-
-
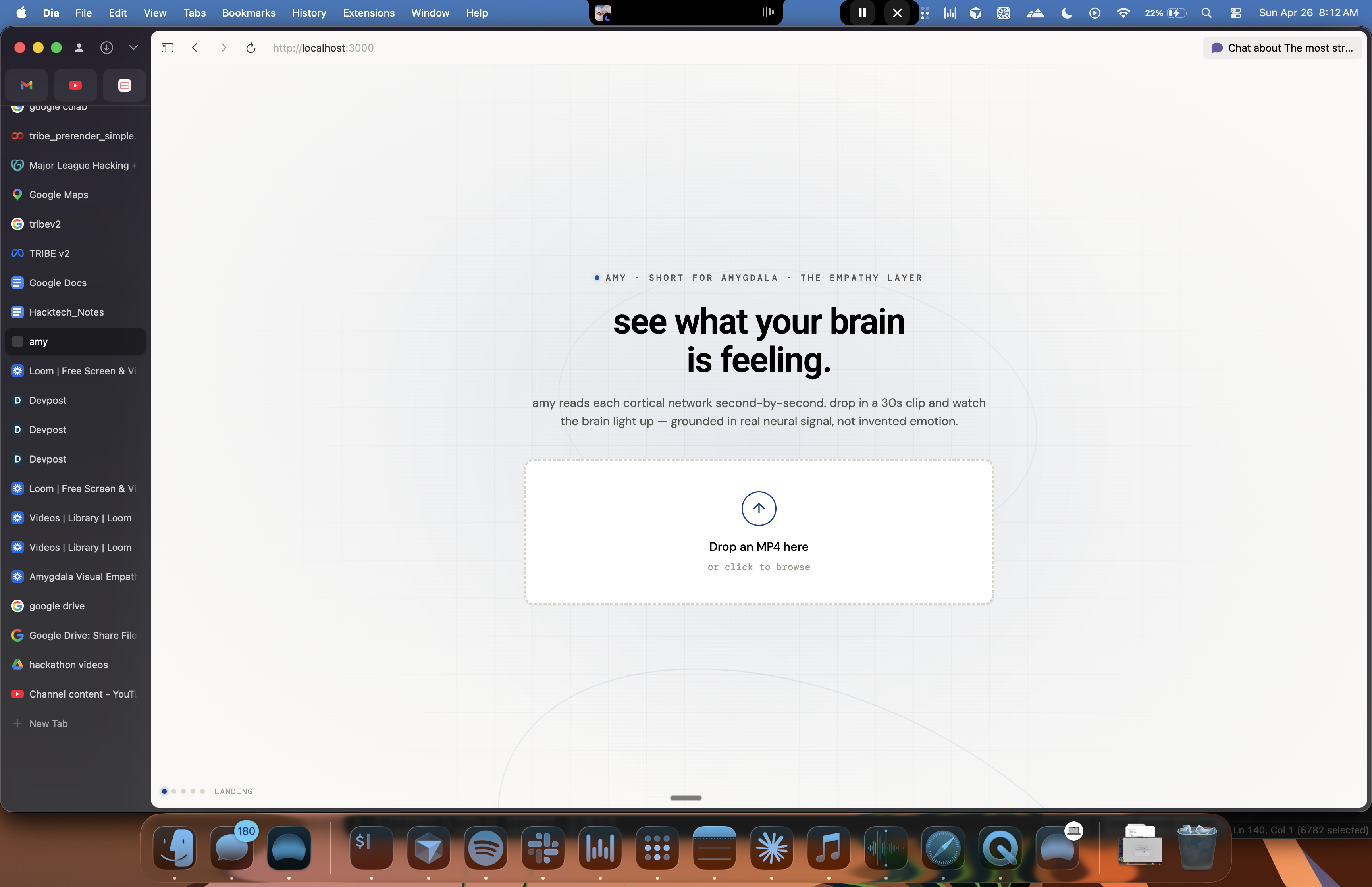
hero
-
video processing and swarm agent dispersion
-
Tribe v2 brain model
-
the brain model using k2 agents
-
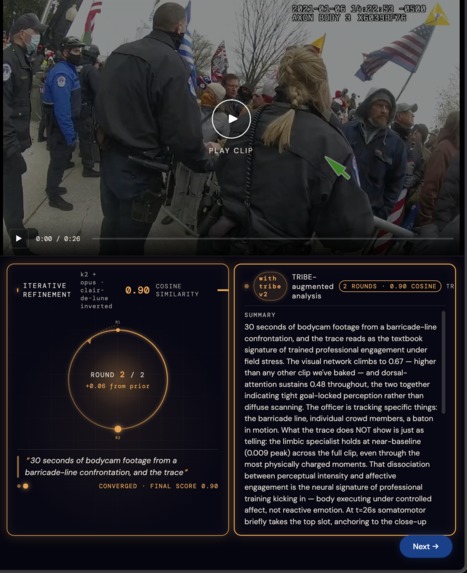
video player and the tribev2 analysis
-
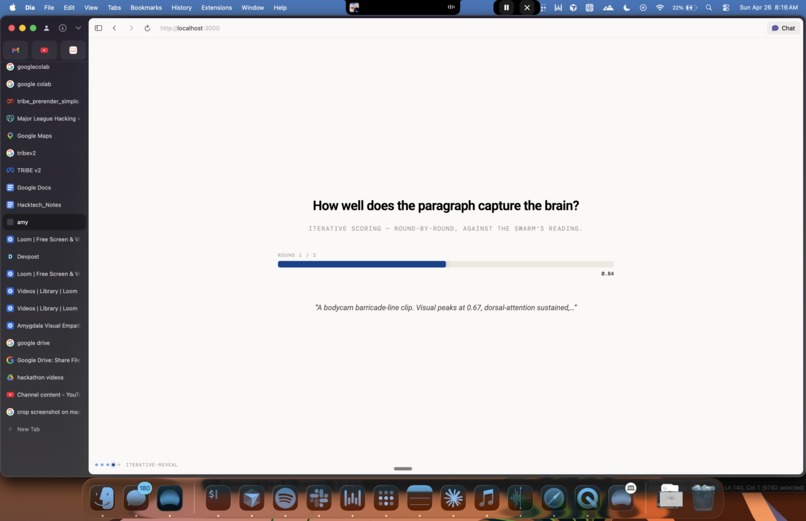
processing final document
-
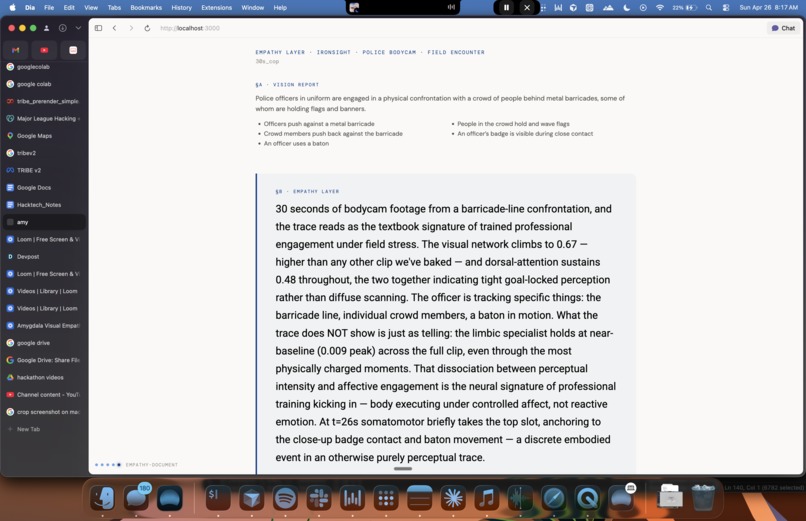
final document
-
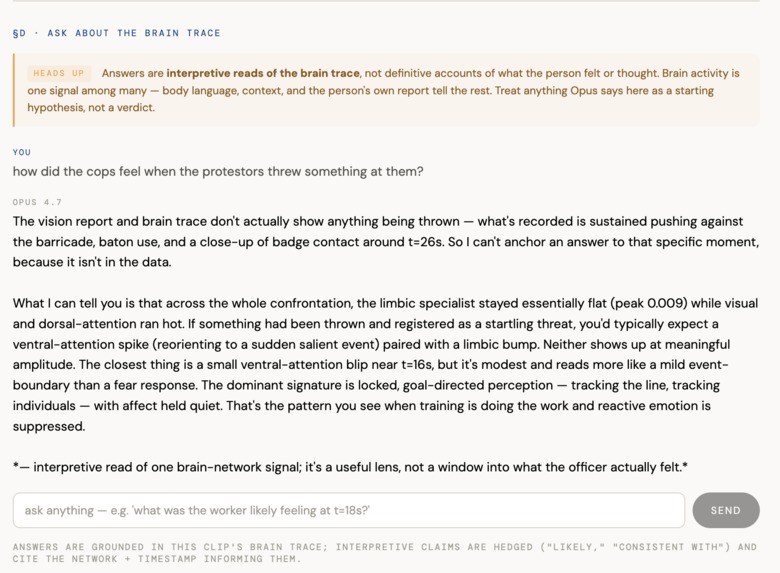
chat with agent about the video analysis

Inspiration
Your Spotify is no longer your music -- its a recommendation. Your youtube is just what you find on the home page that you refresh. The reels you watch, you cant even search for content.
The platforms that present themselves as expressive and allowing creativity, blackbox the very algorithm that optimizes for how your brain reacts to visual stimuli. This concept sparked our research into solving the translation between what an AI can see vs what we could meaningfully extract from what AI could feel using TRIBE V2.
That's the gap we built amy to close. AI is good at handling the data. From describing what people did, where they moved, how long it took, but AI can't tell you what they meant or why they did it. We watched footage across construction, healthcare, and education, all industries where a human gets reviewed by action data alone.
What it does
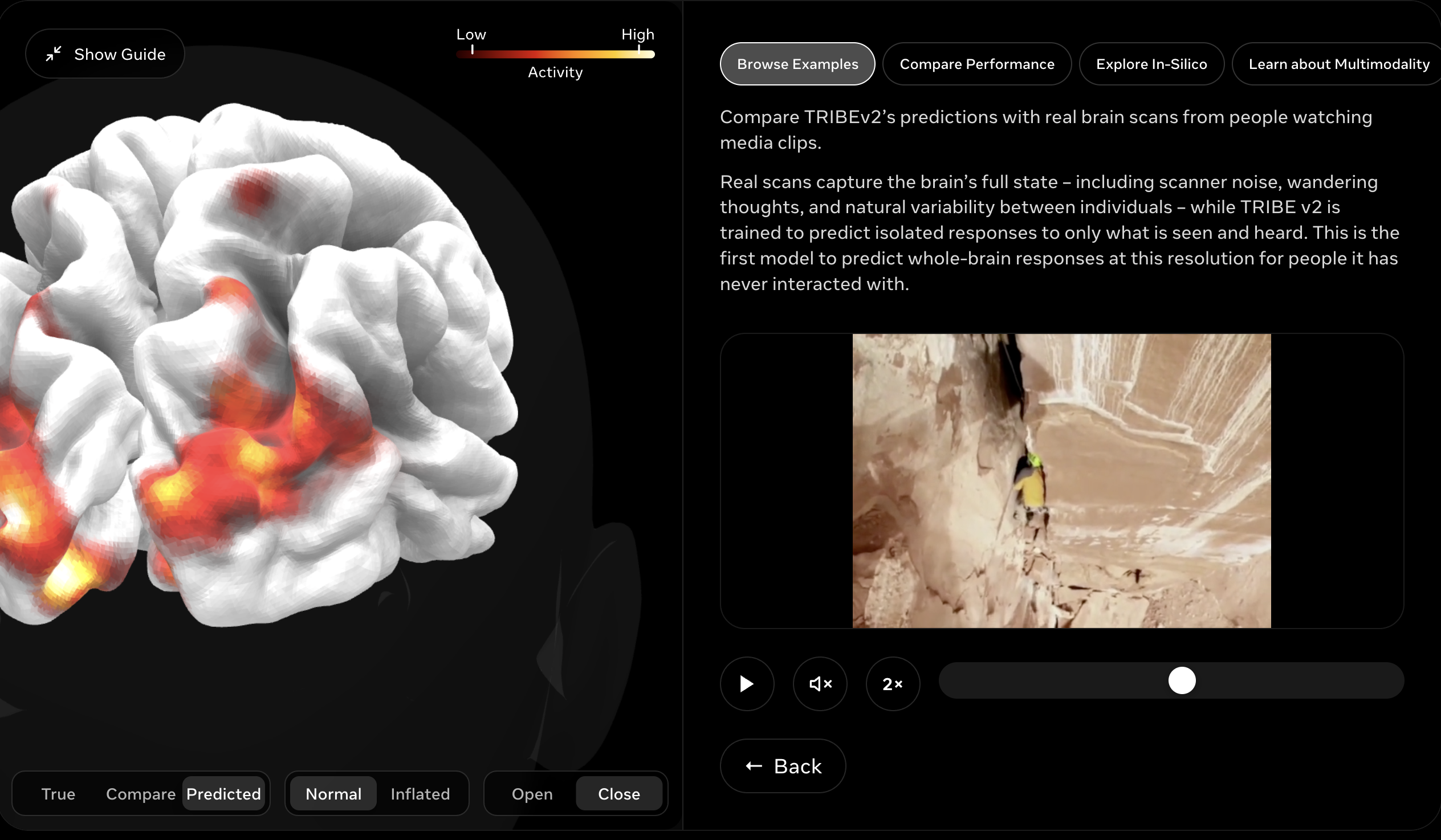
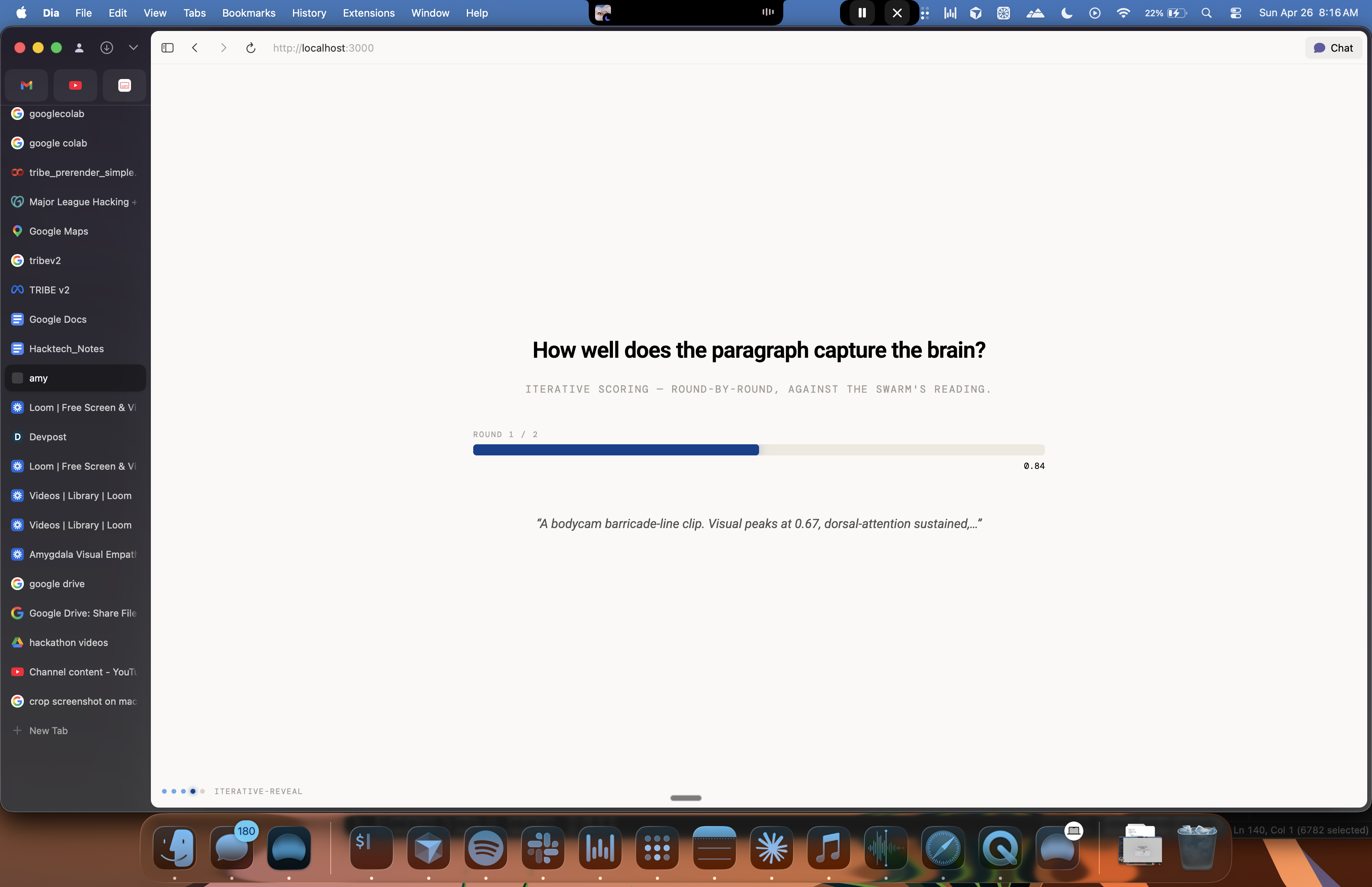
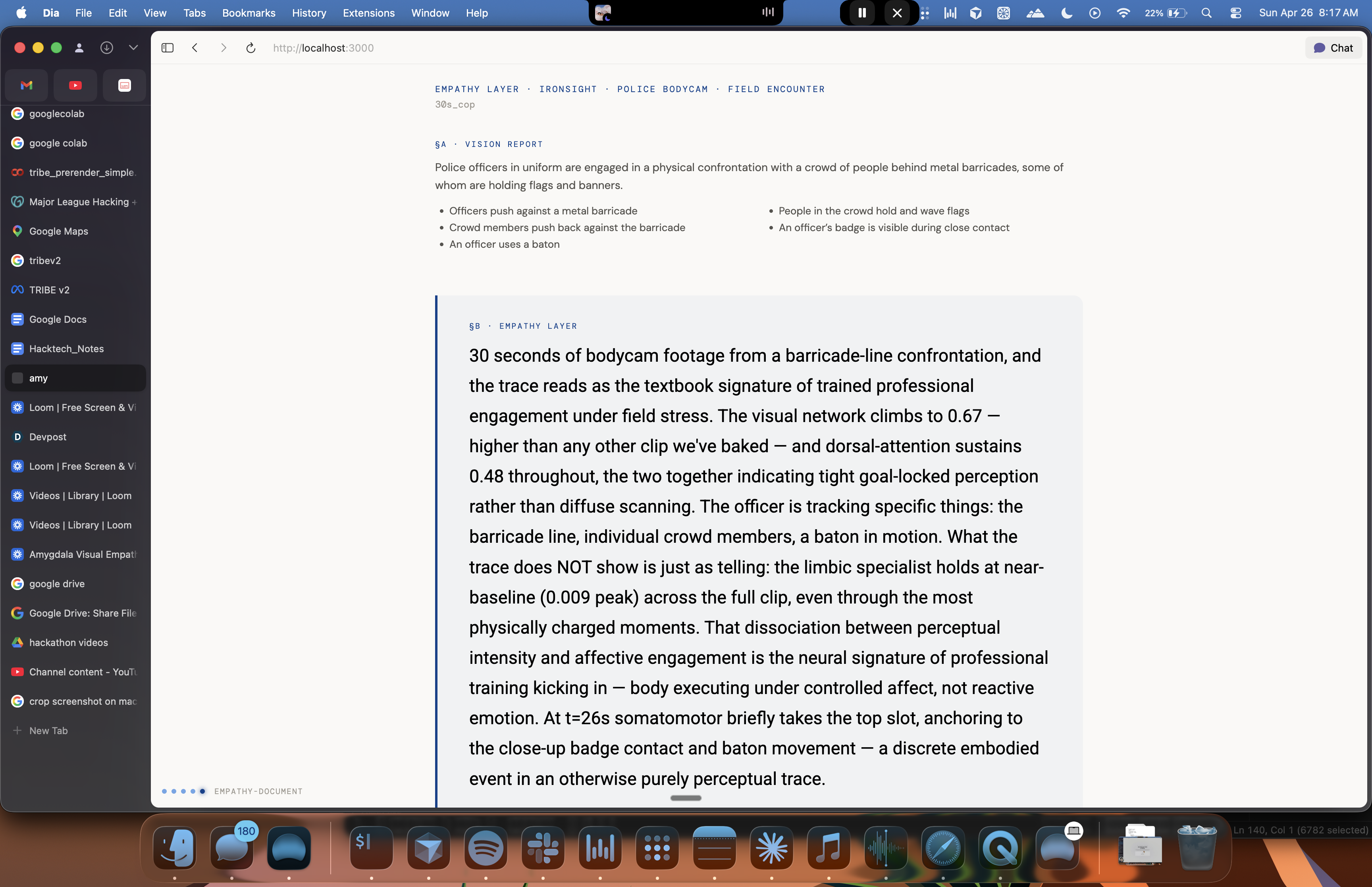
Drop in any visual stimuli where a human is doing something and someone else will make a decision about it later. Amy predicts second-by-second neural response across about 20,000 cortical points using Meta's TRIBE V2 brain-encoding model, then writes a paragraph anchored to that pattern.
Two numbers come with it: a similarity score against the brain pattern (how grounded the description is), and a falsification delta against control footage (proof it's anchored to this scene and not generic LLM output).
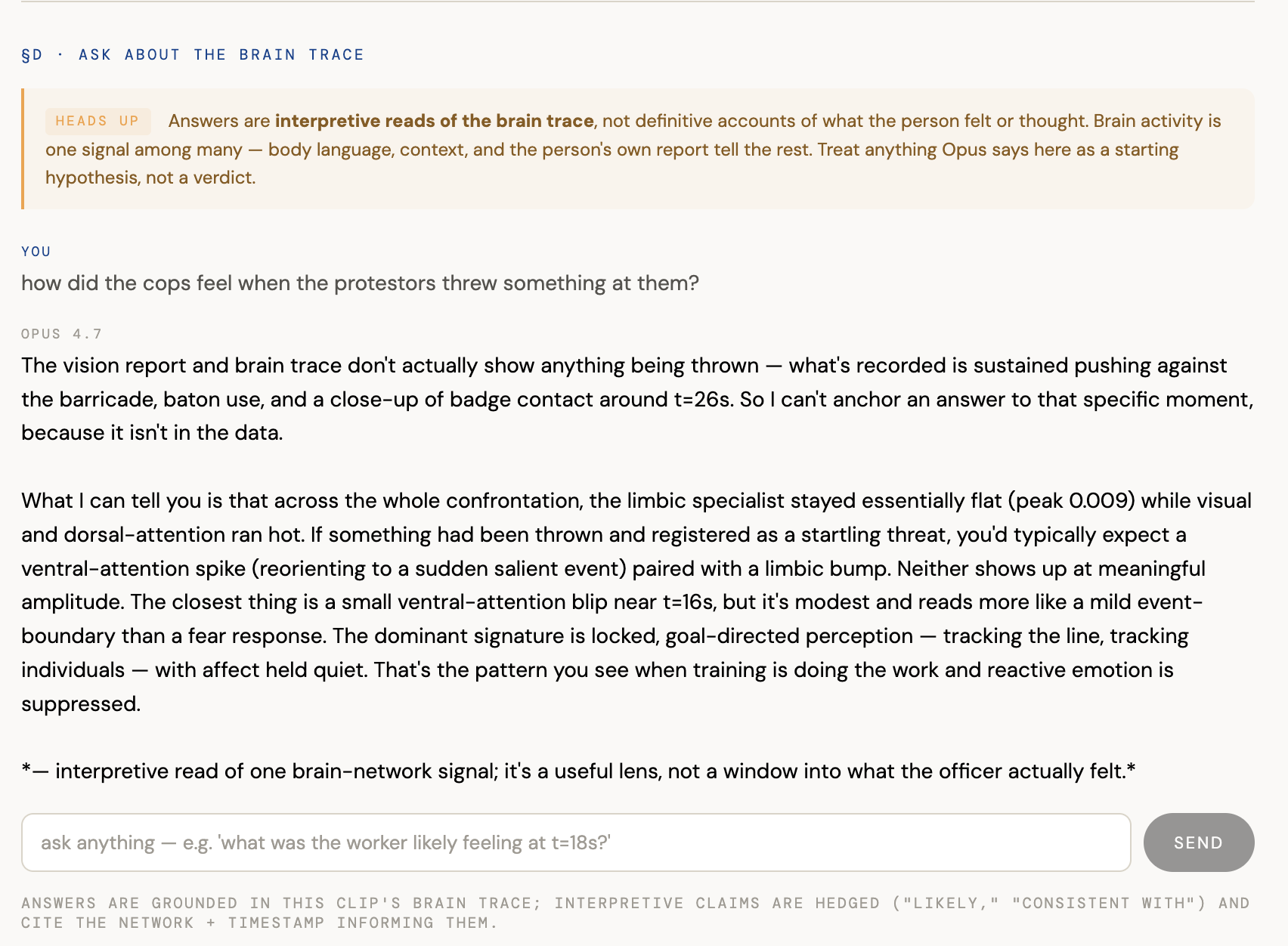
The empathy document also ships with an Opus 4.7 chat layer where viewers can ask follow-ups like "what was the worker likely feeling at 18s?" and get an answer hedged in calibrated language ("most consistent with focused inspection," "the limbic specialist stayed quiet through this stretch"), with every claim anchored to a specific network and timestamp from the trace. A persistent banner makes the contract explicit: these are interpretive reads, not definitive accounts of what someone felt.
How we built it
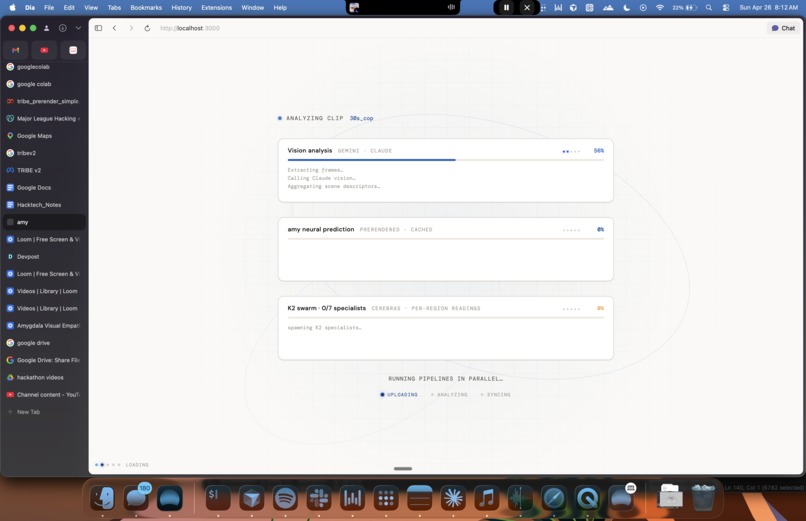
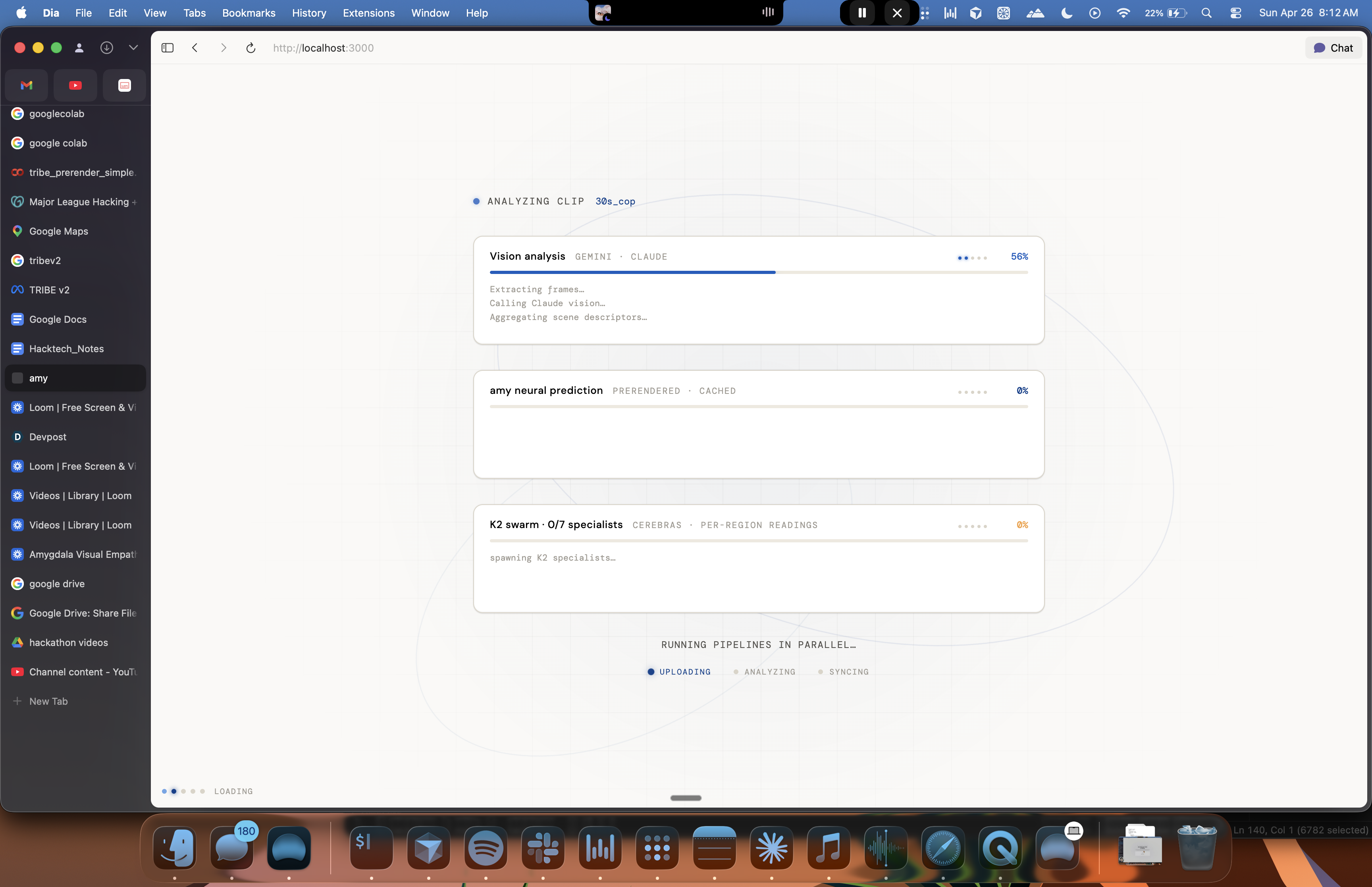
There are six stages.
- Qwen3-VL describes what the dashboard would have seen without us, the action-data baseline.
- Meta's TRIBE V2 predicts per-second neural response across ~20,000 cortical surface vertices on the fsaverage5 mesh, at 1Hz with a 5-second hemodynamic lag. (Treated as a stored neural baseline, think Spotify pre-computing recommendations, then streamed back in sync with the video. Heavy upstream inference, lightweight live playback.)
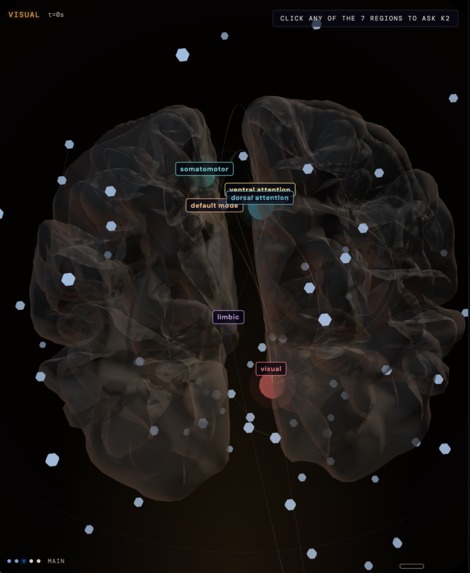
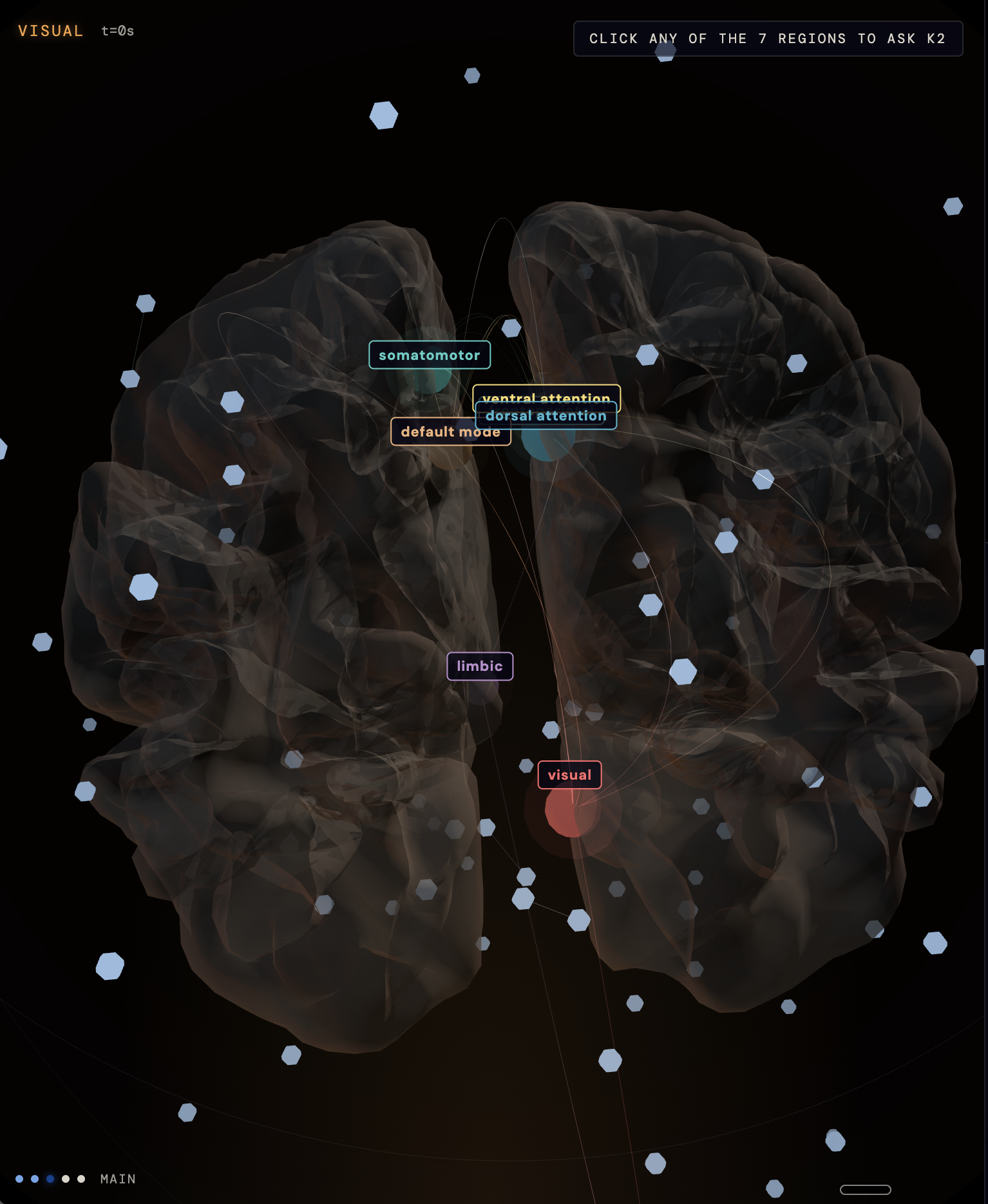
- A K2 Think swarm simulation w/Cerebras (~1,300 tok/s, seven specialists in parallel, one per Yeo7 cortical region) interprets what each region was contributing.
- Claude Opus 4.7 writes and synthesizes the report.
- Three rounds where Claude writes a candidate and K2 specialists score it forward against the actual brain pattern. Cosine climbs round by round.
- A falsification check against a control video.
- The empathy document mounts an Opus chat layer for live interpretive Q&A, grounded in the cached brain trace, hedged by design, with a forbidden list (no clinical claims, no sub-second predictions, no fabricated detail).
- CLOUD GPU used to process and run Tribe v2 llama 3.2 8b open source model for processing videos
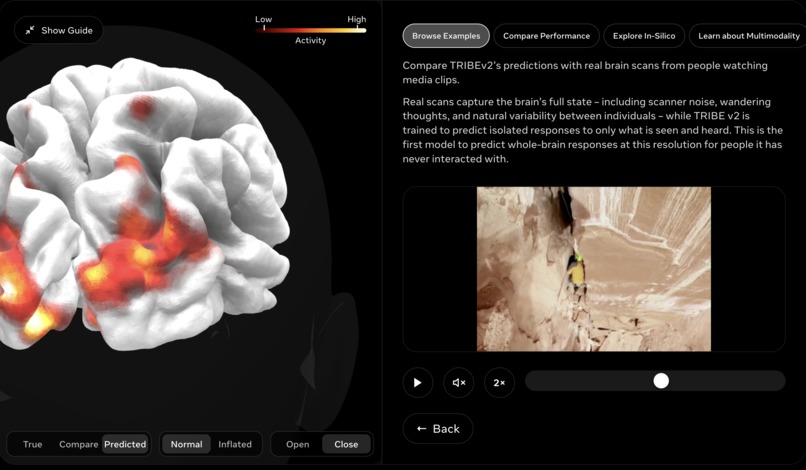
The methodology comes from prior work. The iterative loop matches Clair de Lune's neural fingerprint to 90.4%, run in reverse. The frontend is Vue 3 + Vite + Three.js branded around a clean research design system. The cortical mesh renders all 20,000 vertices in sync with the footage at 30fps. The backend is FastAPI with a WebSocket layer.
We currently ship seven prerendered demo clips spanning workplace and consumer scenarios, three construction-site bodycam variants, a police bodycam encounter, a classroom lecture from a student's perspective, an Instagram scroll, and a Twitter feed. We did this to prove the architecture generalizes across genres without needing extensive retraining for specific scene.
Challenges we ran into
Honestly, the hardest part was processing the videos. The TRIBE V2 pipeline started in Jupyter and the notebooks were slow The frame extraction, brain-encoding inference, writing per-second activity JSON for ~20,000 vertices, all of it felt like it took an eternity. We ripped it out of the notebook into a parallelized batch pipeline to extracted the frames in one pass. Then, TRIBE V2 inference batched on a GPU, and the activity JSON was serialized into a compact streamable format. A 30-second clip went from minutes to seconds.
The second hard problem was the K2 moderator endpoint timing out under concurrent load. We lost a full bake cycle to it before adding a 300s timeout, a per-round skip-on-error defense in the iterative loop, and a frontend filter that drops malformed round excerpts so a backend hiccup never leaks onto the demo screen.
Accomplishments that we're proud of
We inverted a published protocol. The Clair de Lune work hit a 90.4% match across 20,484 vertices in the emotion center, running forward to score candidates against a target brain pattern. amy runs the same loop in reverse, with the brain pattern as the source. We didn't invent the methodology this weekend; we used a credibility chip that was already public. Across our demo set the iterative loop scores 0.85 → 0.95 cosine in 3 rounds. Under 60 seconds. About three cents a run. Falsification deltas of 0.18–0.21 confirm the descriptions are anchored to each specific clip and not generic prose.
We're also proud of the calibration work. Building the Opus chat layer forced us to draw the line between predicting neural response and reverse-inferring feelings in code, not just in a slide, every interpretive answer ends with an italicized "interpretive read of the brain trace; one signal among many, not the full story" caveat, and a yellow ethics banner sits permanently above the input.
What we learned
The line between predicting neural response and reverse-inferring feelings is the whole game. It's the difference between a product that augments management decisions and one that gets correctly torched by every neuroscientist in the room.
Brain-grounding is what separates genuine cognitive description from confabulation. Any LLM can write "she held space" if you ask it; the question is whether that paragraph would also score 0.85 against the actual brain pattern of the actual video. The score climbing is the falsifier. Without it, it's a style trick. With it, it's a measurement.
The chat layer drove the same lesson home from the other side: we had to design hedging directly into the system prompt, because the easy answer ("she felt anxious") is the unfalsifiable one. Grounding the answer in a network + timestamp is what makes it falsifiable — and therefore real.
What's next for amy
Workplace fine-tunes are the must-do. TRIBE V2's canonical training set doesn't include workplace footage; industry-specific fine-tunes close the gap on the inputs we actually want to serve.
Streaming inference comes next. We run on 30–90 second clips today. We hope to extend the architecture extends to streaming windows in real time, a manager seeing the empathy layer overlay a live bodycam feed, with the chat layer answering "why did engagement drop in the last 90 seconds?" anchored to the trace as it accumulates.
Built With
- anthropic
- fastapi
- javascript
- k2-think
- meta-tribe
- opencv
- openrouter
- python
- qwen
- three.js
- typescript
- vite
- vue






Log in or sign up for Devpost to join the conversation.