running 1,000 trials gives a full probability distribution:
P(Approve)= N ∣{DSCR≥1.25}∣ ,N=1000 This is far more honest than a deterministic stress scenario.
- Real cryptography is accessible in the browser The Web Crypto API (crypto.subtle.digest) lets you compute a genuine SHA-256 hash client-side with no library dependency:
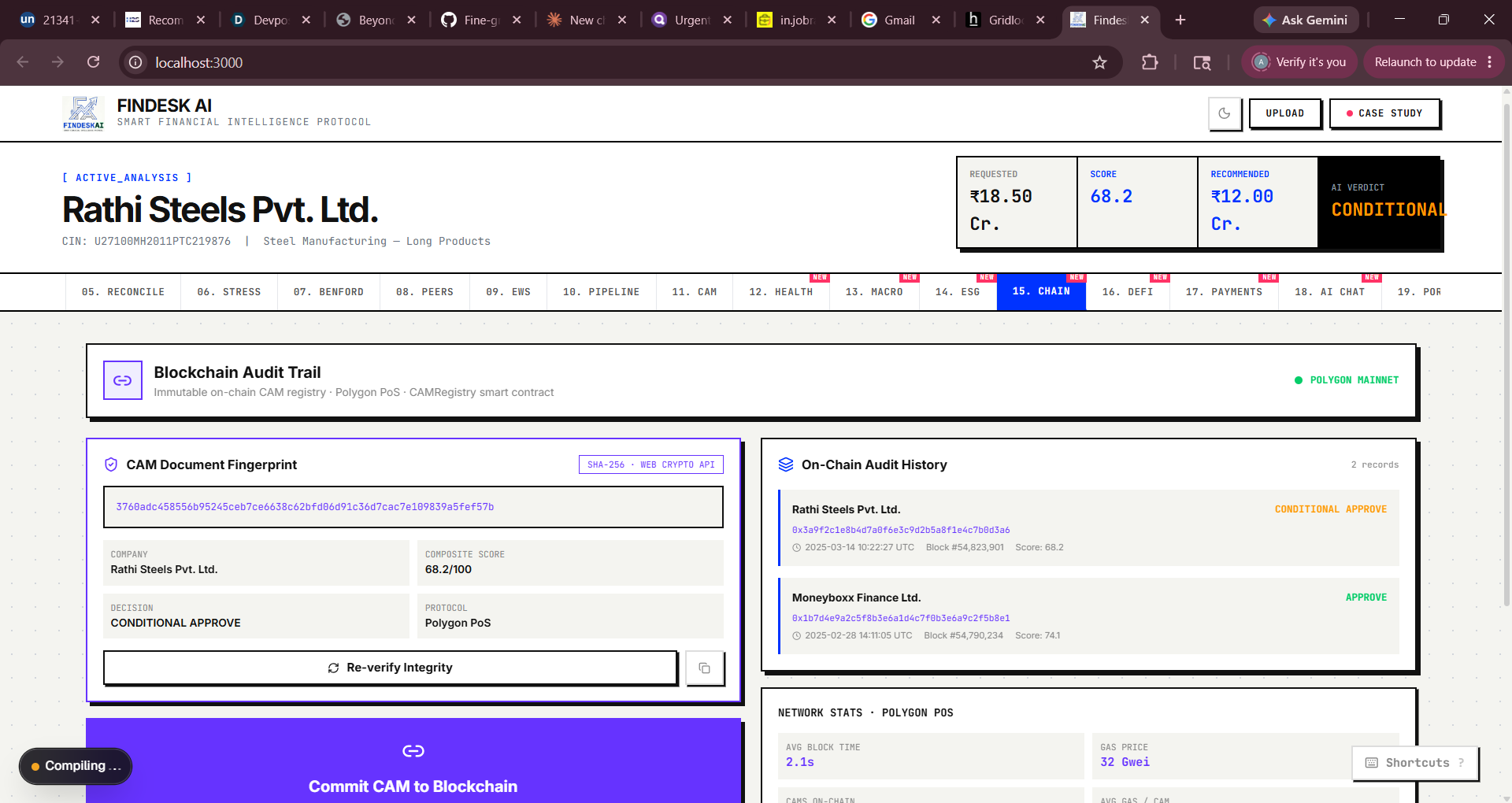
H=SHA-256(JSON.stringify(CAM payload)) Once this hash is committed to a smart contract, any subsequent tampering produces a different hash — making the audit trail cryptographically tamper-evident. I learned that blockchain's value in fintech isn't speculation; it's immutable state.
How I Built It Architecture
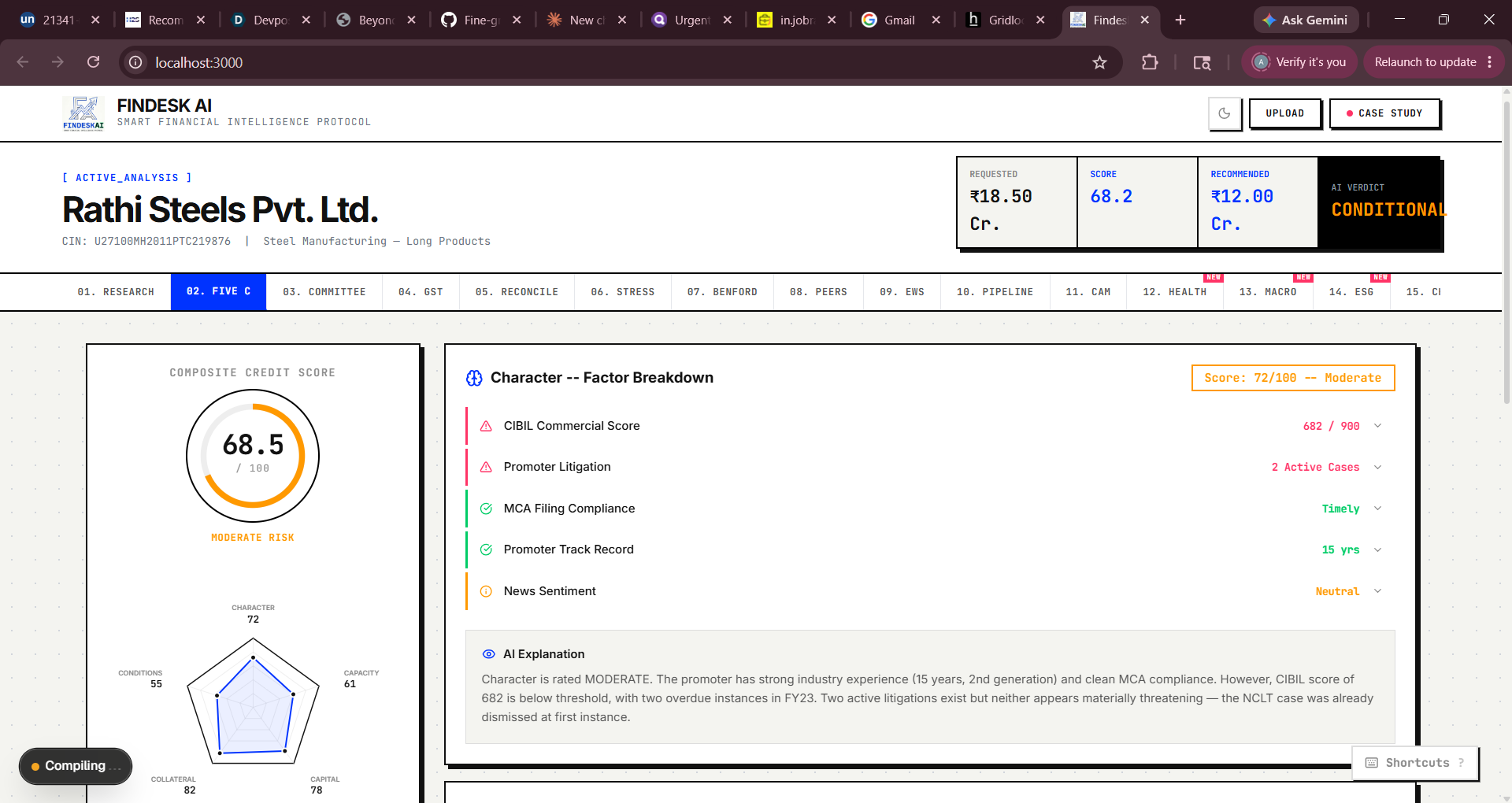
┌─────────────────────────────────────────────────────────┐ │ Next.js 16 App │ │ ┌──────────────┐ ┌─────────────┐ ┌────────────────┐ │ │ │ Upload + │ │AnalysisCtx │ │ 20 Tab │ │ │ │ Enrichment │→ │(React ctx) │→ │ Modules │ │ │ └──────────────┘ └─────────────┘ └────────────────┘ │ │ │ │ │ │ ↓ ↓ │ │ ┌─────────────────────────────────────────────────┐ │ │ │ API Routes (Next.js) │ │ │ │ /analyze /debate /research /generate-cam │ │ │ │ /sentiment /enrich │ │ │ └─────────────────────────────────────────────────┘ │ │ │ │ │ ↓ │ │ ┌──────────────────────────────────────────────────┐ │ │ │ External Services │ │ │ │ OpenAI GPT-4o │ Tavily Search │ FinBERT │ │ │ └──────────────────────────────────────────────────┘ │ └─────────────────────────────────────────────────────────┘ Build Phases Phase 1 — Core Credit Engine Started with the Five C scoring model, which computes a weighted composite:
S composite = i∈C ∑ w i ⋅s i ,C={Character, Capacity, Capital, Collateral, Conditions} with w i =0.20 for each pillar. Each pillar score is derived from ratio analysis, document flags, and LLM reasoning.
Phase 2 — Multi-Agent Debate Implemented the Hawk / Dove / Owl pattern using OpenAI's chat completion API with three system prompts encoding distinct risk mandates, then a synthesis pass.
Phase 3 — Forensics Modules Built GST mismatch detection, Benford's Law chi-squared test, and bank statement reconciliation — all computed client-side or server-side without external data dependencies.
Phase 4 — Web3 Extension
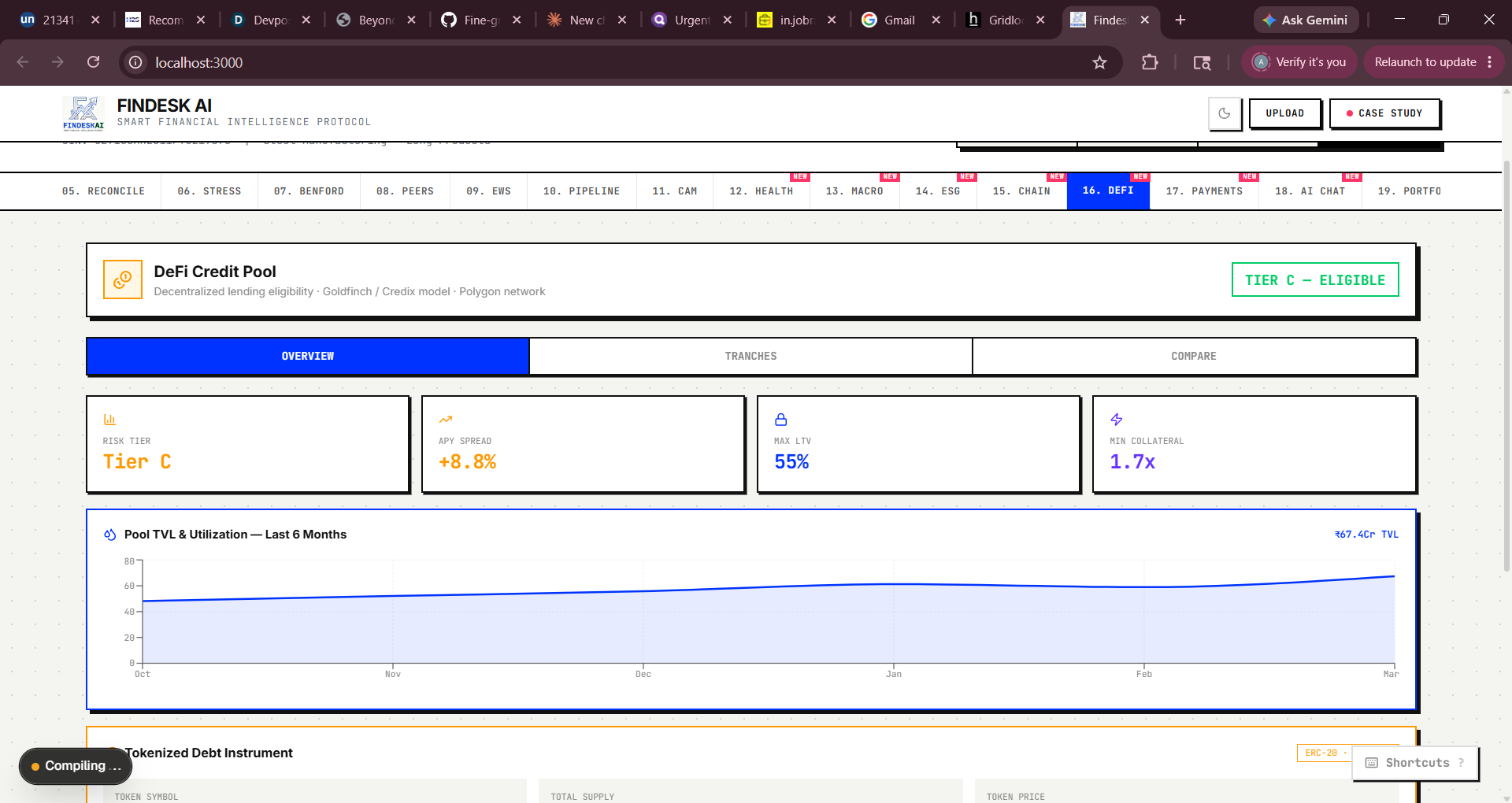
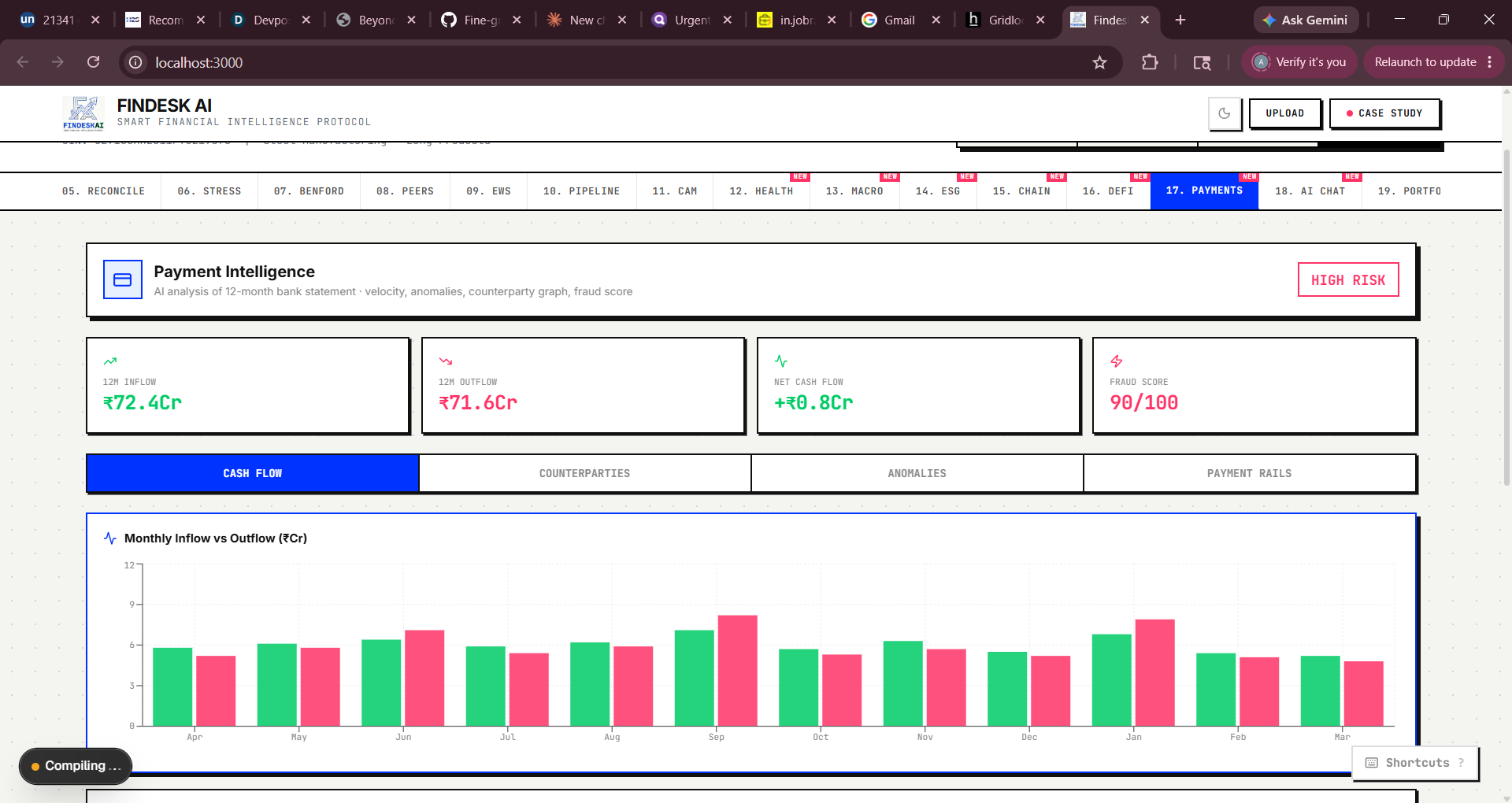
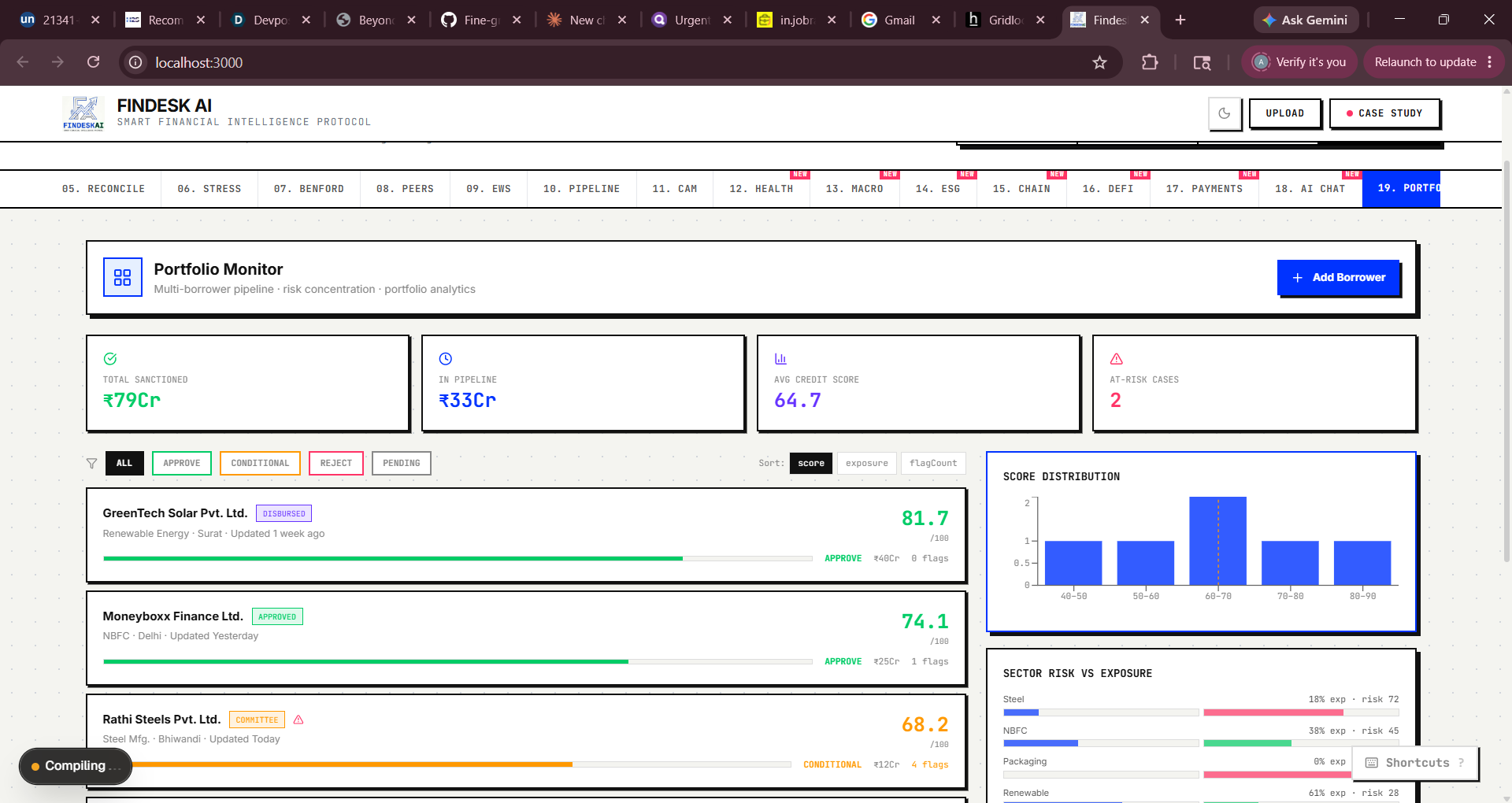
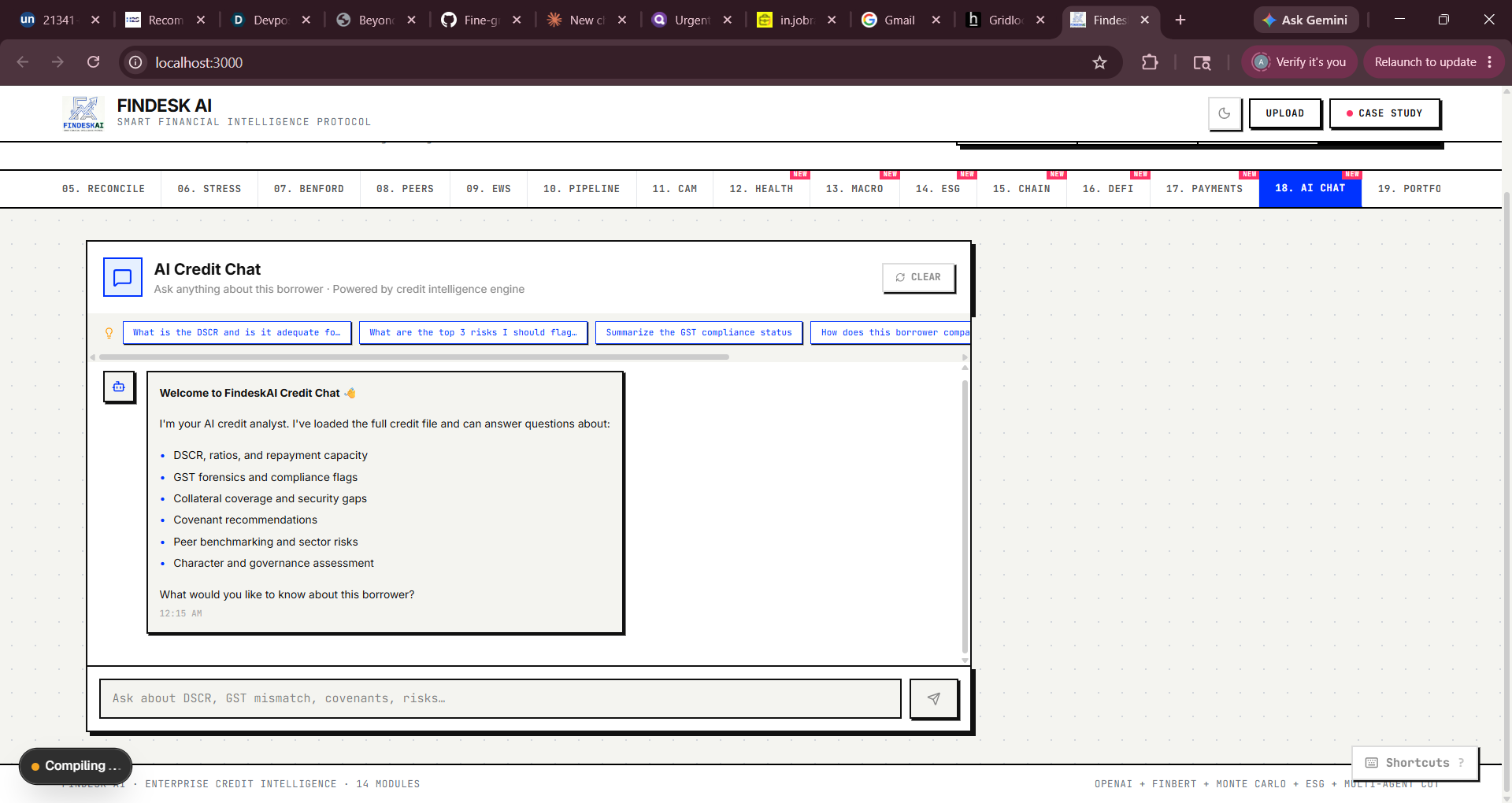
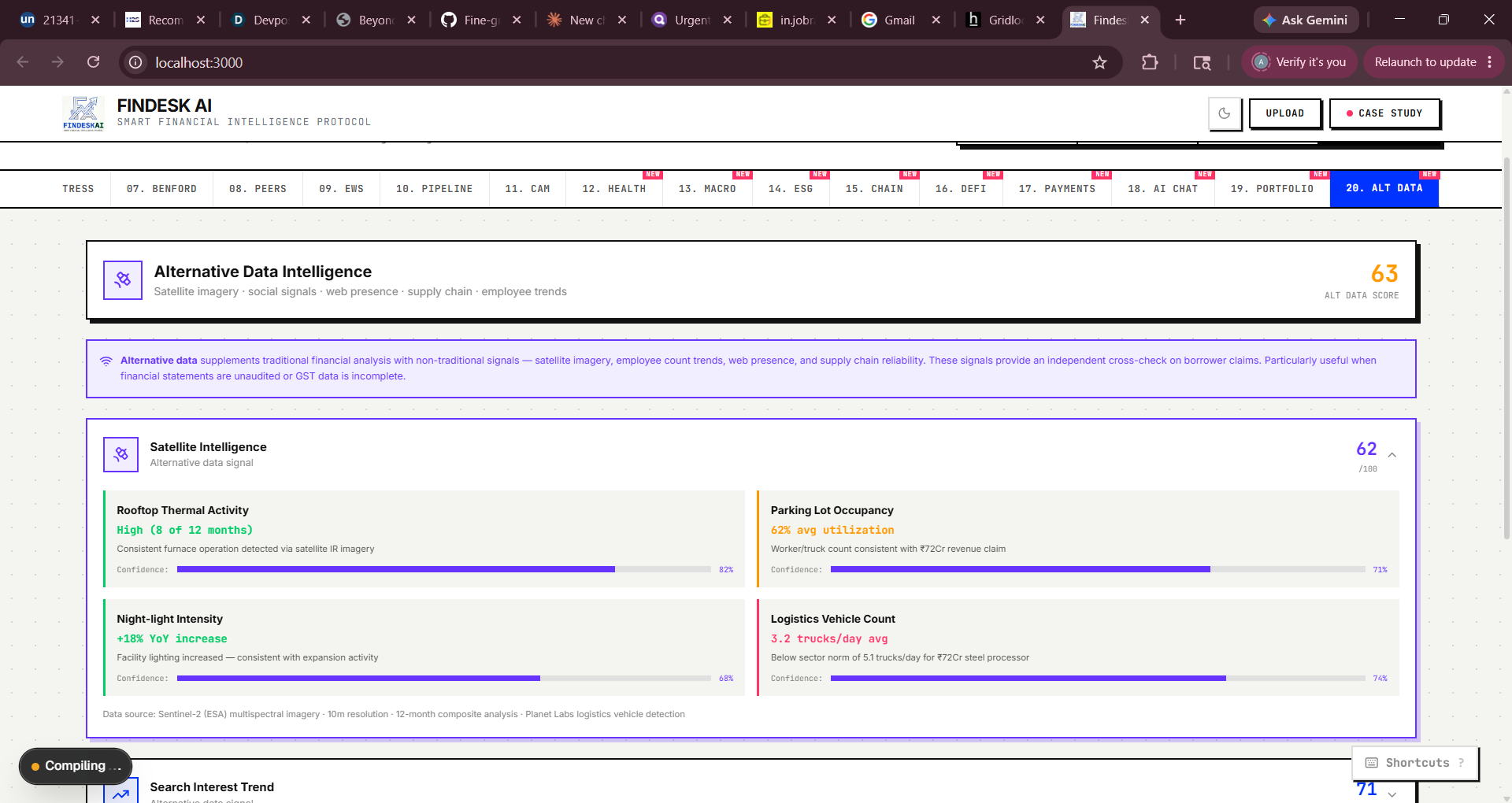
Blockchain Audit: Real SHA-256 via crypto.subtle, simulated Polygon txn with CAMRegistry.sol ABI display DeFi Pool: Score-to-terms engine mapping composite score → APY spread, LTV, tranche structure Payment Intelligence: Fraud scoring engine with 6 weighted factors Phase 5 — Intelligence Expansion Added AI Credit Chat (deterministic rule engine), Portfolio Monitor, Alternative Data (satellite, social, web signals), Macro Feed, ESG/BRSR scoring, and Financial Health Score.
Challenges Challenge 1: Making AI credit output structured and auditable Early versions returned free-form LLM text that looked impressive but was useless for a credit committee — no numbers, no citations, no reproducibility. The fix was to enforce strict JSON output schemas and post-process every response through a scoring model that validated ranges and flagged hallucinations. This added latency but made the output trustworthy.
Challenge 2: The GST mismatch problem has no clean API There is no public API for GSTR-2A data in India. The module simulates cross-verification using the mathematical relationship between 3B (self-declared) and 2A (counterparty-reported) data, with configurable mismatch thresholds. Building this made clear that the real product moat is data access, not the AI layer.
Challenge 3: Streaming AI responses without overwhelming the UI The debate module streams three agents simultaneously. Managing concurrent ReadableStream objects in Next.js App Router, merging them into a coherent UI state without race conditions or dropped tokens, required careful use of TransformStream and client-side event source parsing.
Challenge 4: Monte Carlo at 1,000 runs without blocking the main thread Running 1,000 simulation iterations synchronously froze the UI for ~200ms on lower-end devices. The solution was to batch the simulation into 100-iteration chunks using setTimeout(fn, 0) to yield control back to the browser between batches, keeping the UI responsive throughout.
Challenge 5: DeFi terms that are actually defensible It was easy to hardcode "APY = 12%" for any borrower. Making the DeFi terms derivable from first principles required building a proper risk-to-spread model:
APY Spread=r f +λ⋅(1−Recovery Rate)⋅PD where PD≈ 100 100−S composite
and Recovery Rate ≈0.45 for unsecured SME lending. This gave the DeFi pool module economic credibility rather than arbitrary numbers.
Built With Core Framework Next.js 16 (App Router, Turbopack) — full-stack React framework TypeScript — end-to-end type safety across 66 source files React 19 — UI component layer Styling Vanilla CSS — custom brutalist design system (globals.css) JetBrains Mono — monospace font for financial data Inter — primary UI typeface Data Visualisation Recharts — AreaChart, BarChart, RadarChart, LineChart, PieChart, ScatterChart AI / ML OpenAI GPT-4o — Five C analysis, credit committee debate, CAM generation, research summarisation FinBERT (via HuggingFace) — financial sentiment analysis on news and filings Tavily Search API — real-time web research for borrower intelligence Cryptography & Web3 Web Crypto API (crypto.subtle.digest) — real SHA-256 CAM hashing Solidity (display) — CAMRegistry.sol smart contract ABI Polygon PoS (simulated) — on-chain CAM commit and audit trail Icons & UI Lucide React — icon system (20+ icons used) APIs & Data Sources OpenAI API — GPT-4o completions with streaming Tavily API — web search for research agent RBI / MoSPI (mock) — macro data (repo rate, CPI, G-Sec, USD/INR) MCA21 — company registration data Architecture Patterns React Context API — AnalysisProvider for cross-tab state sharing Server-Sent Events (SSE) — streaming AI responses via text/event-stream Token-bucket rate limiting — per-IP rate limiting on all AI routes Web Crypto API — client-side cryptographic hashing DevOps GitHub — version control and code hosting npm — package management (163 packages) ESLint — code quality Mathematics Used Benford's Law — P(d)=log 10 (1+1/d) for fraud detection Monte Carlo simulation — Gaussian noise injection for stress testing Herfindahl-Hirschman Index — portfolio concentration measurement Chi-squared test — statistical significance of Benford deviations SHA-256 — cryptographic document fingerprinting
Built With
- 16
- api
- crypto
- finbert
- gpt-4o
- lucide
- next.js
- openai
- polygon
- pos
- react
- recharts
- solidity
- tavily
- typescript
- vanilla
- web


Log in or sign up for Devpost to join the conversation.