-
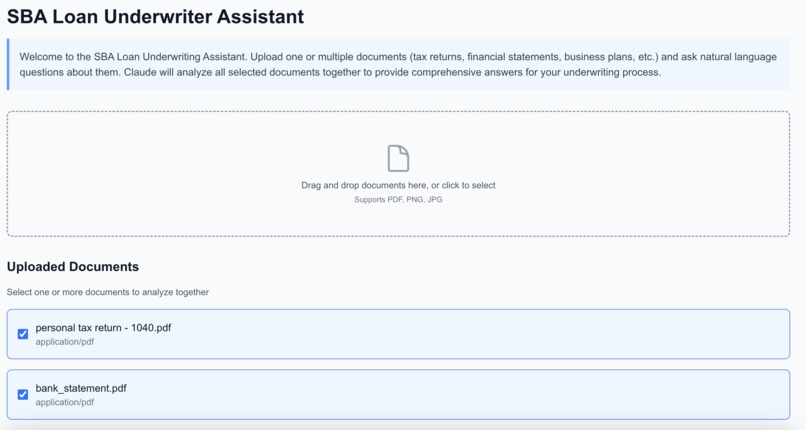
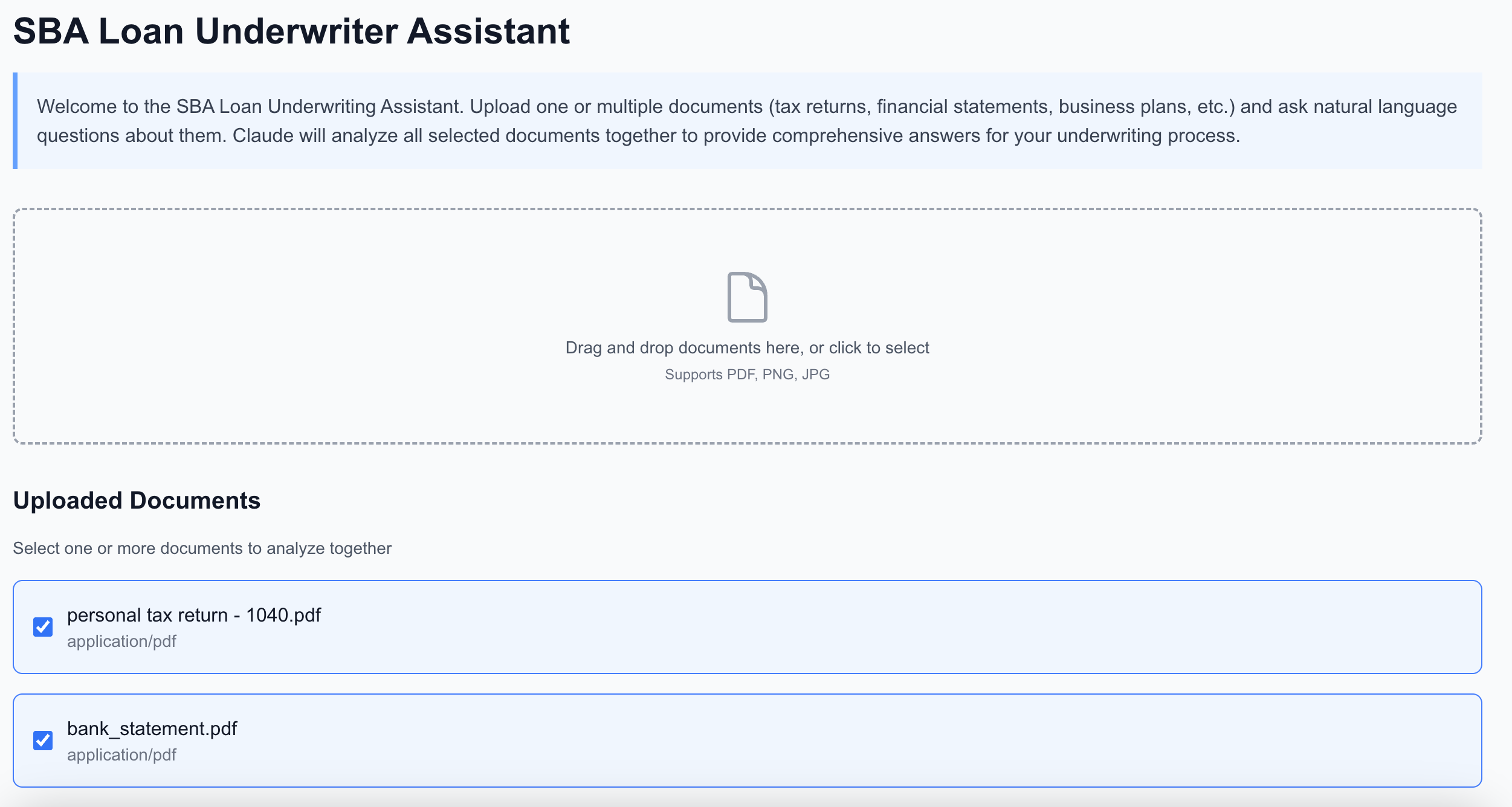
Upload as many financial docs as you want for OCR pipeline
-
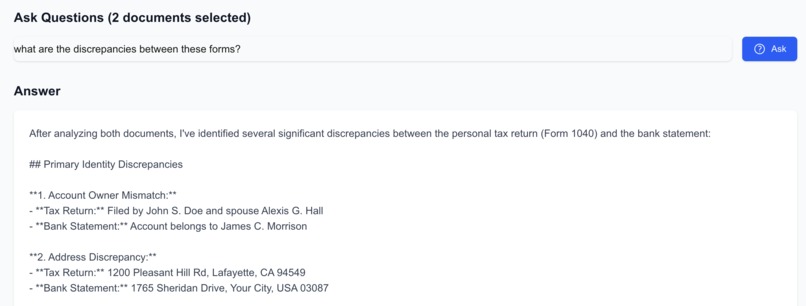
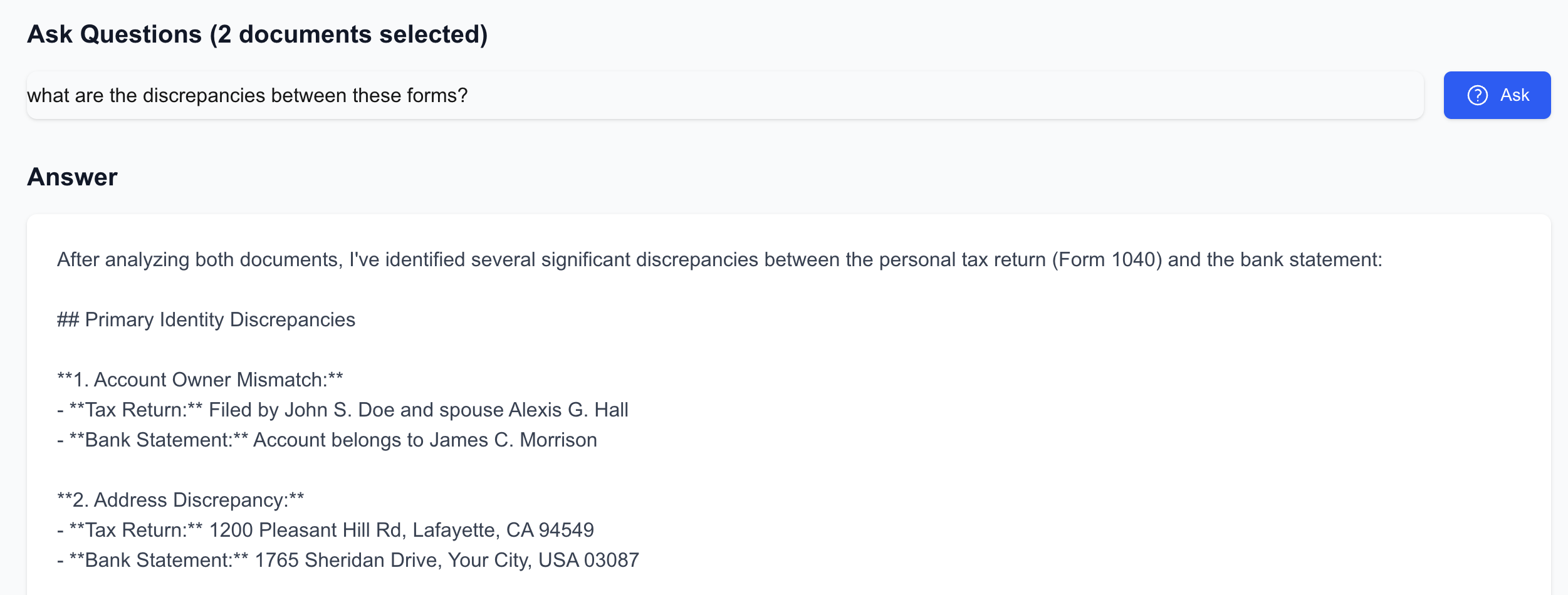
Ask questions in natural language
-
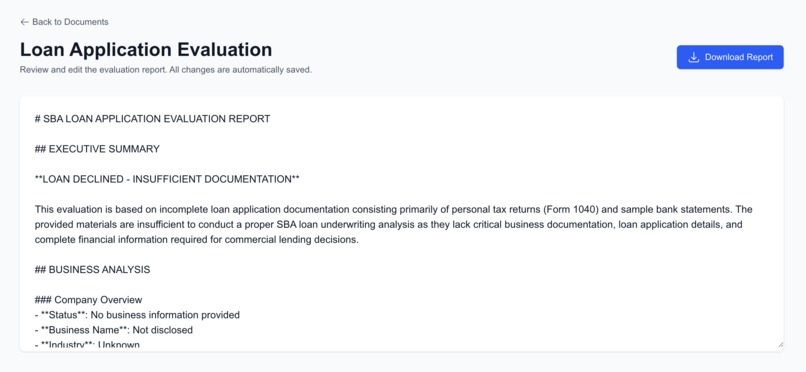
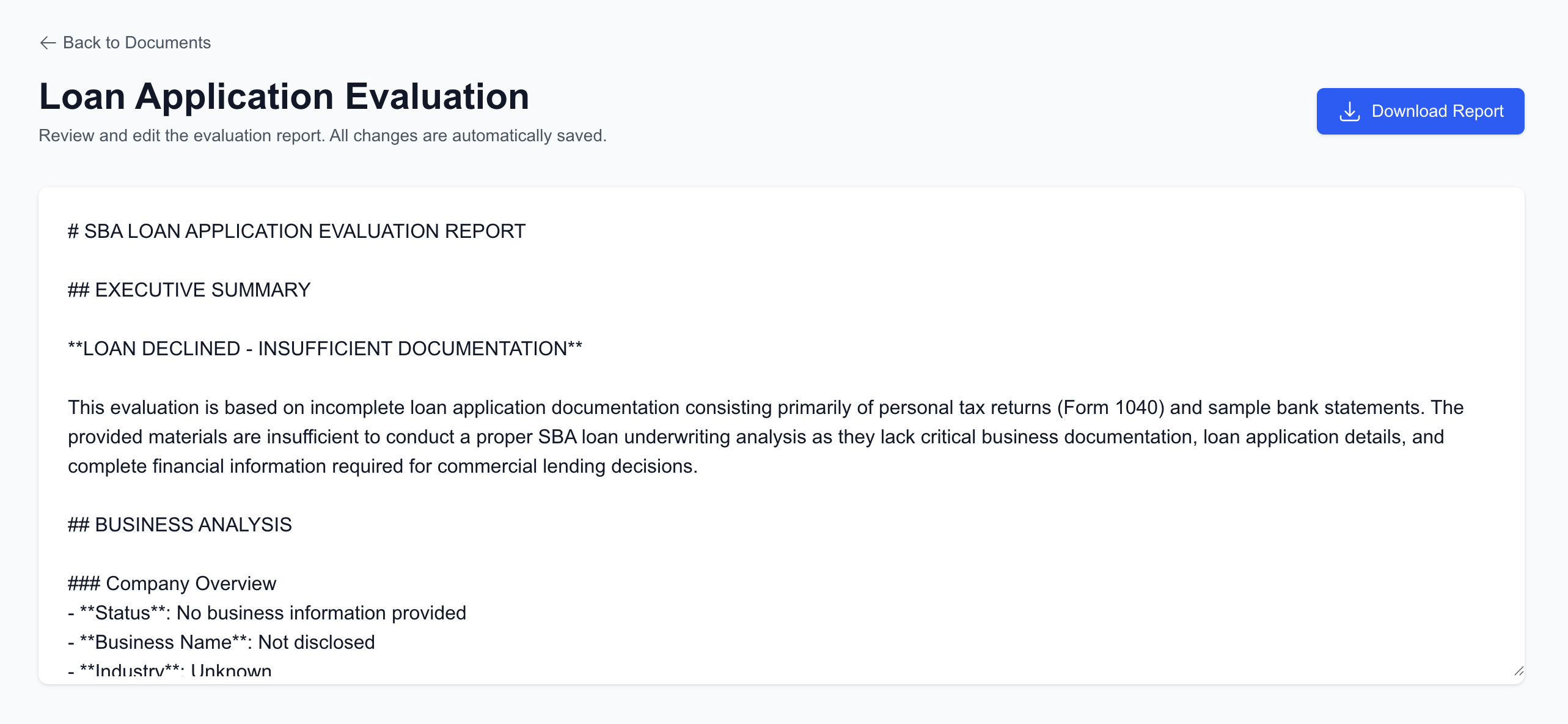
Generate a loan application report
Inspiration
While preparing for an interview with a fintech startup, I wanted to deeply understand their space. I discovered that small business loan underwriting is still heavily manual, relying on tedious document review. I thought: what if I could use LLMs and retrieval-augmented generation (RAG) to accelerate that process? That question led me to build this prototype system to assist underwriters in evaluating SBA loan applications.
What it does
This tool allows a loan underwriter to upload financial documents like tax returns, bank statements, and payroll reports. It extracts text from the documents using OCR, stores it in a vector database, and enables intelligent question-answering and report generation using a Claude-powered RAG pipeline. The user can also generate a structured underwriter evaluation draft, editable before export.
How I built it
Backend:
- FastAPI
- OCR: Tesseract + pdf2image for PDF-to-image conversion
- LLM: Claude via the Anthropic API
- Vector DB: ChromaDB with default embedding model (all-MiniLM-L6-v2)
Frontend:
- Next.js
Architecture:
- PDF Uploads -> OCR w/ tesseract converts into text
- Text is stored as embeddings in ChromaDB
Challenges I ran into
- Understanding what a real underwriter evaluation report looks like
- Managing long input contexts and keeping the system fast and responsive
Accomplishments that I'm proud of
- works as intended!
What I learned
- OCR-RAG-LLM integrations!
What's next for Financial Document MCP-RAG System
- chunking up the text instead of writing it all completely
- custom embedding model instead of default embedding, to support semantic search instead of just normal embedding
- having the LLM be able to highlight places in the pdf
Built With
- chromadb
- claude
- fastapi
- next.js
- ocr
- python
- rag
- tesseract
- typescript

Log in or sign up for Devpost to join the conversation.