-
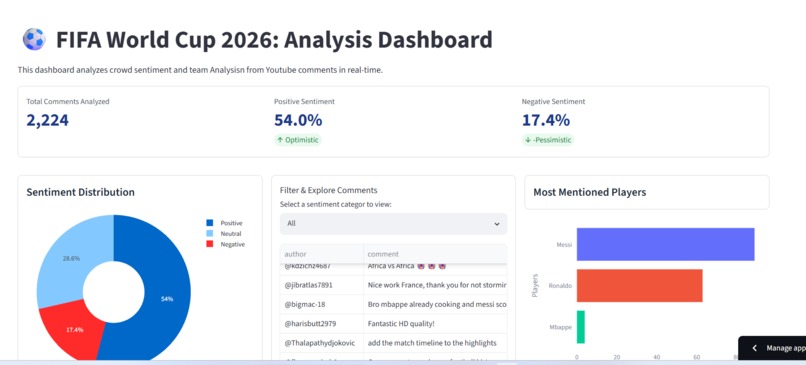
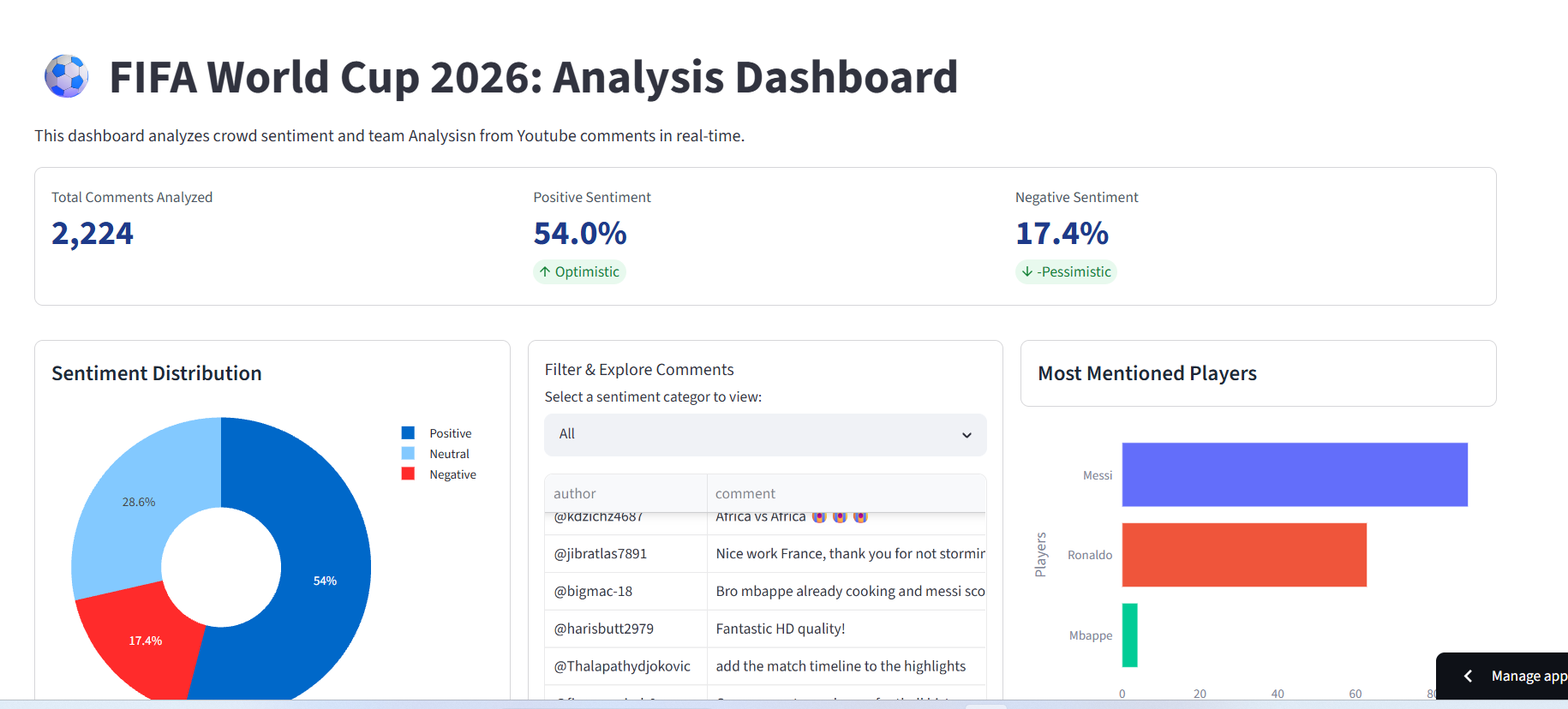
Dashboard
Inspiration
The year 2026 is an unprecedented milestone in soccer history: the first-ever 48-team FIFA World Cup, uniquely co-hosted across three massive nations—the USA, Canada, and Mexico. With billions of fans flooding digital platforms to share their hype, criticisms, and match predictions, traditional sports analytics simply couldn't keep up with the chaotic velocity of internet culture. We wanted to build something that acted as a real-time digital stadium pulse, capturing exactly what the global fanbase is feeling, celebrating, or complaining about at any given moment.
What it does
FIFA-Fanfest-2026 is an automated, end-to-end data pipelines and interactive intelligence dashboard. It extracts thousands of sprawling YouTube comments surrounding World Cup content, sanitizes the noise, strips out multi-language clutter, and runs real-time sentiment profiling using an optimized VADER engine. Beyond generic sentiment metrics, it features an automated Entity Recognition module that scans discussions to instantly map out which players (like Messi, Ronaldo, or breakout stars) and which teams are driving the conversation, grouping their public perception into clear, interactive visual profiles.
How we built it
We built this project using a lightweight but highly scalable Python stack:
- Data Extraction:* Initially navigating Reddit's new API portal before pivoting and implementing the
google-api-python-clientto scrape raw text, metrics, and metadata directly from YouTube interaction threads. - Data Cleansing & NLP:* Cleaned data using
pandas, stripped out short text artifacts/emoji-only noise with regular expressions, isolated English text vialangdetect, and utilizedNLTKto eliminate structural English stopwords. - Sentiment Modeling:* Implemented a rule-based VADER Sentiment Analyzer to process text rapidly while natively evaluating internet slang, capitalization intensity, and emoji weights.
- Frontend Dashboard:* Wrapped the data engine in a containerized Streamlit architecture, designing customized card layouts with HTML/CSS injection, and generated highly interactive, clickable tracking visualizations via Plotly Express.
Challenges we ran into
We hit several major roadblocks along the way:
- API Redirection & Access Barriers: Navigating the newly updated Reddit Developer Portal initially slowed our momentum with onboarding documentation barriers and strict app-type permissions.
- The "Data Overwrite" Chain: We fought a subtle bug where sequential data filtering commands kept overwriting our main dataframes, accidentally clearing out previous deduplication rules until we mastered explicit, in-memory Pandas copying (
.copy()). - Context Destruction: We originally tokenized and removed stopwords before running our sentiment analyzer. We quickly realized this stripped vital context (like the word "not") and ruined model accuracy, forcing us to re-engineer the pipeline to analyze full, raw sentences first.
- UI Messiness: Standard Streamlit rendering can look flat and cluttered. We struggled with raw HTML escaping into the webpage before properly configuring structural layout blocks with
st.container(border=True)andunsafe_allow_html=True.
Accomplishments that we're proud of
- Successfully engineering an advanced Dynamic Entity Extraction mechanism that uses regex to naturally catch variations in spelling (e.g., matching "Leo", "GOAT", and "Messi" back to the same person).
- Creating a visually gorgeous, clean, modular dashboard utilizing a professional "card/box" layout paradigm that feels like an enterprise analytics portal.
- Developing a script optimized for performance, enabling a standard consumer laptop to ingest text, run NLP routines, classify sentiment, and render charts in seconds.
What we learned
We gained deep technical insights into building real-world data pipelines. We learned the hard way that data preparation and pipeline sequencing (knowing exactly when to drop stopwords vs. when to calculate sentiment scores) matter just as much as the machine learning model itself. We also learned how to read open-source library schemas closely to bypass runtime typos (like mixing up .columns properties) and how to design UI software purely around scannability and user experience.
What's next for FIFA-Fanfest-2026
Multi-Platform Scraping: Expanding our pipeline scripts to ingest data concurrently from multi-platform ecosystem. Live Streaming Pipelines: Transitioning from batch CSV processing to a live, rolling data framework utilizing Apache Kafka or Streamlit's periodic refresh loops. Native Multi-lingual Support: Moving past English-only filters by implementing multi-language transformer pipelines (like XLM-RoBERTa) to read Spanish and French fan comments natively, capturing the true global spirit of the tournament.

Log in or sign up for Devpost to join the conversation.