-
-
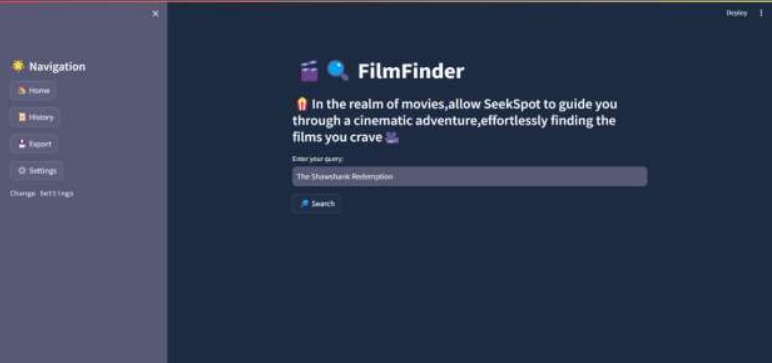
home page
-
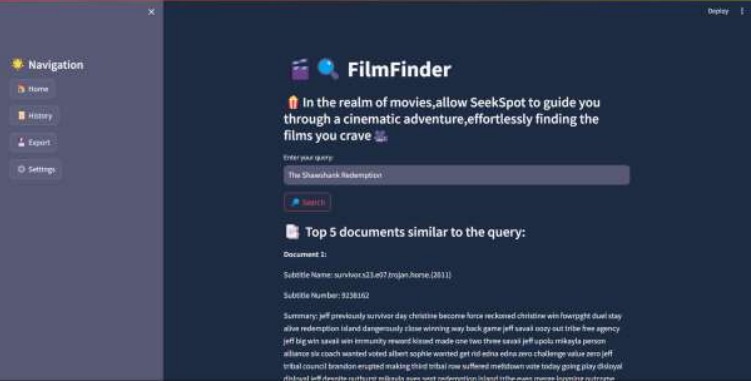
output
-
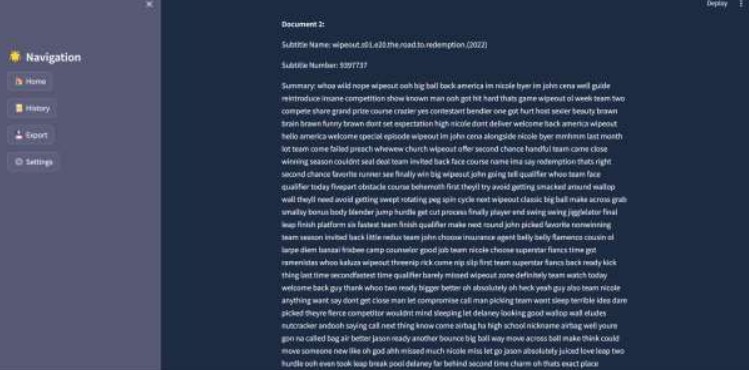
output

Project Overview: The "FilmFinder" project aimed to create an intuitive movie search engine, leveraging natural language processing techniques to recommend similar films based on user queries. Developed using Streamlit, the application provided users with a user-friendly interface to explore a vast database of movie subtitles.
Inspiration: The inspiration behind "FilmFinder" stemmed from a desire to simplify the process of discovering new movies by providing tailored recommendations. Drawing from my interest in both data science and cinema, I envisioned a tool that would empower users to explore the world of film with ease.
Development Process: The development process began with data acquisition, involving the compilation of a comprehensive database of movie subtitles. Leveraging pandas, the data was loaded and prepared for analysis. Next, machine learning models were trained using scikit-learn to transform the textual data into a format suitable for similarity calculation. The cosine similarity metric was employed to identify movies similar to the user's query, enabling personalized recommendations.
User Interface Design: The user interface was designed with simplicity and functionality in mind, featuring a clean layout with intuitive navigation elements. Streamlit facilitated the creation of interactive components such as text inputs for queries and buttons for navigation. A sidebar menu provided quick access to different sections of the application, including home, search history, data export, and settings.
Key Features:
Search Functionality: Users could enter queries to search for movies based on titles, genres, or keywords. Search History: A history feature allowed users to revisit their previous searches, enhancing usability and convenience. Data Export: Users could export search results and chat data for further analysis or record-keeping. Settings: A settings menu provided options for customizing the application's behavior and preferences. Challenges Faced: One of the main challenges encountered during development was optimizing the performance of the similarity calculation process, particularly with large datasets. Efficient memory management and vectorization techniques were employed to mitigate computational overhead and ensure responsiveness.
Future Improvements: Future iterations of the "FilmFinder" project could incorporate advanced recommendation algorithms, user feedback mechanisms, and multimedia content integration to enhance the user experience further. Additionally, improvements to the user interface and additional features such as collaborative filtering and content-based filtering could be explored to enrich the recommendation capabilities.
Conclusion: In conclusion, the development of "FilmFinder" was a fulfilling endeavor that combined my passion for data science and cinema. By leveraging natural language processing and machine learning techniques, I created a versatile tool that empowers users to discover new movies tailored to their preferences. Moving forward, I look forward to refining and expanding this project to make movie exploration more enjoyable and personalized for users worldwide.
Built With
- machine-learning
- pandas
- python
- streamlit

Log in or sign up for Devpost to join the conversation.