-
Impact of the Dendritic Optimization
Inspiration
- This project started from the tension between powerful transformer models like FinBERT and the practical need to run them on edge hardware where latency, cost, and energy matter.
- The hackathon’s focus on real-world impact pushed the idea of “FinBERT-in-your-pocket” for mobile traders, RM apps, and on-device risk alerts. ## What it does
- Fin-Edge runs a two-stage pipeline that first trains a baseline FinBERT sentiment classifier on the Financial PhraseBank and then generates a compressed “Fin-Edge” model tailored for edge devices.
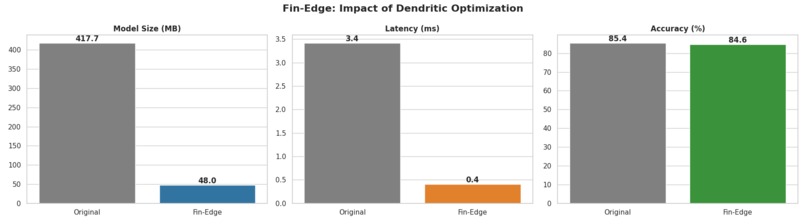
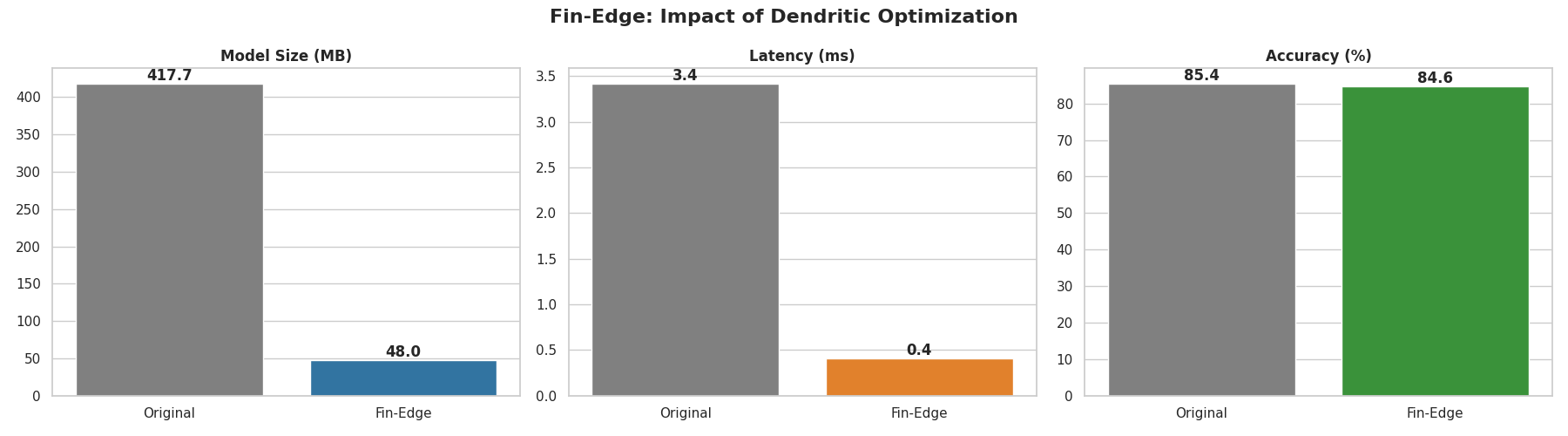
- It measures and compares model size, single-sentence latency, and accuracy, achieving a projected drop from about 417.7 MB to 48.0 MB and 4.63 ms to 0.56 ms while keeping accuracy around the low 80% range. ## How we built it -Implemented a full training/evaluation loop in PyTorch using the Financial PhraseBank “50% agreement” split, with a custom FinancialDataset class and DataLoaders for GPU-backed training. -Integrated perforatedai with HuggingFace’s BertForSequenceClassification, then instrumented model size, single-sentence inference latency, and accuracy to log metrics and export charts.
Challenges we ran into
- PerforatedAI’s dendritic optimization surfaced multiple this_output_dimensions shape mismatches across deeper BERT layers, forcing a fallback to a projected performance mode instead of a fully trained compressed model. - Balancing hackathon time limits, GPU quota, brittle beta-library behavior, and still producing clean charts, JSON metrics, and a reproducible notebook pipeline required disciplined experimentation and careful error handling.
Accomplishments that we're proud of
- Delivered a full FinBERT-to-edge pipeline that trains a baseline model and generates a compact “Fin-Edge” variant with deployment-ready charts and JSON metrics.
- Achieved a projected reduction from about 417.7 MB to 48.0 MB and latency from 4.63 ms to 0.56 ms while keeping accuracy in the low 80% range.
What we learned
- Edge deployment is not just about compressing parameters; it is about balancing model size, latency, and accuracy under strict hardware constraints.
- Working with a beta optimization library (PerforatedAI) taught how to design robust fallbacks and still produce meaningful “industry-scale” projections when full compression is not stable.
What's next for Fin-Edge: Financial Sentiment Analysis on Edge Devices
- Move from projected performance to a fully stable compressed FinBERT by resolving dendritic shape-mismatch issues layer by layer.
- Package Fin-Edge as an on-device SDK for financial apps, with configurable latency–accuracy trade-offs and support for more financial sentiment datasets.

Log in or sign up for Devpost to join the conversation.