

Inspiration
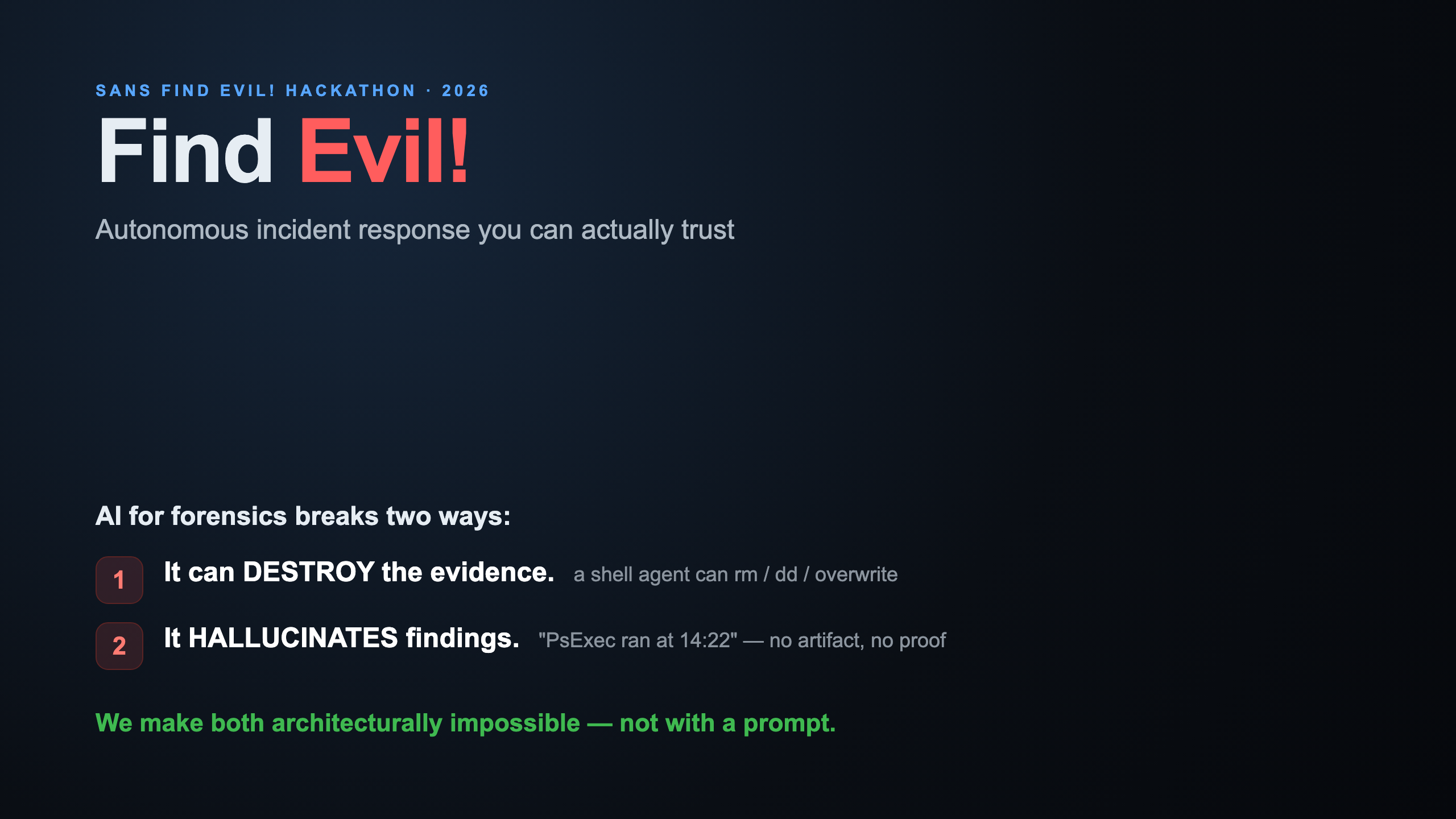
AI-powered attackers move in minutes. The obvious fix — point an AI agent at a forensic workstation — breaks two ways that make it unusable for real casework: the agent can destroy the evidence it's analyzing (an agent with a shell can rm, dd, or overwrite a disk image), and it hallucinates findings you can't verify ("PsExec ran at 14:22" — no artifact, no proof). In a real incident, an unverifiable finding is worse than no finding: it wastes the one thing you don't have at 3 AM — analyst time. We built Find Evil! to prove both problems are solvable architecturally, not with a longer prompt.
What it does
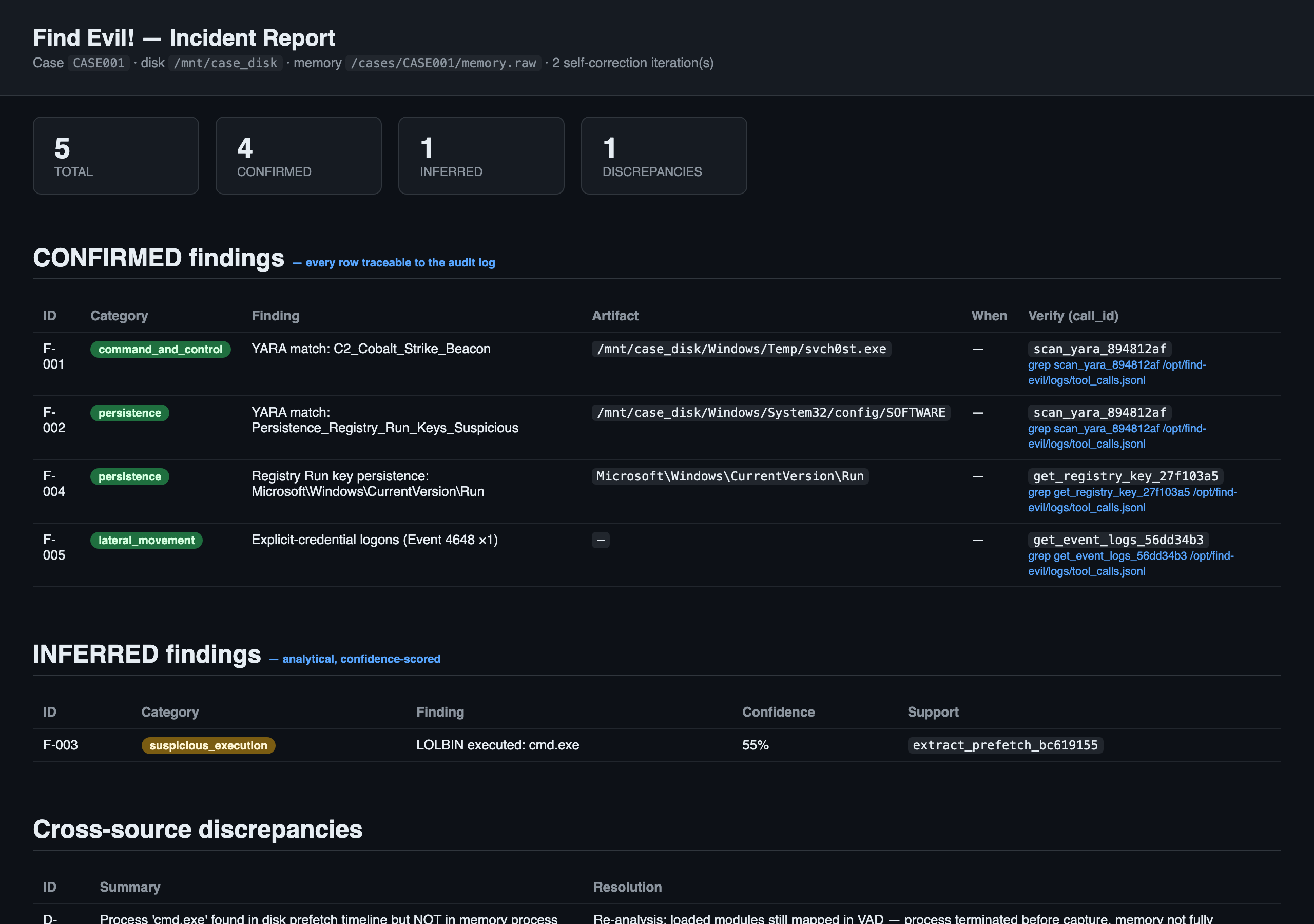
Find Evil! is an autonomous incident-response agent for the SANS SIFT Workstation. Point it at a mounted disk image (and optionally a memory dump) and it runs a six-phase analysis the way a senior analyst does — triage, timeline, memory, artifacts, correlation, report — sequencing tools, recognizing anomalies, and self-correcting.
It runs in two modes: a deterministic, reproducible pipeline (court-defensible — the same case always runs the same way), and an autonomous mode where a Claude model drives the investigation: choosing the next tool from what it has found, narrating its reasoning, forming and testing hypotheses. The crucial property: the architectural guarantees hold in both modes.
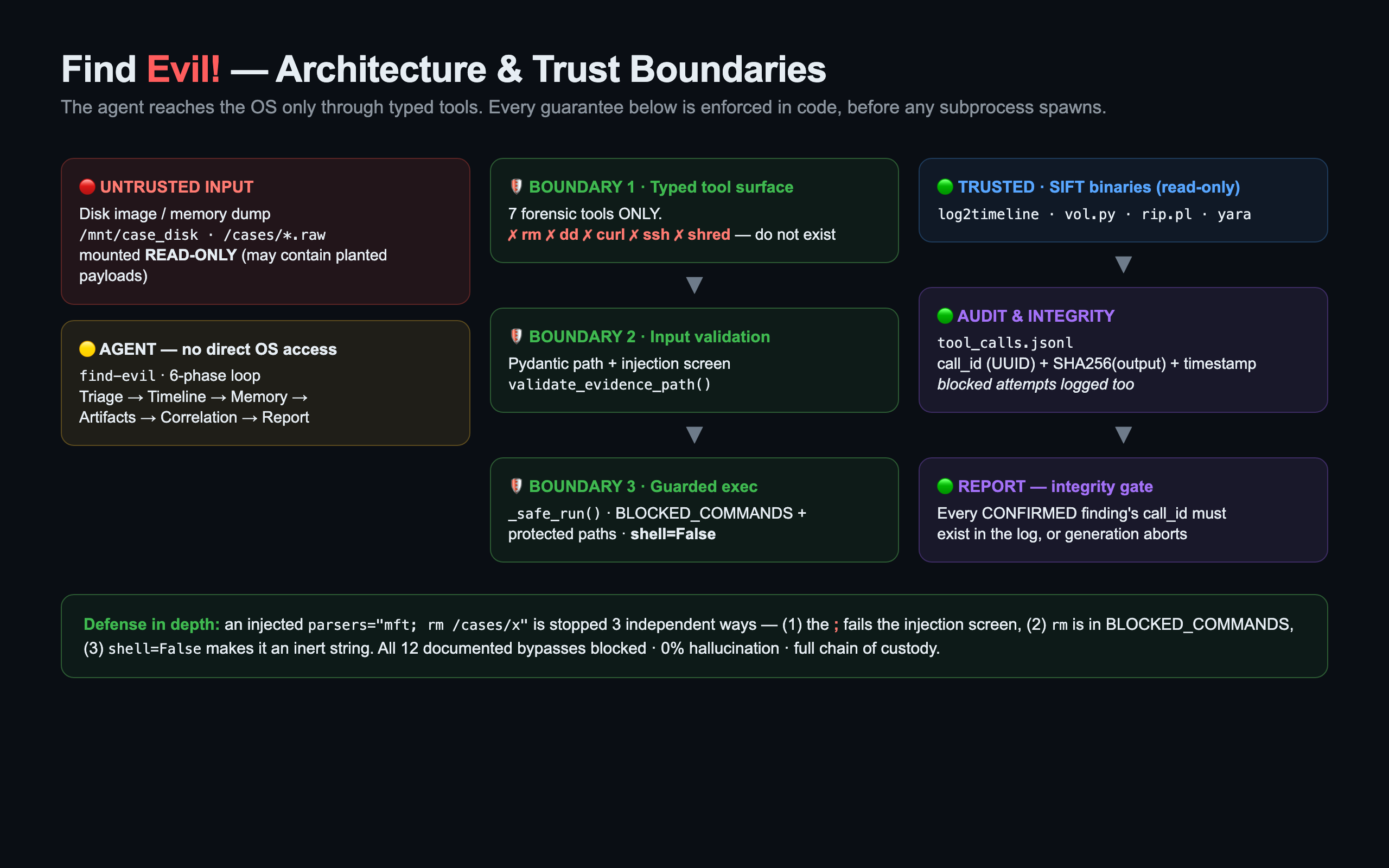
Two things are made architecturally impossible:
- Evidence tampering — the agent has no shell.
rm,dd,curl,sshdo not exist in its tool surface; destructive/exfil commands are blocked in code before any process spawns. - Hallucinated findings — every CONFIRMED finding must carry a tool
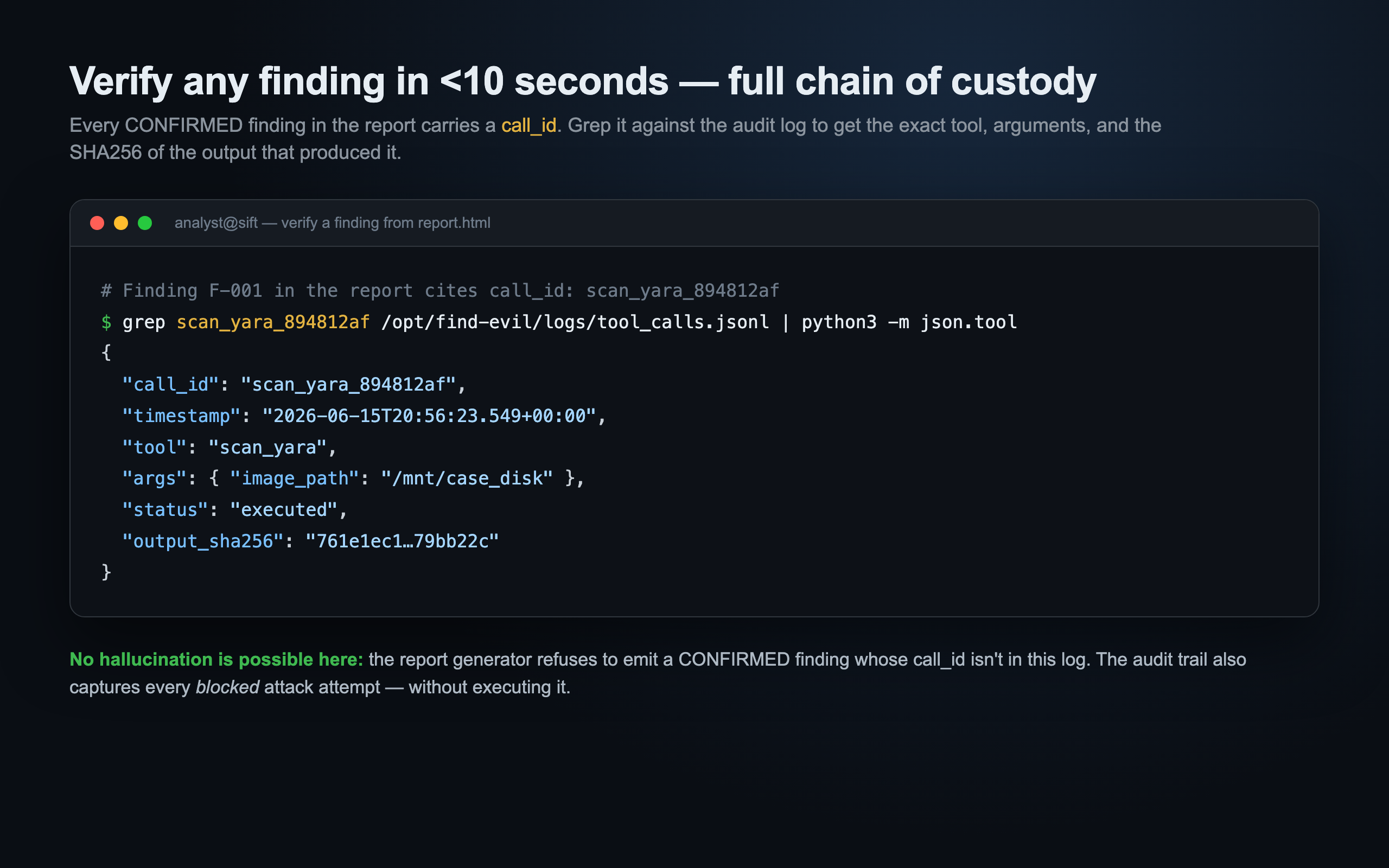
call_idpresent in the audit log, or the report refuses to generate it. 0% hallucination in the CONFIRMED tier, by construction.
Any finding can be verified in under 10 seconds: grep its call_id against the audit log and get the exact tool, the exact arguments, and the SHA256 of the output that produced it. Full chain of custody.
How we built it
- Language: Python 3.11
- Tool layer: a custom MCP server (FastMCP) exposing 10 typed forensic tools wrapping SANS SIFT tooling — log2timeline/plaso, Volatility 3 (pslist/malfind/netscan), RegRipper, YARA, plus timestomping detection ($STANDARD_INFORMATION vs $FILE_NAME).
- Guardrails: a single
_safe_run()chokepoint runs every command withshell=False; Pydantic validates every path; aBLOCKED_COMMANDS/PROTECTED_WRITE_PATHSlist rejects destructive/exfil actions and writes to evidence paths — all before a subprocess spawns. - Agent: a deterministic 6-phase orchestrator with bounded self-correction, plus an autonomous Claude-driven mode (manual tool-use loop) that keeps the same audited tool surface.
- Integrity: an append-only JSONL audit log; every tool call (executed or blocked) gets a UUID and a SHA256 of its output. The report generator rejects any untraceable CONFIRMED finding.
- Quality bar: 56 automated tests + a reproducible accuracy benchmark that runs with no evidence required.
Challenges we ran into
- Injection through tool arguments, not just the command line — e.g.
parsers="mft; rm /cases/x". Solved with argument-level screening plusshell=False, so even an unscreened payload is an inert string. - Keeping integrity under an autonomous LLM. When a model drives tool selection, what stops it confirming a finding it can't prove? Our answer: the report generator verifies every CONFIRMED
call_idagainst the audit log — we have a test proving an LLM-inventedcall_idis rejected. Full autonomy, zero loss of integrity. - Defining "hallucination" rigorously enough to enforce in code: traceability to a logged
call_id, checked at report-generation time, not at prompt time. - Resisting the temptation to fake demo numbers. We built a synthetic, fully-known dataset instead, so the metrics are real and reproducible.
Accomplishments that we're proud of
- 12 documented bypass attempts (injection, command-chaining, exfiltration, prompt injection) — all blocked, each turned into a passing regression test.
- A 0%-hallucination guarantee that's mechanically enforced, not promised — and that holds even when an autonomous LLM is in control.
- A report where any finding is verifiable in under 10 seconds via its
call_id. - 56 passing tests, 10 typed forensic tools, and a one-command install.
What we learned
- Architectural constraints beat prompt-based ones. "The agent can't run
rm" is only true if the capability doesn't exist — telling a model not to is not a control. - Autonomy and safety aren't a trade-off if the safety is structural: we gave a reasoning LLM full control of the investigation and it still can't tamper or fabricate.
- For forensics, traceability is the product. A finding you can't grep back to a tool call is, for an analyst, indistinguishable from a guess.
What's next for Find Evil!
- macOS/Linux artifact phases (currently Windows-focused).
- Encrypted-volume handling when keys are available.
- A web UI over the existing JSON report + audit log. ```
After pasting, change the last header from "What's next for Untitled" to "What's next for Find Evil!" (Devpost auto-fills your project name there).
Built With
- anthropic-claude
- fastmcp
- log2timeline
- mcp
- plaso
- pydantic
- pytest
- python
- regripper
- sans-sift
- volatility3
- yara

Log in or sign up for Devpost to join the conversation.