-
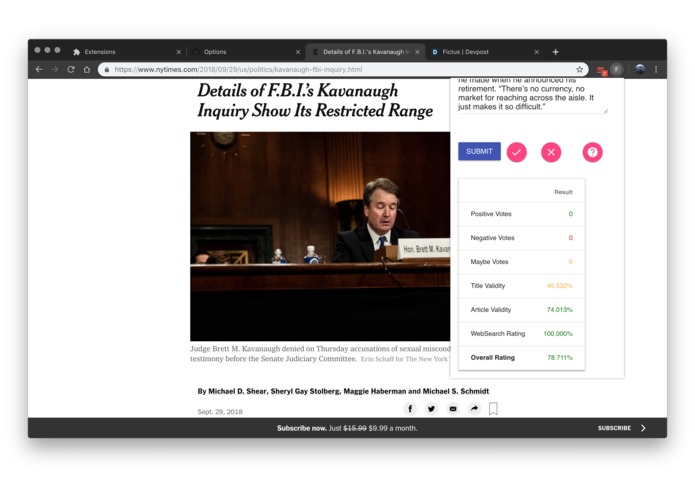
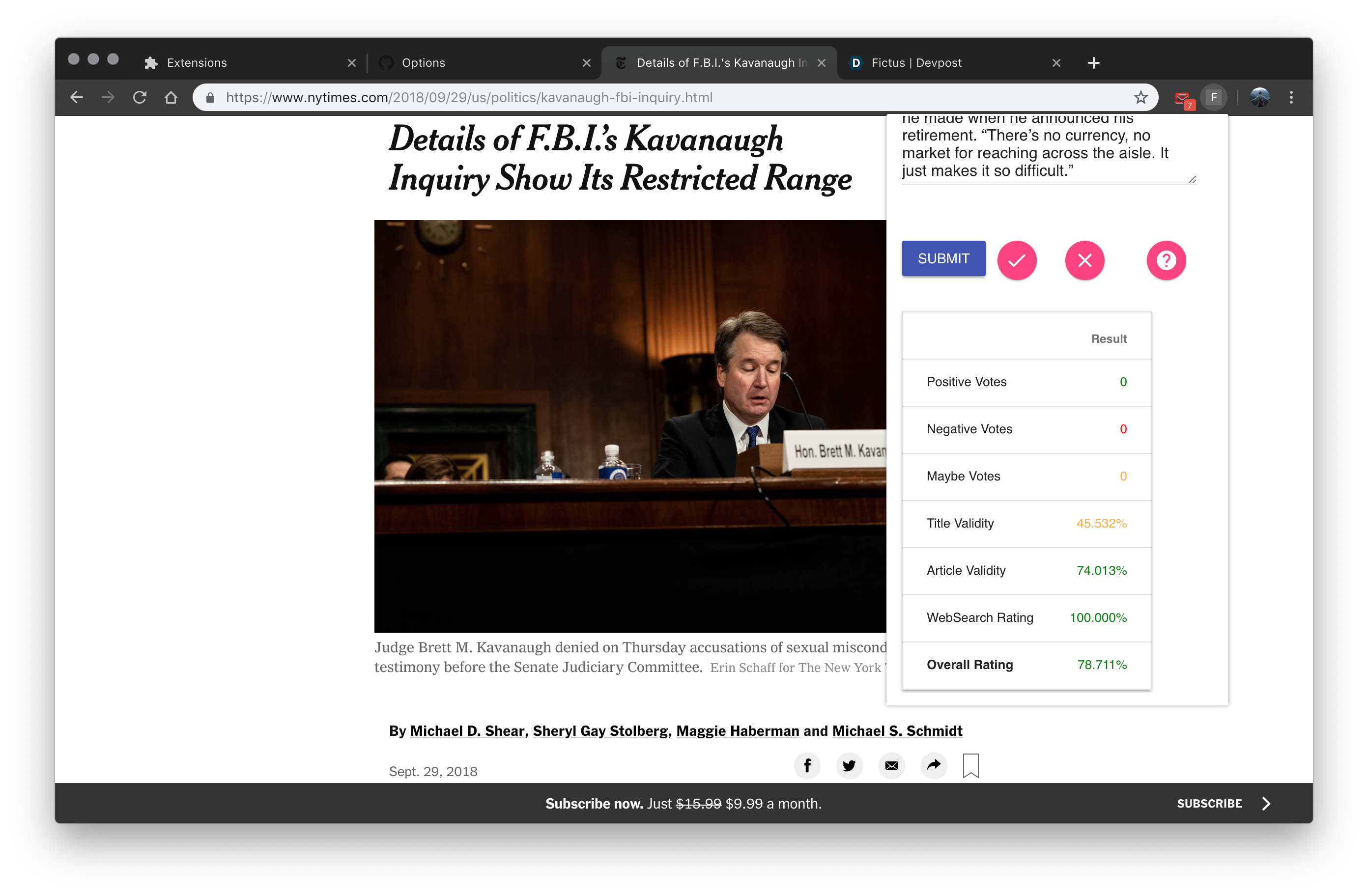
Is this article real or fake?
-
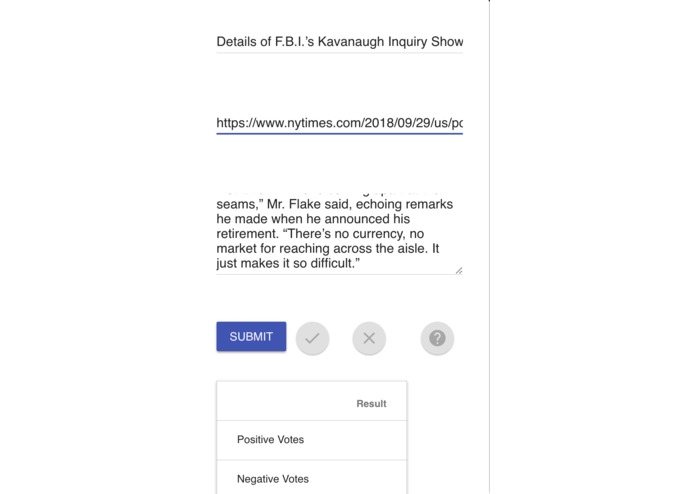
Let me consult Fictus...
-
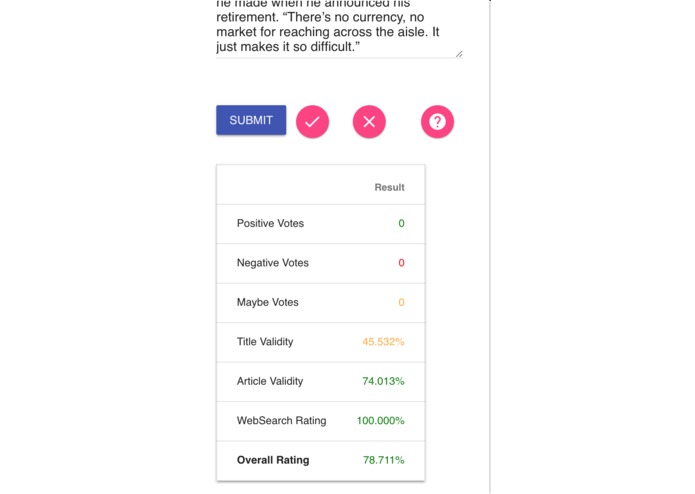
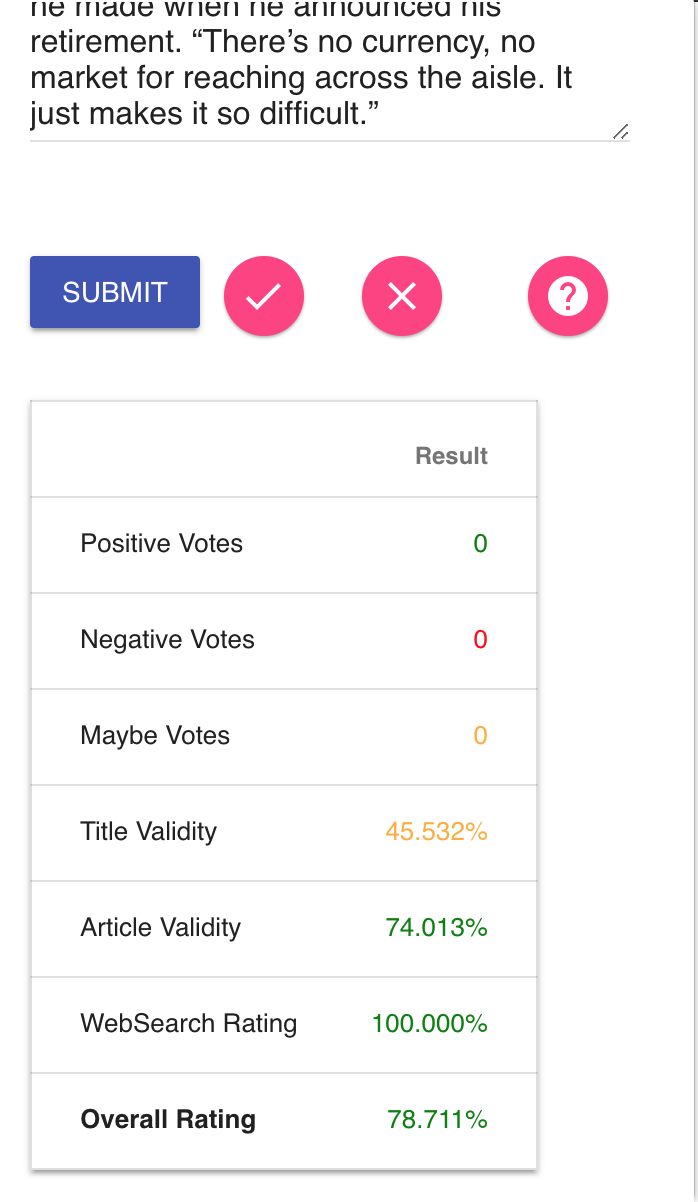
Looks like we are very confident that it is real
Fictus
Inspiration
As you might already know, humans do not know everything. There is currently no way for us to know everything that is going on the world at the present moment. Therefore, we rely on the media to inform us of events, happenings, results, and other facts. The media, made more accessible now than ever by technology, is a wonderful resource for this, but how do we know that we can trust the media? Is there a way to objectively determine the credibility of a source or article?
What it does
Upon taking in the information about the article that the user is reading, this program uses a three-pronged approach to determine whether an article is credible.
Analyzing the article’s similarities to fake and real articles through machine learning. How do the language patterns and diction in this article compare to that of articles that are known to be fake as well as ones known to be real?
Analyzing how relevant the information in this article is to other information on the internet. Does the information in this article compare to information in other similar articles? Can the facts in this article be corroborated by other sources?
Crowd-sourcing. We let the users decide how credible they think an article is and they can vote. What did others think about the credibility of an article?
How we built it
The information is analyzed using a database of news articles that were determined to either be "fake" or "real". Stochastic Gradient Descent Classification with Grid Search Cross Validation optimization was used to develop the prediction model.
The information is analyzed against other similar articles on the internet; the assumption was that if an article was unique and not being reported by other news sources, it was most likely fake. We created a web similarity algorithm in order to survey other articles on the internet and develop metrics between the two.
The information is analyzed through a crowd-sourcing element by asking the user to vote on the article’s credibility in the browser extension, and the result of that user’s vote is stored with other users’ votes.
All three of these approaches are weighted against one another to determine an overall credibility rating for the article at hand that is available to the user in the browser extension.
Challenges we ran into
While the validation of news is ultimately an objective process where facts are checked against reality, often these facts are not readily available to us, causing us to make a subjective decision on whether we can rely on the information that we are receiving. Replacing this subjective human process through technology and navigating around the ethics of analyzing the accuracy of journalism was one of our greatest challenges. The goal of a program such as this is to eliminate human judgement through technology, but how is this practically implemented through software?
Additionally, finding accurate datasets is difficult for two reasons. First, news is ever changing. Some news that was ~"fake" 2-3 years ago may be very similar to what news looks like now. This means we need a very large and/or recent data set for accurate modeling. Second, some unauthentic news is more "real" sounding that some real news (take The Onion for instance). The only solution we thought of for this is to keep a whitelisted database of non-credible sources.
Accomplishments that we're proud of
We are most proud of the nearly-seamless integration of 3 separate tasks (the three prongs of analyzing the credibility of the articles) in order to accomplish one comprehensive goal. We consider it a successful implementation in only 36 hours.
What we learned
By creating this project, we learned the basics of internet scraping, implementing machine learning to analyze scraped data, integrating a human element into a program to interpret the results of objective computations, creating a Chrome extension, and using various libraries within Python.
What's next for Fictus
The potential for this product is huge in a world where the need to authenticate information becomes more crucial by the day. Although this project is in its infancy, it could have massive applications for the typical user of the internet. With its simple interface, the casual internet surfer could use such a product to verify their daily news feed, adding to their experience of search engines and news sites. In addition, social media corporations could use this product to comb through their user’s data to determine if its credibility and display that information to other users. Corporations such as Facebook and Twitter are currently researching ways to filter so-called “fake news” from their platforms, and a method such as Fictus could be employed to accomplish this task.
Built With
- beautiful-soup
- chrome
- html
- http-server
- javascript
- machine-learning
- python
- sklearn

Log in or sign up for Devpost to join the conversation.