Inspiration
We are Team Outcast, named so because we were the last two people to team up. As heavily introverted programmers, we struggled to get proper mock interviews and so we decided on creating "Fenrir", a mock interview buddy that is always available. The idea fit well into the transformative learning track so we went all in! The name Fenrir came from the favorite voice we picked from Gemini TTS.
What it does
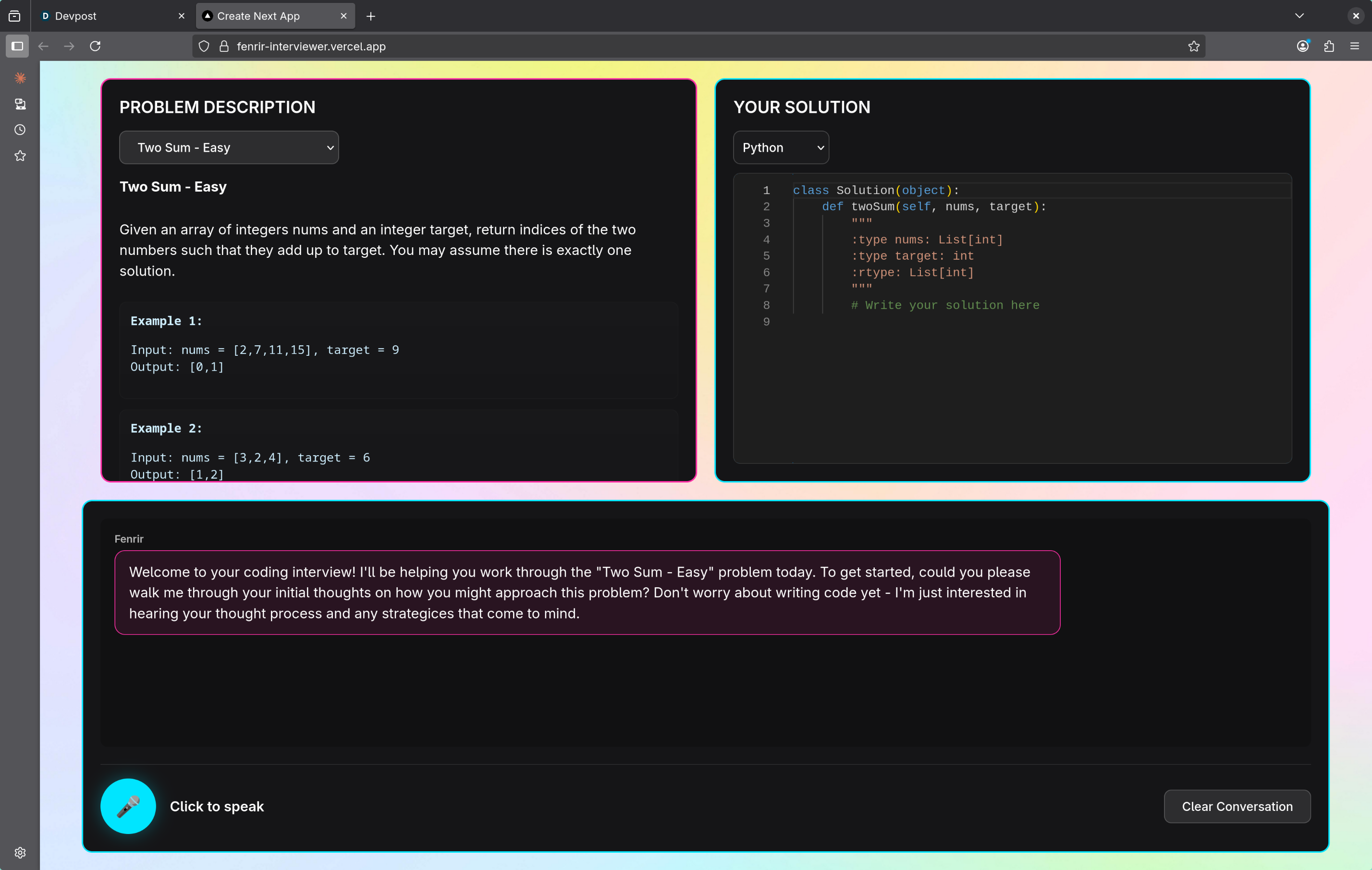
Fenrir Interviewer is an AI-powered technical interview platform that conducts real-time voice conversations while candidates solve coding problems. The system features:
- Voice-First Interaction: Candidates can speak naturally to discuss their approach, ask questions, and explain their reasoning
- Code Scratchpad: Live Monaco editor with syntax highlighting for Python, JavaScript, and Java
- Problem Selection: Curated coding challenges from easy to medium difficulty (Two Sum, Valid Palindrome, Fruit Into Baskets, Course Schedule II)
- Contextual AI Responses: The interviewer understands both the conversation history and current code state to provide relevant guidance
- Natural Conversation Flow: Pause detection and turn-taking that feels like speaking with a human interviewer
How we built it
Frontend Architecture:
- Next.js 15 with React 19
- Monaco Editor integration for code editing experience
- Deployed to Vercel
Voice Processing Pipeline:
- AssemblyAI RealtimeTranscriber for speech-to-text with end-of-turn detection
- Custom audio processing worklet for real-time audio streaming at 16kHz
- Google Gemini TTS API with "Fenrir" voice preset for natural-sounding responses
AI Integration:
- Google Gemini API for generating contextual interview responses
- Problem-specific context injection including hints, approaches, and complexity analysis
- Conversation history tracking to maintain interview continuity
Technical Challenges Solved:
- Real-time audio processing with proper resampling and browser compatibility
- WebSocket management for continuous speech recognition
- Silence detection with debouncing to handle natural speech patterns
Challenges we ran into
Audio Processing Complexity: Building reliable real-time audio streaming proved challenging. We had to implement custom resampling from various browser audio contexts to the required 16kHz format, handle different sample rates across devices, and ensure consistent audio quality.
Natural Conversation Flow: Creating pause detection that feels natural was surprisingly difficult. We implemented a debouncing system with 3-second silence timeouts to distinguish between thinking pauses and actual end-of-turn, preventing premature interruptions.
Assembly-AI: Despite how wonderful their realtime transcription turned out, the pain and misery it took to get there was... unspeakable. Too many hours spent debugging, looking through outdated documentation and code. Only to realize, connecting to the websocket manually and reading the API Reference is more convenient. Their SDK is wack!
High Latency: We originally tried to lower latency through audio-to-audio processing using Gemini Live, however, we were not able to process the audio within the limited quota of the day. (Only 15 requests per day!) We were quickly rate limited, and so decided on accepting higher latency for more reliability where we use AssemblyAI for STT, then feed transcripts to Google Gemini for TTS. The audio-to-audio flow then became a hacky audio-to-text-to-audio.
Accomplishments that we're proud of
- Voice Interaction: Achieved natural conversation flow that feels like talking to a human interviewer
- Real-Time Performance: Zero-latency code editing with simultaneous voice processing
- Context Awareness: The AI interviewer understands code changes and provides relevant guidance based on both conversation and implementation progress
- Functional Audio Pipeline: Built a fault-tolerant audio system that handles network issues, browser differences, and various audio hardware configurations
What we learned
Voice UI Design: We discovered that designing for voice interaction requires different patterns than traditional web interfaces. Timing, feedback, and state communication become critical for user experience.
Real-Time Systems: Building real-time applications taught us about WebSocket management, audio stream processing, and the complexities of coordinating multiple asynchronous data flows.
AI Context Management: We learned how to effectively structure prompts and maintain conversation context to create more natural AI interactions, especially when combining code analysis with conversational flow.
Audio Processing: Gained deep knowledge about browser audio APIs, sampling rates, format conversion, and cross-platform audio compatibility challenges.
What's next for Fenrir Interviewer
Bigger Problem Library: Expand to include system design discussions, algorithm optimization challenges, and language-specific problems across more programming languages.
Feedback System: Implement detailed interview analysis including code quality metrics, communication patterns, and personalized feedback generation.
Interview Templates: Create customizable interview flows for different roles (frontend, backend, full-stack) with company-specific problem sets and evaluation criteria.
Real-Time Collaboration: Enable human interviewers to join sessions, providing a hybrid AI-human interview experience that combines the consistency of AI with human judgment.
Built With
- assemblyai
- gemini
- javascript
- nextjs
- vercel


Log in or sign up for Devpost to join the conversation.