Inspiration
When taking a screenshot of a page or downloading something from the internet, it often more than not gets lost in a forever bin of recents, with out of place default names that are way too long for any of us to recall. Wouldn’t it be cool if there existed a way to recall any file from your folder of 1000+ images?
Our app solves this by using CLIP, an AI model, to quickly find images that match the users query in a flexible & fast way.
What it does
FileSeekr uses OpenAI’s CLIP model to embed files, and place them into a vector database which we use to quickly find similar searches to the users query using the same AI model.
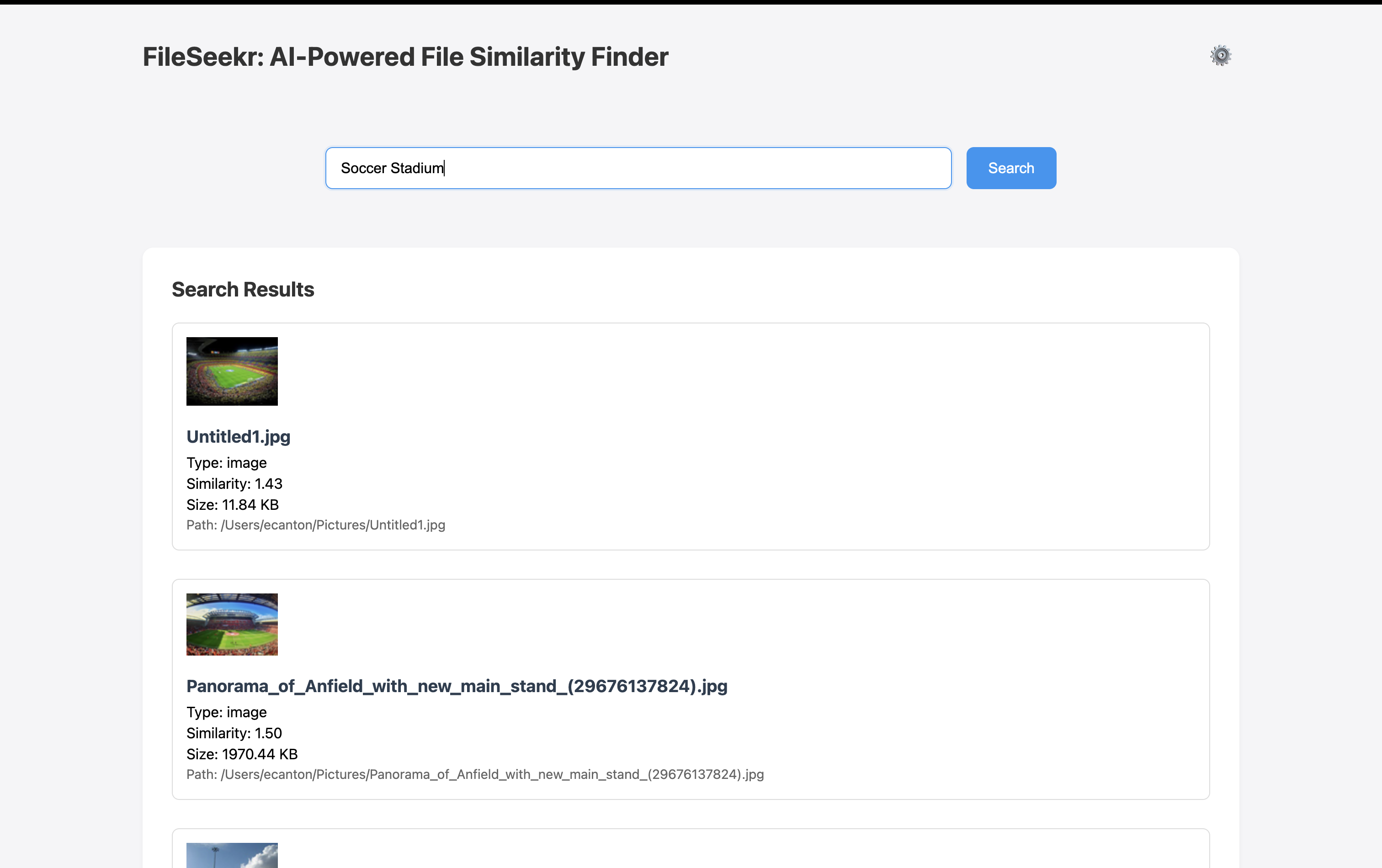
From a user perspective, they can specify a path for where the model looks into (what directory), the image format, and when those settings and toggles are done, they will be directed back to the search page where they can use natural language to query for a particular image within a large directory. The most similar images will display on the top.
How we built it
We developed FileSeekr using Python for backend processing. Flask was the framework of choice here, give its ease of development. We used the CLIP model and Chromadb for similarity searches, and Electron.js for the desktop app wrapper, and TypeScript for the front end logic
Challenges we ran into
We ran into challenges on integrated the front-end and back-end, We also struggled with finetuning the model to get more similar searches.
Accomplishments that we're proud of
Were proud to use embedding models for the first and achieve results that are satisfactory for the hackathon.
What we learned
How embeddings worked. Electron TypeScript Threading
What's next for FileSeeker
We Hope to implement functionality to connect cloud services and add them to the database. We also hope to create a better way to find similar files.

Log in or sign up for Devpost to join the conversation.