Inspiration
Our inspiration for building Fin came from the recent stock movements of apple and the recent responses to Facebook's privacy policies. It was clear that there was a correlation between stock movement and the media coverage that big tech companies get. This lead to the idea that a machine can read headlines faster than a human can, thus we have a higher alpha than normal humans when it comes to looking at stock movements purely based on news coverage.
What it does
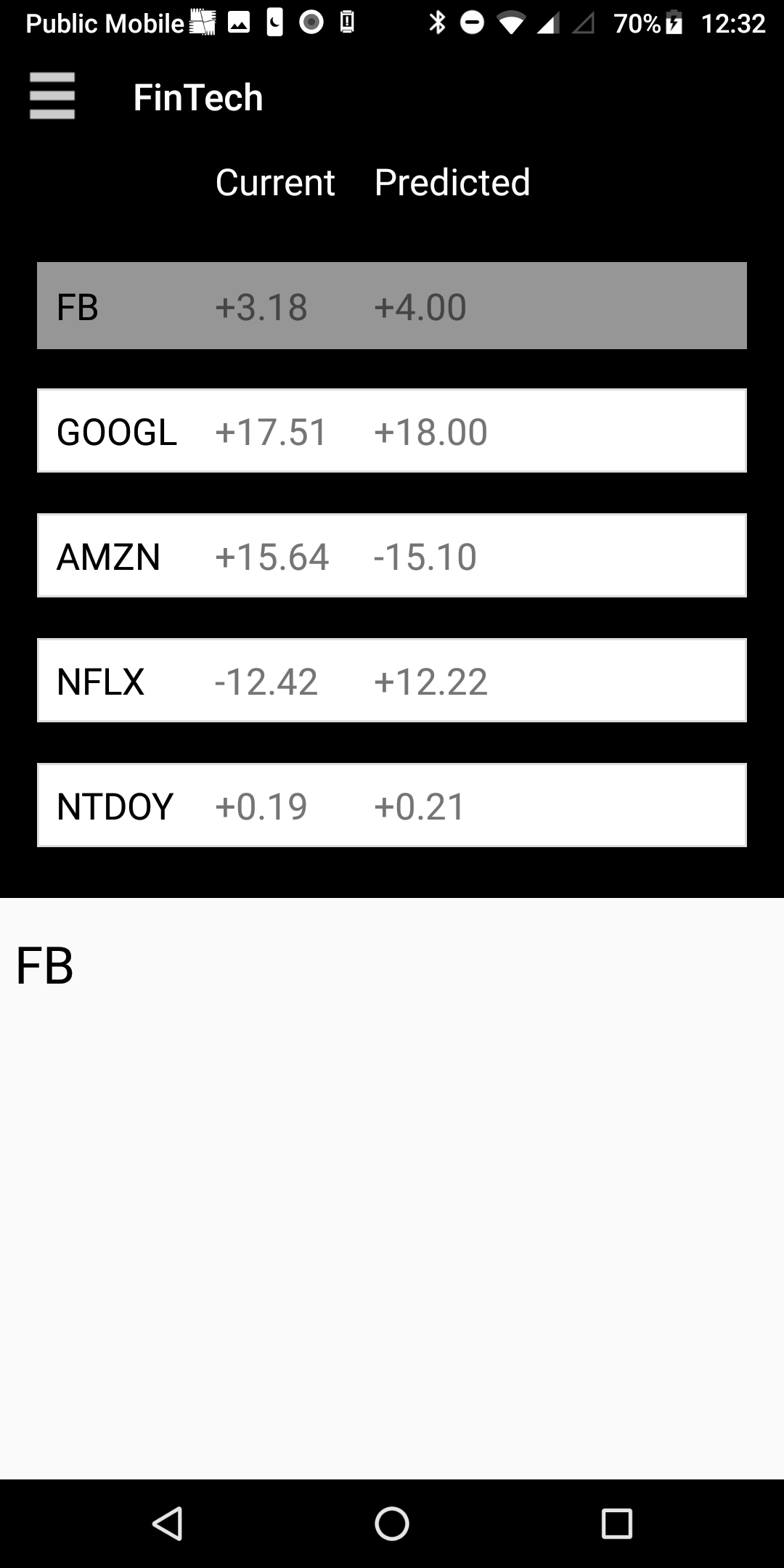
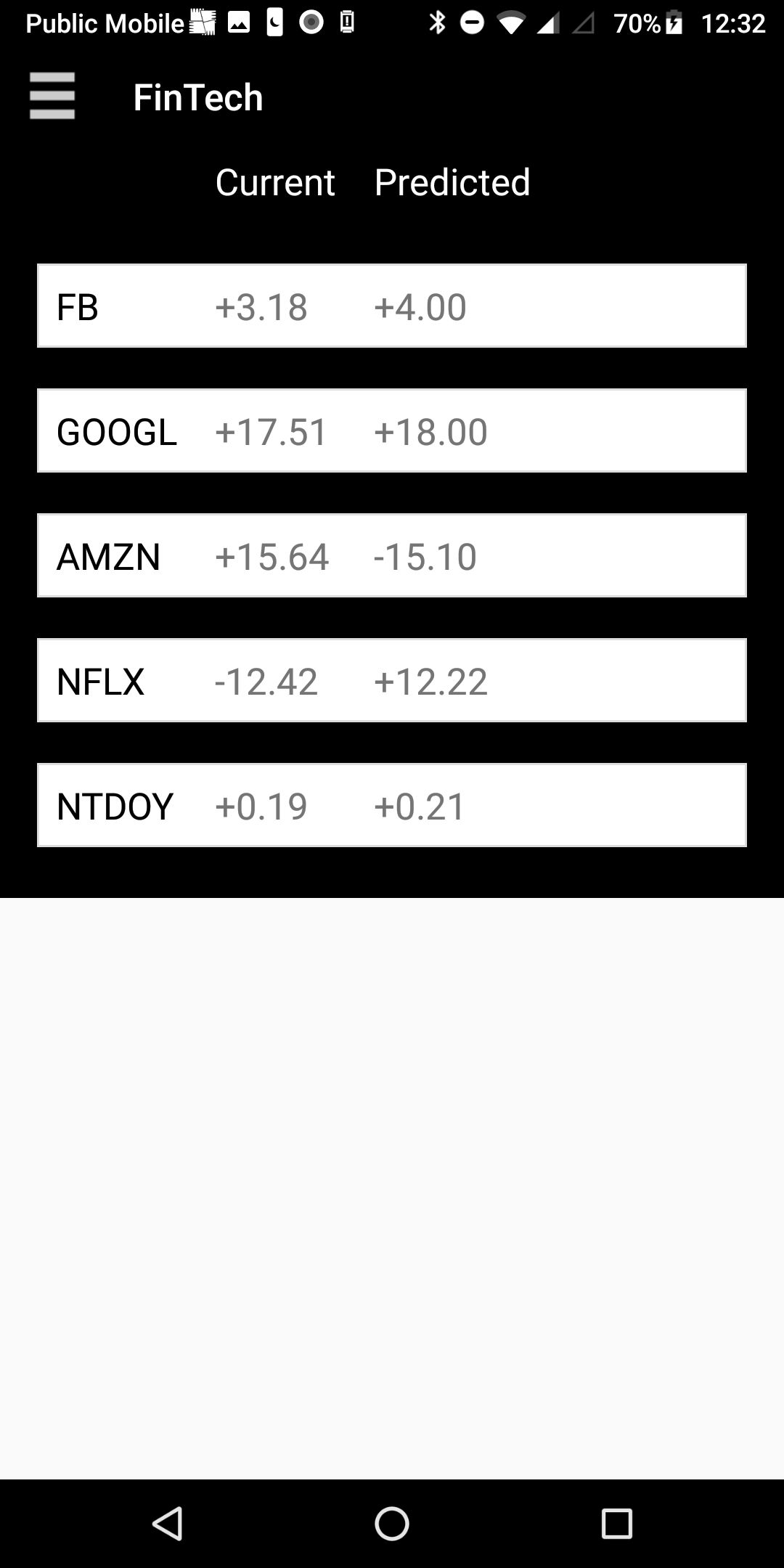
Fin scrapes news headlines and looks for keywords that convey a positive, or a negative reputation for FAANG. We then take this data and plug it into our genetic algorithm that attempts to use hourly stock predictions and their accuracy as a measures of fitness. Over multiple generation our algorithm should be able to predict stock movement with a relatively low percent error.
How we built it
We built Fin using Python for the scraper, Java for the computational back-end, JSON for our data format, and using Android studio for the front-end.
Challenges we ran into
The largest challenge that we ran into was how to store our data in the cloud, as well as how to communicate the changing data in real time with devices
What's next for Fin
We can continue to improve on Fin by improving how we read data and formate it, as well as migrating the entire product to the cloud.






Log in or sign up for Devpost to join the conversation.