-
-

poster
-
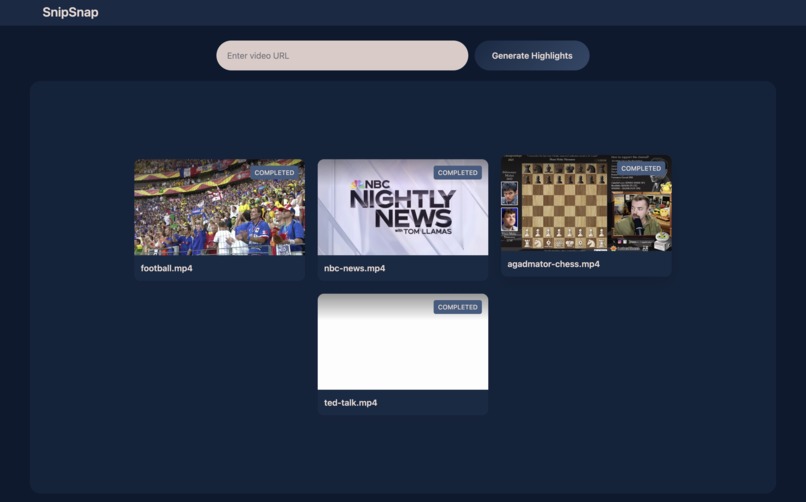
site-preview-main-page
-
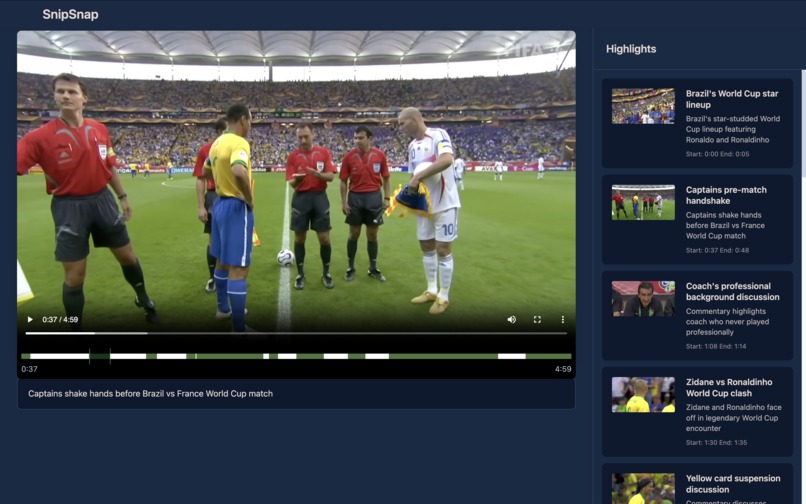
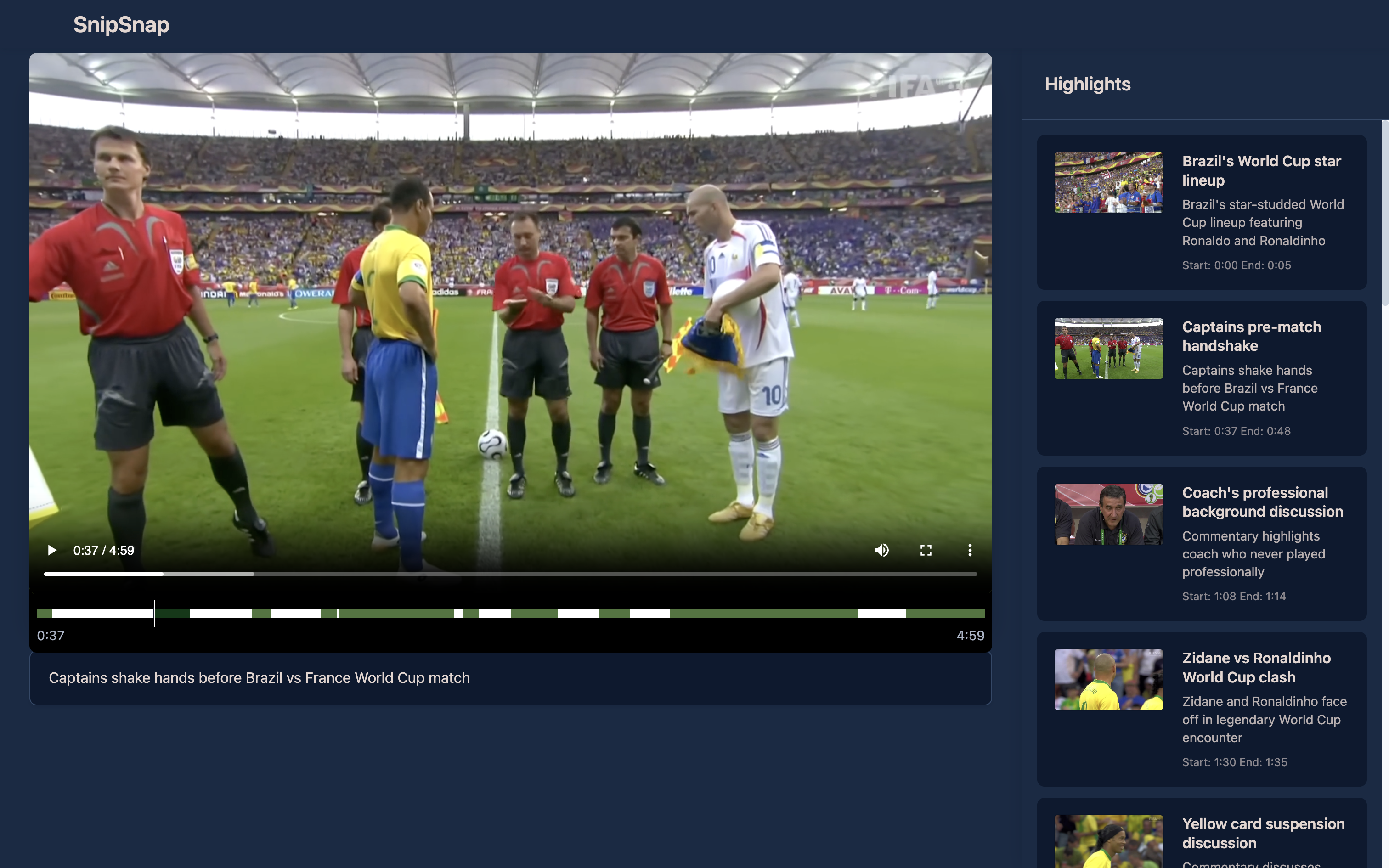
site-preview-highlight-page
-
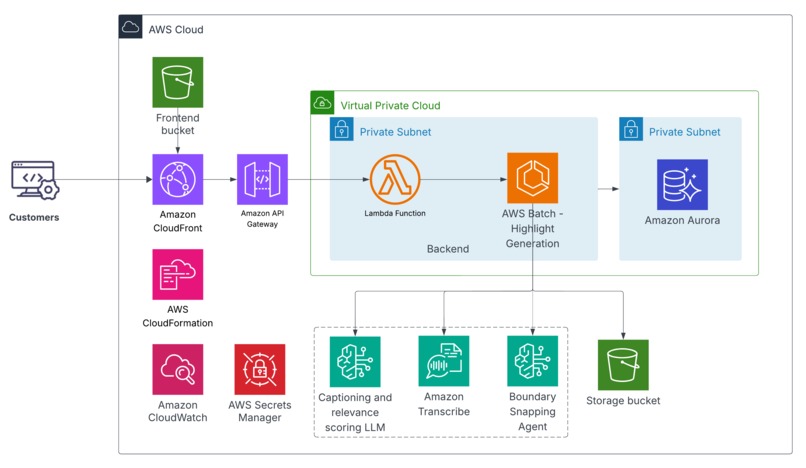
aws-architecture

Inspiration
We wanted a fully automated way to turn long, unstructured videos into concise, human‑quality highlights without manual editing. This is especially useful during live sports streams, where human can just review the generated highlights and adjust it to their needs, instead of being glued to the stream but this system works for just about any given video. Two principles guided us: (1) keep the core pipeline deterministic and streaming‑friendly, and (2) Add enough LLM intelligence to make highlights feel intentional and human.
What it does
- Takes in a video/stream URL from the user
- Samples video frames, chunks audio, and transcribes speech
- Creates a relevancy score of these chunked 5‑second candidate clips using visual motion + LLM caption/score via AWS Bedrock.
- Groups related clips into longer highlight spans with titles.
- Runs an agentic refinement pass: the LLM plans one bounded action (keep / topic‑snap / scene‑snap / micro‑adjust), then clamps edge of the highlight based on values from topic boundaries detection and scene detection
- Writes final highlights (start/end, title, caption, thumbnail, reason) back to metadata.
How we built it
- Media: PyAV for demuxing, PIL/OpenCV for frames.
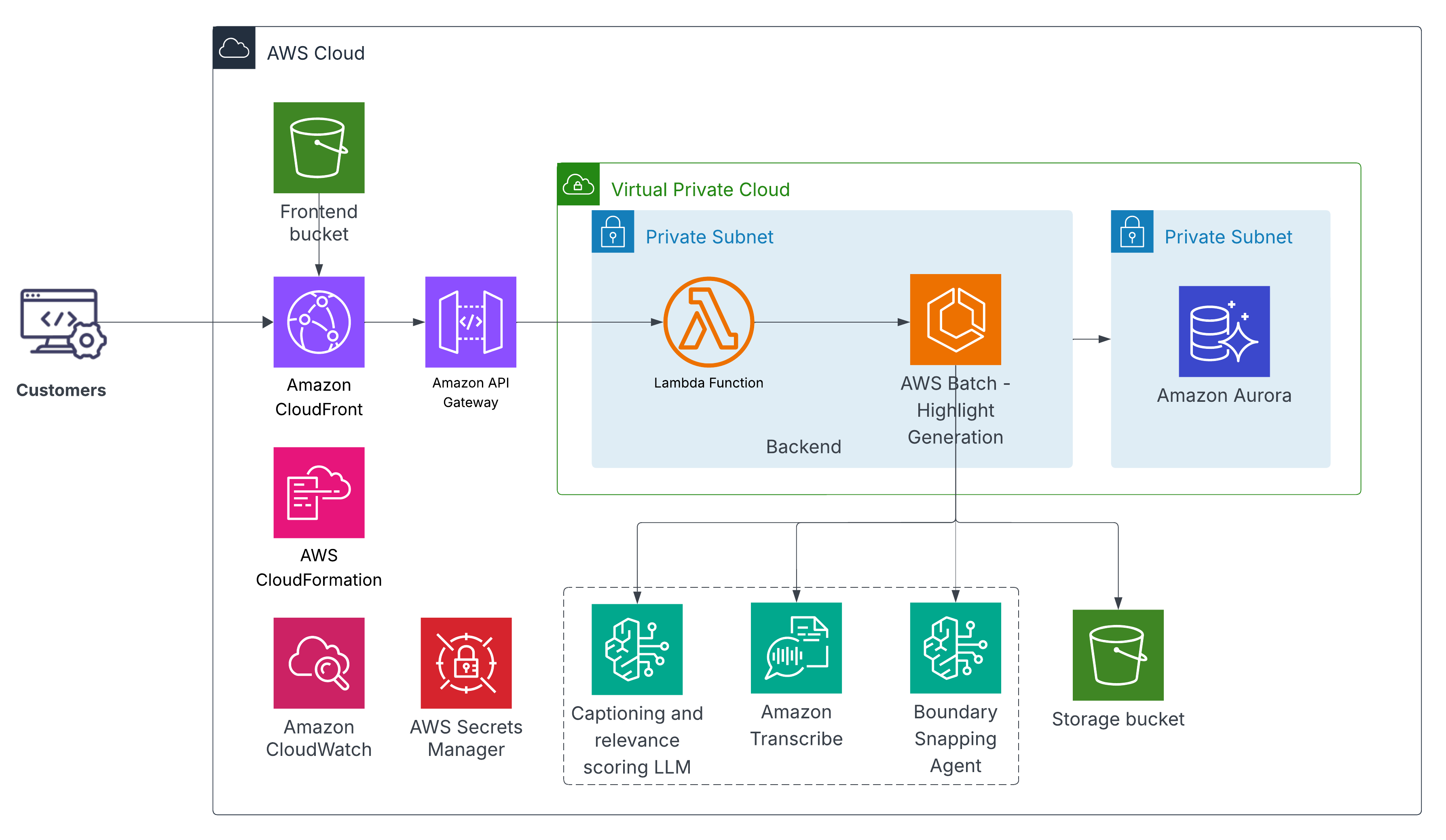
- Storage/Compute: Lambda accepts video URL from user and submits to AWS Batch, Batch then streams the video converts into frames/WAVs and performs the necessary processing, S3 for storing input video, Aurora MySQL for highlight and other metadata.
- Speech: Amazon Transcribe Streaming
- LLMs: Amazon Bedrock (Claude) for per‑clip caption/score, grouping adjacent highlights and boundary snapping agent.
- Boundaries: TextTiling over transcript words (topic changes) + frame‑based scene detection (HSV histogram distance).
- Orchestration: Serverless for deployment.
Challenges we ran into
- Boundary realism: Balancing transcript cues (don’t cut mid‑word) with visual cuts (don’t cut mid‑action).
- LLM reliability: Throttling and occasional bad JSON; we added retries, strict schemas, and deterministic fallbacks.
- Guardrails: Preventing tiny or very long results, avoiding start/end crossing, and capping how far edges can move from the grouped span.
Accomplishments that we're proud of
- An end‑to‑end pipeline that stays useful even when the “agent” is off; with it on, highlights feel markedly cleaner.
- Works with live streaming content, doesn't require the full video to be available at once.
What we learned
- Transcript‑first works: Aligning to word/topic boundaries avoids most “why did it cut mid‑sentence?” moments.
- Most importantly, there are usecases where LLM is perfect even with it's flaws and this is one of them, because even if produced highlights are off by few seconds, the output is still useful for a human reviewers and it
still saves time, since he/she can just adjust the timeline and clip it without having to watch the whole video.
What's next for Figureout
- Convenience: Also support video uploads, right now, we only accept video URLs.
- Quality: Introduce word level detection using WhisperX for better topic boundary detection.
- Human in the Loop: Add HILT to refine highlight boundaries from the site itself.
- Metadata: Collect metadata on which videos humans are accepting highlights as is, and where they are altering/refining the given highlights. This will tell us if the system is not performing well on certain video genres.
- Cost: Batched/pooled invocations when possible and results are not immediately required.
Built With
- amazon-cloudfront-cdn
- aws-batch
- aws-bedrock
- aws-transcribe
- claude
- lambda
- python
- s3
- serverless-aurora

Log in or sign up for Devpost to join the conversation.