-
-
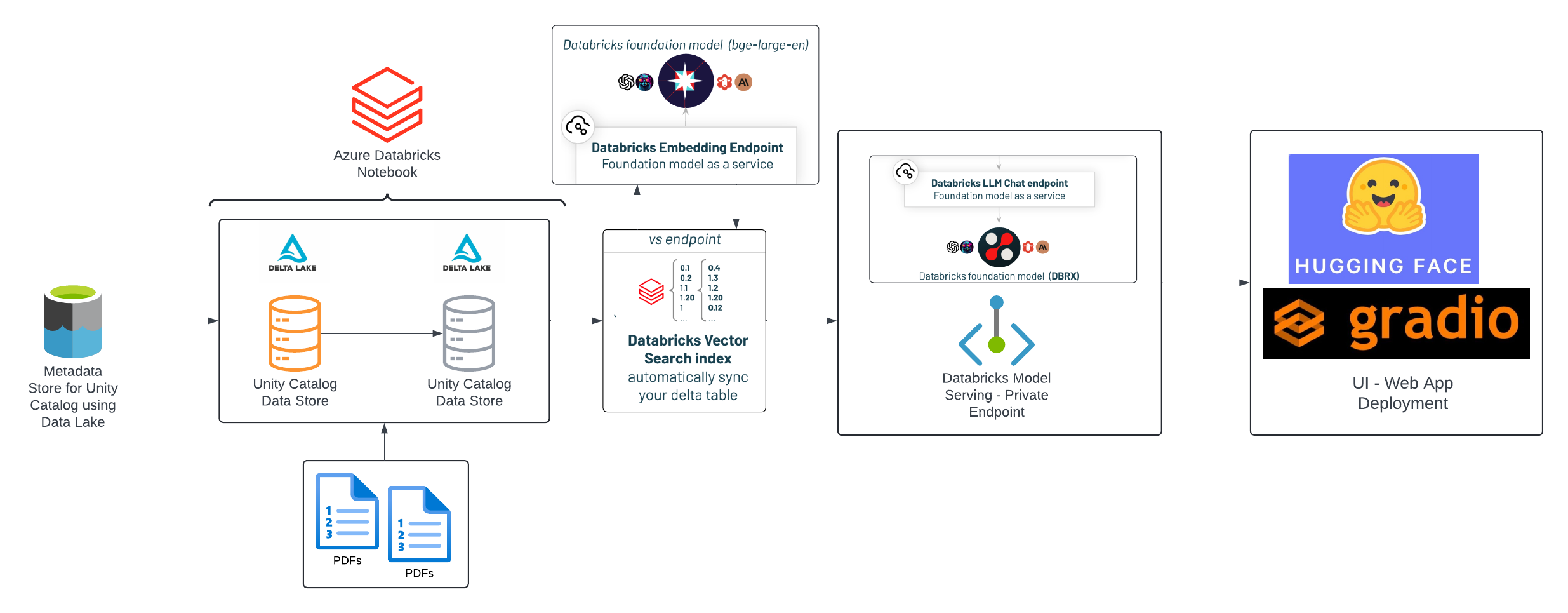
Architecture Overview
🎉 Inspiration
We were struck by the lightning bolt ⚡ of inspiration when we discovered the incredible potential of Retrieval-Augmented Generation (RAG) and the mind-blowing scalability of Databricks. We thought, why not combine these two superpowers to create a RAG-based LLM model that can swoop in like a superhero 🦸♂️ and save the day for Husky's field service engineers?
Company Website - Husky Webpage
About the Company - Husky Technologies specializes in Injection Molding systems and excels in providing top products and services for industries like consumer goods, medical, beverages, and automotive. They focus on delivering high-performance, efficient solutions globally, with extensive support including installation, training, and maintenance.
Problem Statement - To enhance productivity for Husky Technologies' field service agents, implementing a Large Language Model (LLM) or a context-aware Q&A bot could be transformative. This technology would allow agents to quickly navigate complex documentation necessary for diagnosing equipment issues, significantly speeding up the process. The main challenge is integrating Husky's large knowledge database and internal knowledge into the LLM to ensure it can effectively retrieve and interpret specific information.
🤖 What it does
Our RAG-based LLM model is like a genius librarian 📚 that lives inside Databricks. It has memorized Husky's entire collection of technical documents, User manuals, Service manuals and can provide spot-on answers to any question thrown its way. It's like having a pocket-sized expert 🧠 that engineers can consult anytime, anywhere!
🧅 How we built it
- Resources were created on Azure cloud including Resource groups, Databricks workspace, Unity Access Connector, Data lake storage (Metastore storage), Azure Key Vault Access (Secret Storage), cluster configurations were setup initially
- Connections and access management between Azure storage container and databricks workspace were established
- Ingested the Pdfs as into Unity Catalog volume store as raw data
- Split the pdfs in small chunks of text
- Computed the embeddings using a Databricks Foundation model - (bge-large-en) as part of our Delta Live Tables
- Created a Vector Search index based on our Delta live Table
- Trained the model with input and output examples
- Registered the fine tuned LLM model
- Endpoint was created and Served using ML-flow endpoint creation
- Established a space on hugging face for Chatbot User Interface with Gradio
🍽️ Dataset Used:
Documents used for RAG memory:
Hot Runner Product Handbook [238pgs]
Ultrasync Service Manual [78pgs]
Ultrashot Service Manual [186pgs]
Training Course Doc [20pgs]
😅 Challenges we ran into
Ensuring that the model's responses made sense and stayed on topic was like herding cats 🐱. Husky's documents are complex, and getting the retrieval process and model architecture just right took more trial and error than a mad scientist's lab 🧪. But we persevered, fueled by coffee ☕ and determination! And also obviously limited Budget 💸
🚀 What's next for our RAG-based LLM on Databricks
The sky's the limit! 🌟
- ✅ We plan to keep expanding the knowledge base, like a sponge soaking up water 🧽.
- ✅ Incorporating user feedback from industry experts and field service engineers/SMEs.
- ✅ Integration with existing enterprise systems and support for multiple languages?🌍!
- ✅ As a future scope, we plan to web scrape wikipedia pages, research papers, ebooks
The future is bright, and we can't wait to see where this journey takes us! 🎈
🧠 What we learned
We learned that combining retrieval and generation techniques is like mixing peanut butter and jelly 🥪 - they're just meant to be together! We also discovered the importance of fine-tuning the retrieval process and optimizing the model architecture, like a chef perfecting a secret recipe 👨🍳. Databricks was our trusty sous-chef 👨🍳, handling the heavy lifting of data processing and model training.
🎉 Accomplishments that we're proud of
We did it! We successfully combined the retrieval and generative components into a unified RAG model that provides accurate, context-specific answers. It's like we created a mind-reading machine 🔮 that can tap into Husky's collective knowledge and deliver coherent responses. We couldn't be prouder of our brainchild! 👶
🛠️ Tools Used:
- Programming Language - SQL, PySpark, Python
- Azure Cloud, Databricks
- Azure Data lake Gen 2 for metastore
- Delta Live Tables for documents storage

Log in or sign up for Devpost to join the conversation.