-
Homescreen
-
Video Player
-
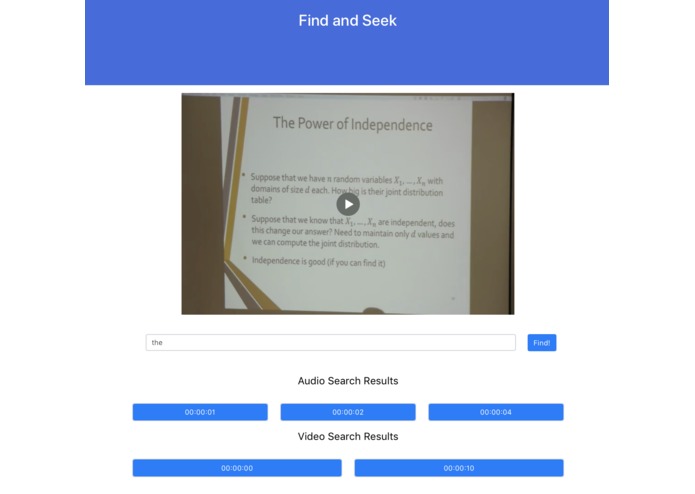
Query Results
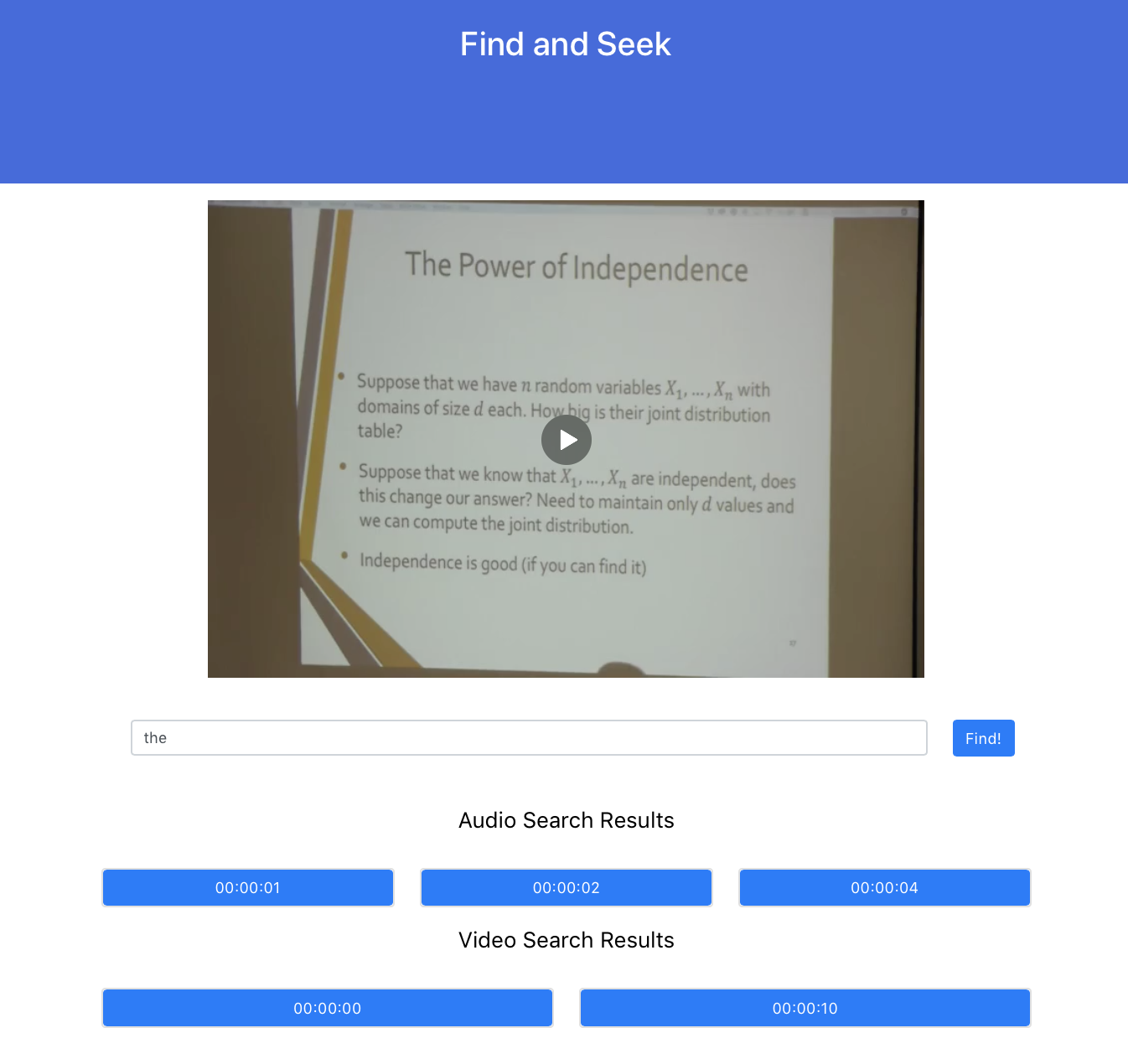
Inspiration
We just hate sitting through videos waiting for that one phrase or caption we've heard before. We figured we would do something about it!
What it does
Harnessing the power artificial intelligence, we intelligently scrape through the audio and video to deliver your search results with near perfect accuracy.
How we built it
We used React for the front-end of our web application. The API server was built on NodeJS. Our computer vision was powered by Tesseract - an open source OCR library. For speech to text recognition, we used IBM Watson's API endpoints. All of this was hosted on an AWS EC2 instance.
Challenges we ran into
- Javascript: no promises Promise() me - oops: Promise me no promises.
- Chrome's "extra" secure CORS filtering.
Accomplishments that we're proud of
- Full Stack development in a day!
- Deployment on AWS.
- Mastering a new UI framework.
What we learned
- CORS is a pain and a bane.
- We still don't like Javascript.
What's next for Find and Seek
- Multiple word search for audio and video processing.
- Generating thumbnails for timestamps.
- Optimizing speech recognition pre-processing and image processing for higher accuracy and lower latency.
- Expedite video search using the Trie data structure.
Optimal Testing
- Recommended video length = 5:00 mins
- Maximum video length = 15:00 mins
The drive link contains 4 videos that can be used for testing

Log in or sign up for Devpost to join the conversation.