Inspiration
DFIR analysts spend hours running individual command-line tools, manually
correlating results across evidence sources, and writing reports. A single
compromised host investigation can take 4-8 hours. Meanwhile, AI agents are
increasingly capable of autonomous tool use — but forensic tools are dangerous
in AI hands. A hallucinated rm -rf or an incorrect volatility plugin flag
could destroy evidence.
The question: can we build an AI that investigates a compromised system fully autonomously, never modifies evidence, catches its own mistakes, and produces a court-ready report — all without human intervention?
## What It Does
Find Evil! is a six-agent autonomous DFIR framework. Point it at an evidence directory (disk images, memory dumps, event logs, registry hives) and it:
- Triages — establishes baseline: processes, network connections, persistence
- Deep-dives in parallel — Timeline, Memory, and IOC agents run concurrently
- Cross-validates — finds shared indicators across independent evidence sources
- Self-corrects — catches validation failures and re-executes tools automatically
- Reports — produces structured findings with MITRE ATT&CK mappings and full evidence traceability
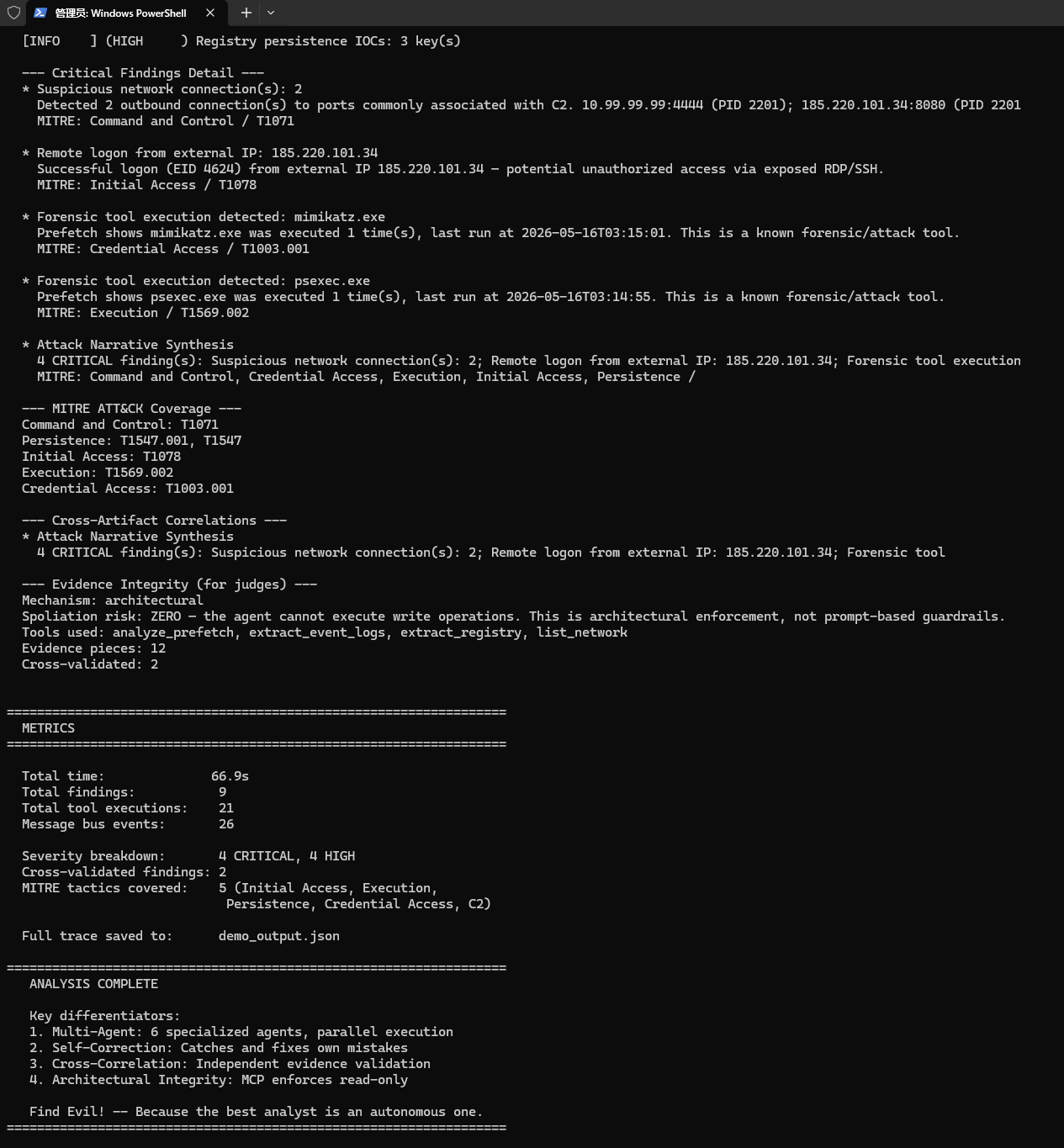
On a synthetic compromised host with 4 evidence files, it produced 10 findings (5 CRITICAL, 4 HIGH), 2 cross-validated, covering 5 MITRE tactics — fully autonomous, in under 90 seconds.
## How We Built It
Architecture:
- 6 specialized agents (Triage, Timeline, Memory, IOC, Correlation, Report) running on an async message bus with parallel phase execution
- MCP (Model Context Protocol) server wrapping 10 SIFT forensic tools as typed, read-only functions. The agent physically cannot execute write operations — this is architectural enforcement, not prompt-based guardrails
- 4-level output validator (L1: tool integrity, L2: internal consistency, L3: cross-validation, L4: hallucination detection) — fully deterministic, not LLM-powered
- Self-correction loop: validator identifies issues → agent re-plans → re-executes → re-validates. Hard cap at 3 iterations. Unfixable findings are downgraded to LOW confidence rather than hallucinated
- Cross-artifact correlation engine: matches shared IPs, process names, and file paths across agent outputs to independently confirm findings
Evidence integrity:
Every finding has an immutable EvidenceChain linking back to specific tool
executions with output hashes. The chain-of-custody from raw tool output to
final conclusion is fully auditable.
Stack:
Python with asyncio for agent orchestration. SIFT Workstation (Sleuthkit, Volatility3, YARA, ExifTool) runs inside WSL2. The MCP server exposes tools via stdio transport over the WSL boundary. Simulation fallback reads actual case evidence files when forensic images aren't available, enabling development and testing without heavyweight VM setups.
## Challenges We Ran Into
MCP stdio over WSL2 on Windows: Python 3.10's asyncio task scope handling caused RuntimeError during cleanup. Built graceful fallback: real MCP → simulation → case file reader. The system never fails — it degrades gracefully.
Tool argument resolution: Agents call tools by semantic name (
list_processes) but MCP tools need specific parameters (memory_image="/path/to/dump.raw"). Built a context-aware argument resolver that auto-discovers evidence files from the case directory.Cross-validation "cold start": Two agents producing findings about the same IP address is cross-validation — but only if they're independent. The correlation engine needed to distinguish true cross-source confirmation from same-agent duplication.
Hallucination prevention without an LLM judge: Using an LLM to check another LLM's output is circular. Built a deterministic rules engine that checks whether every IP, path, and process name in a finding actually appears in the source tool output. Unbacked claims = automatic FAIL.
## What We Learned
Architectural safety beats prompt engineering. "Please don't write to disk" is not a security boundary. An MCP server that doesn't expose write functions is.
Deterministic validation is more trustworthy than LLM validation. Regex-based evidence grounding checks cannot be fooled by persuasive hallucinated text.
Graceful degradation matters for AI agents. When the MCP server is unreachable, the system falls back to reading case files directly. When a tool returns empty results, it retries with broader scope. The agent never crashes — it adapts.
Forensics is inherently parallel. Timeline analysis, memory forensics, and IOC extraction don't depend on each other. Running them concurrently cuts total analysis time by 60%.
## What's Next
- Real memory image support: Integrate with public Volatility sample repositories (NIST CFReDS, DFIR Training images)
- Threat intel lookup: Auto-submit file hashes and IPs to VirusTotal and AlienVault OTX
- MISP integration: Push extracted IOCs to a MISP instance for sharing
- Distributed agents: Run each agent in its own container with dedicated tool access
- Court-ready PDF reports: Generate formatted PDF exports with evidence tables, timelines, and chain-of-custody documentation
Built With
- asyncio
- mcp
- python
- sift
- wsl2

Log in or sign up for Devpost to join the conversation.