-

FileMind logo
-
-
-
-
-

Inspiration
FileMind started from a simple problem: we store hundreds of documents, but finding and understanding them later is painful. File names are inconsistent, metadata is unreliable, and searching inside files is limited. We wanted to build a backend that treats files as structured data, not just blobs in storage.
What it does
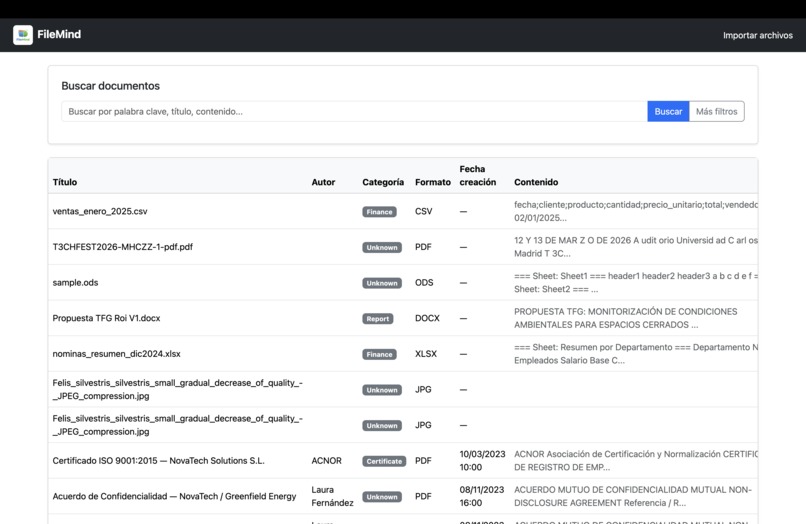
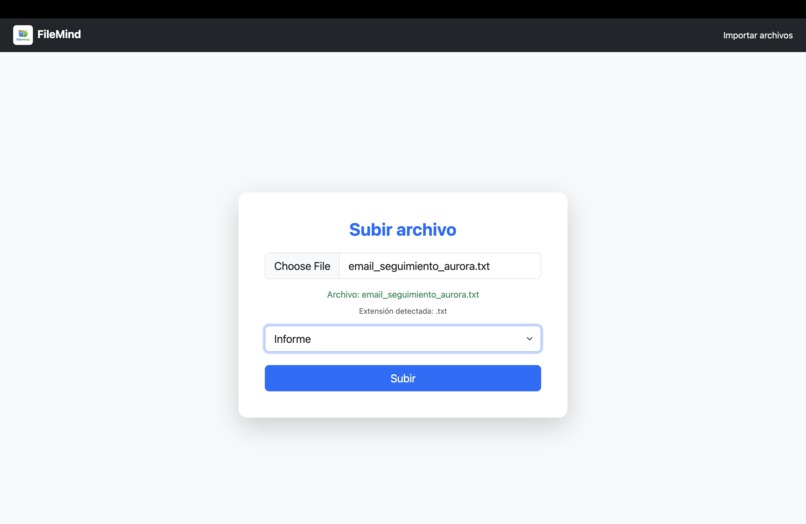
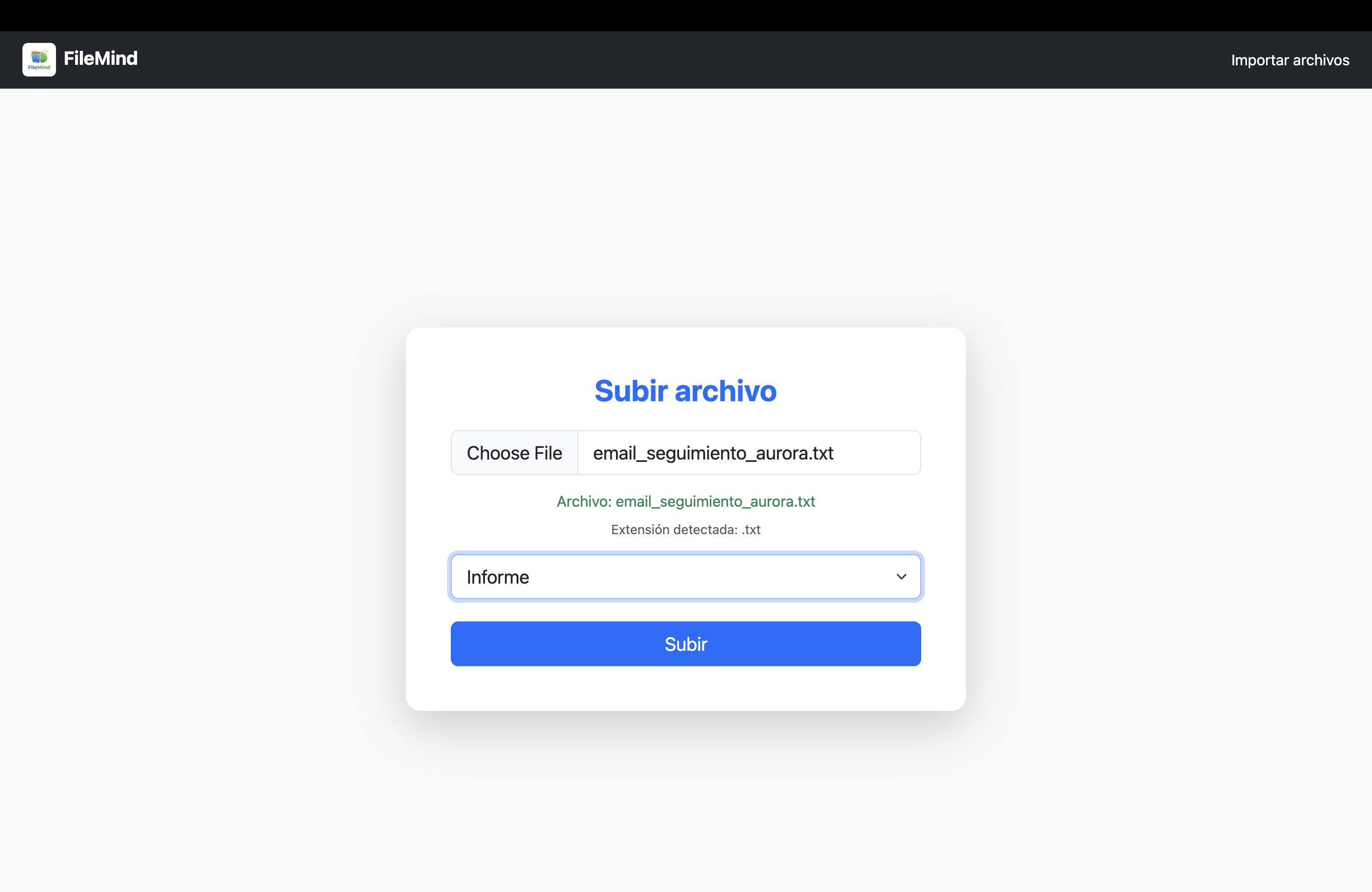
FileMind is a file management web application that:
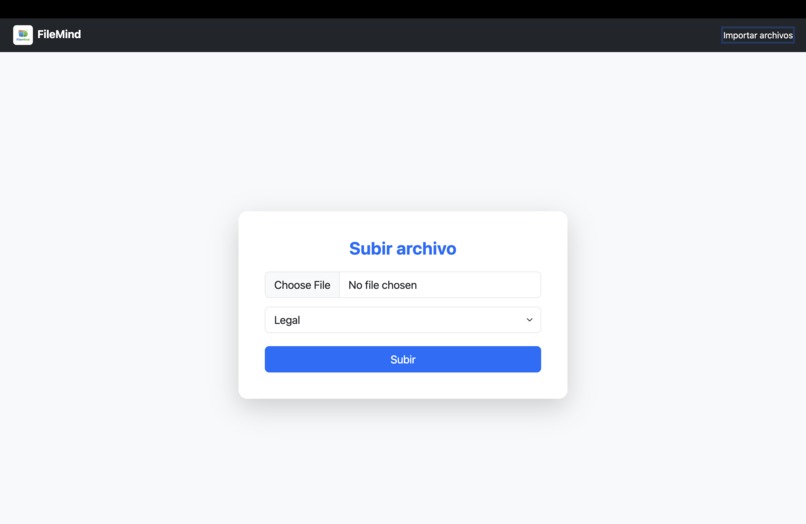
- Accepts and parses multiple file types (PDF, TXT, XLSX, CSV, DOCX, ODT/ODS, images).
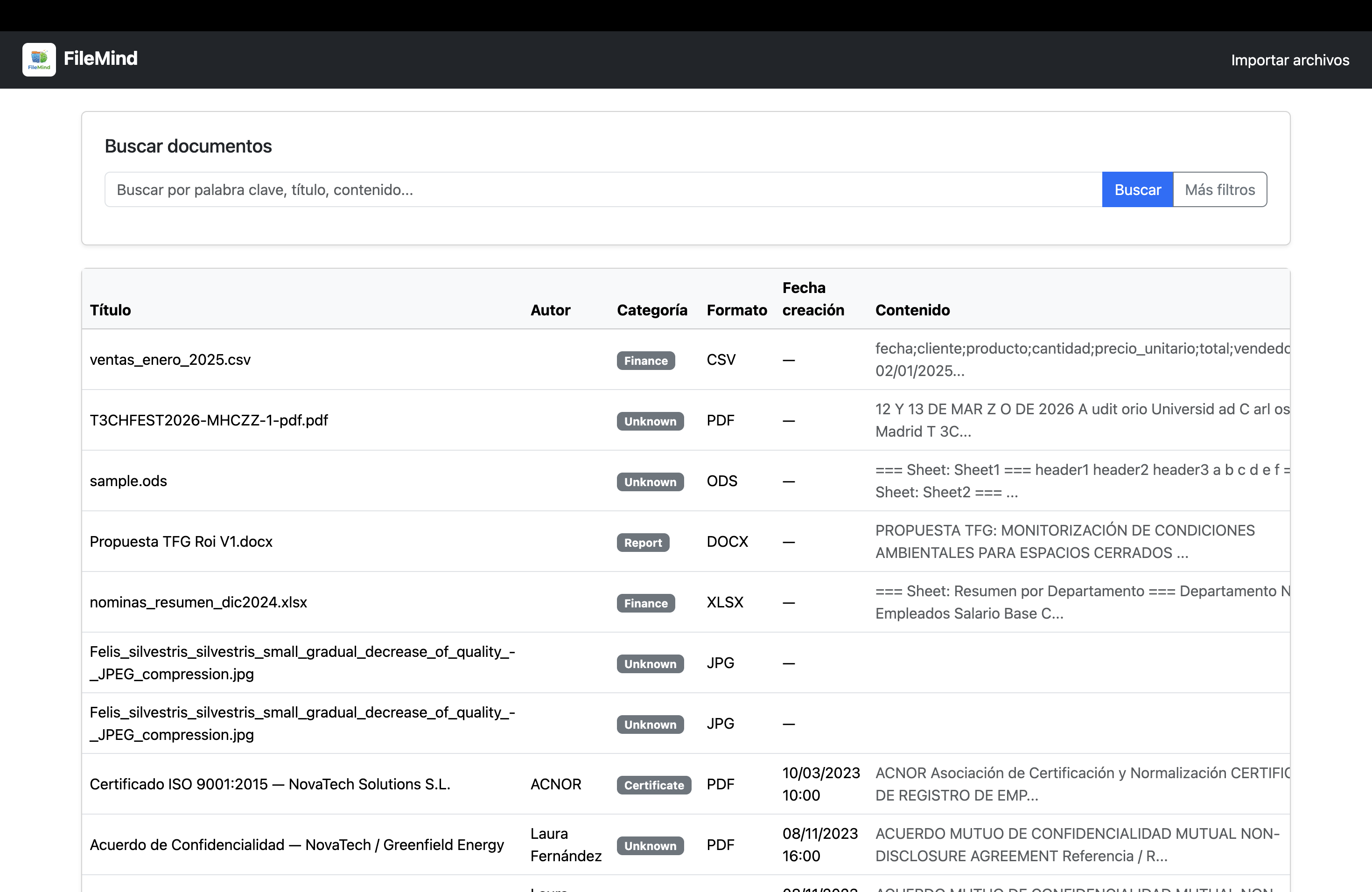
- Extracts text content and useful metadata.
- Stores everything in PostgreSQL, including structured JSON metadata.
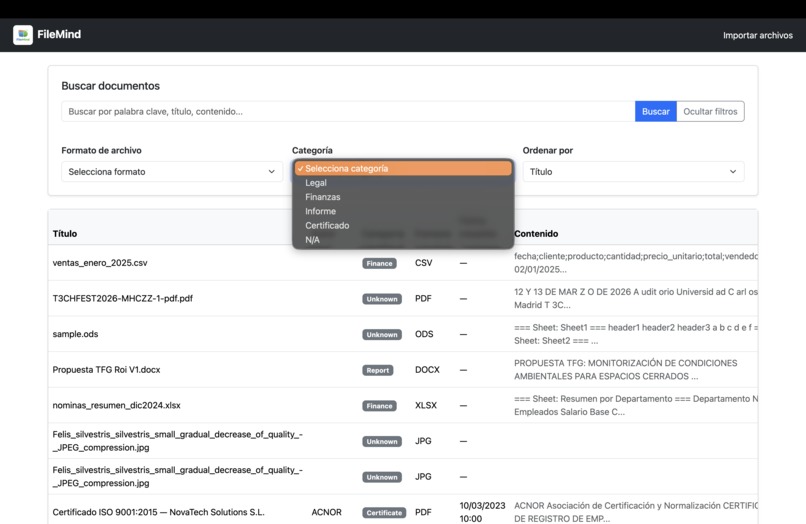
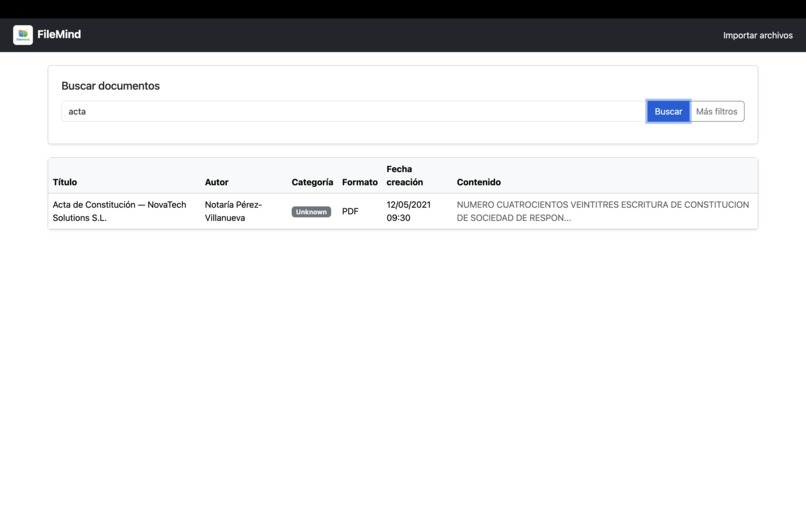
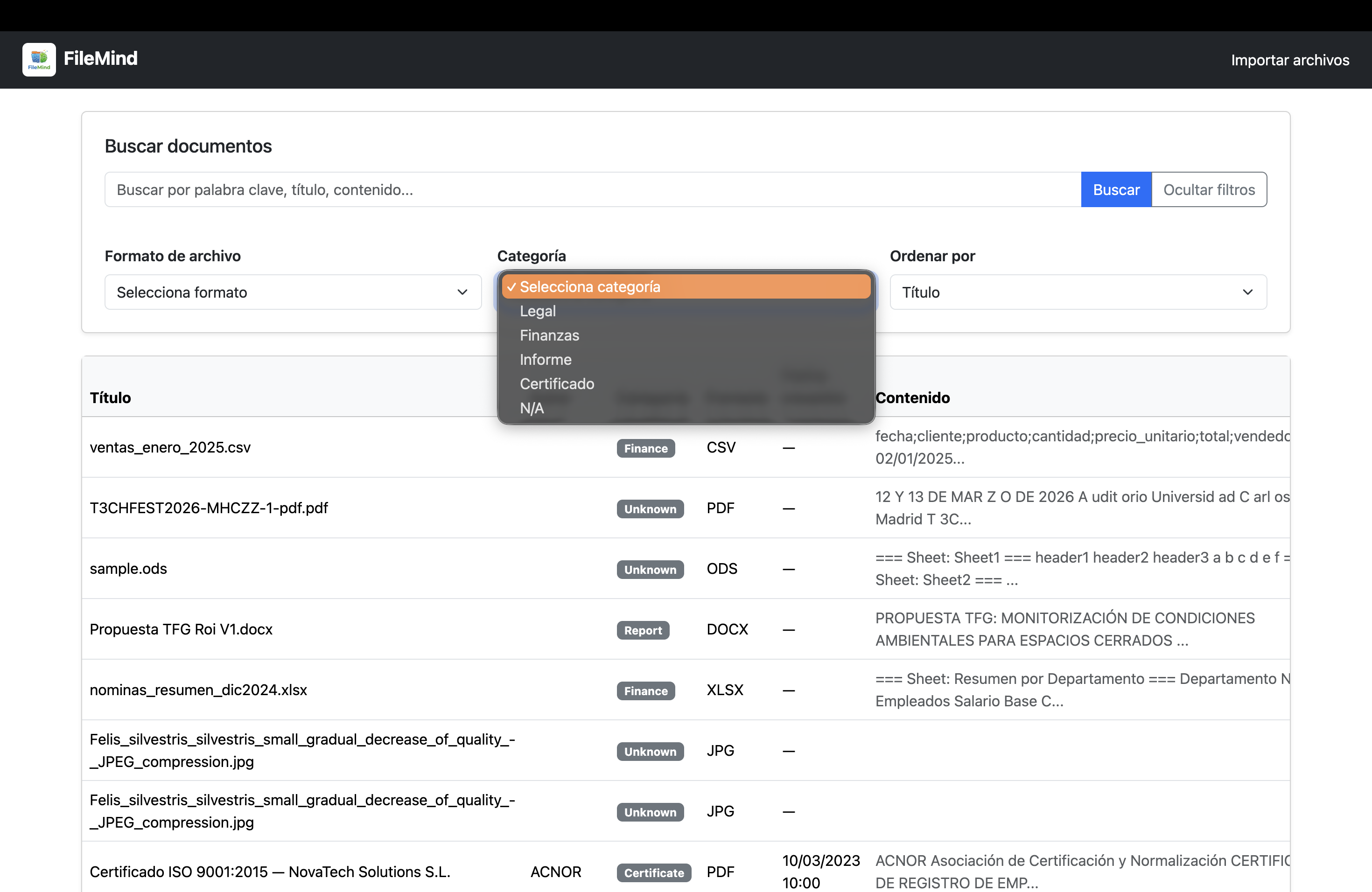
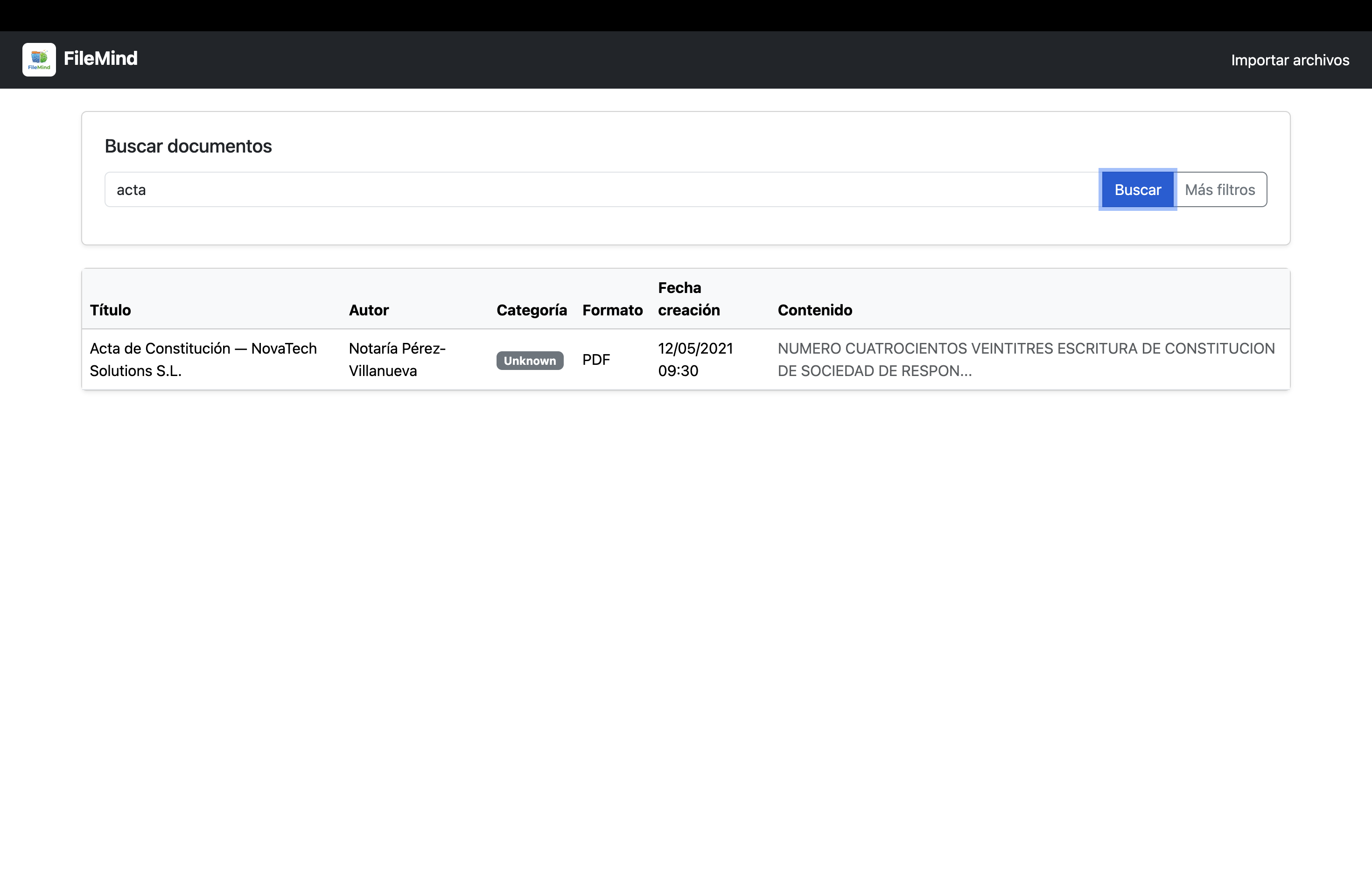
- Supports filtering and keyword-based search.
- Implements OCR to extract information from picture-based PDF files.
- Generates summaries of stored files through an AI endpoint.
How we built it
The backend is built with FastAPI and SQLAlchemy, while the frontend is built with React. Each file format has a dedicated parsing method that extracts its content into a normalized format. Metadata is stored as JSONB to enable flexible filtering. An additional endpoint connects to the OpenAI API to generate summaries based on stored file data. Furthermore, PDF files that aren't text-based are detected automatically and OCR is used to extract their content.
Challenges we ran into
- (Changing our project for this Hackathon midway through it😅).
- Designing a consistent structure across many file formats.
- Managing large file content when generating summaries.
- Keeping the API clean while supporting flexible filtering.
- Making Pydantic models and SQLAlchemy work smoothly together.
- Connecting to a remote database on a "hostile" environment for external connections as is the University network.
- Combining the substantially different approaches to web development of both team members.
- Orchestrating the deployment process and the difficulties associated with shipping the app through two deployments (one for the frontend and another for the backend).
Accomplishments we're proud of
- A single ingestion endpoint capable of handling multiple formats.
- Metadata-aware search and filtering.
- A clean integration between stored file data and AI summarization.
- An effective integration of such a powerful technology for data extraction as OCR.
- The successful deployment of the app with an actual cloud platform (Vercel) in such a little time.
What we learned
We learned how important schema design is when dealing with heterogeneous data. We also saw how combining structured storage with intelligent processing opens up new ways to interact with documents.
What's next for FileMind
Next steps include semantic search with embeddings, better indexing for large documents, implementing user authentication, and extending the scale of the deployed app.
Built With
- fastapi
- postgresql
- python
- react

Log in or sign up for Devpost to join the conversation.