-
-
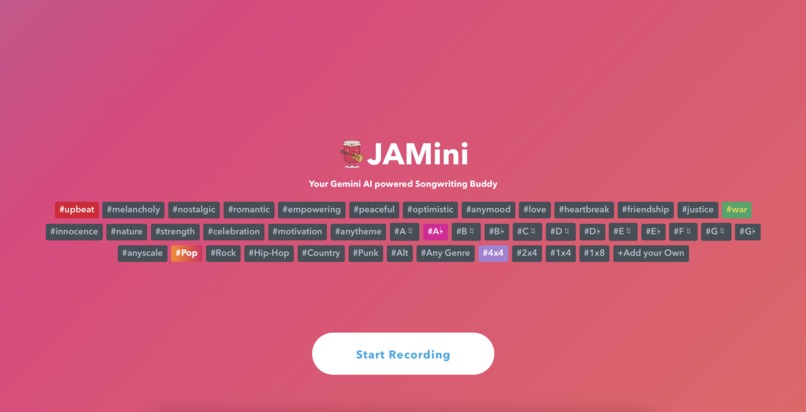
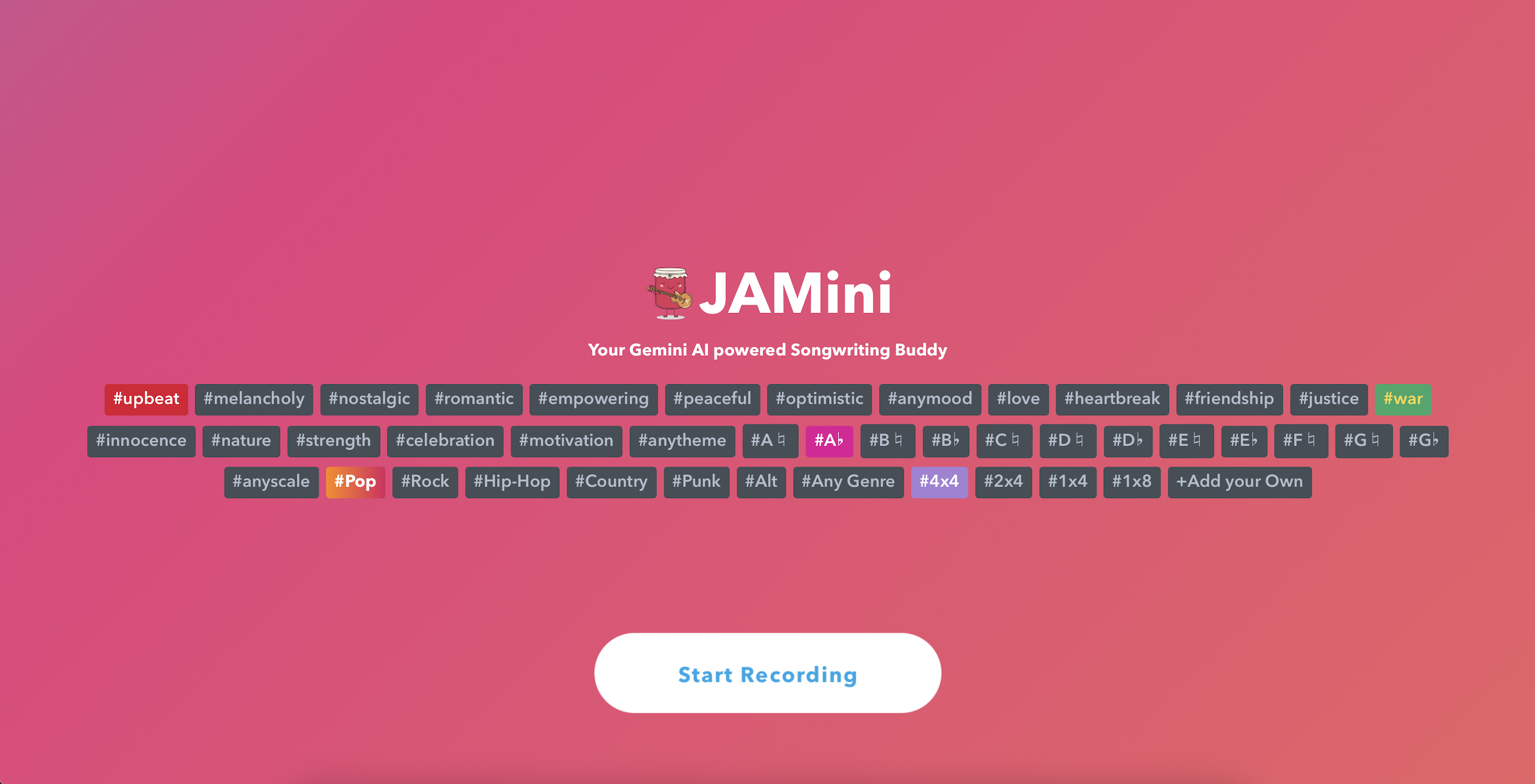
Add modifiers along with a short 6-10s audio prompt to change the tone of the recorded song
-
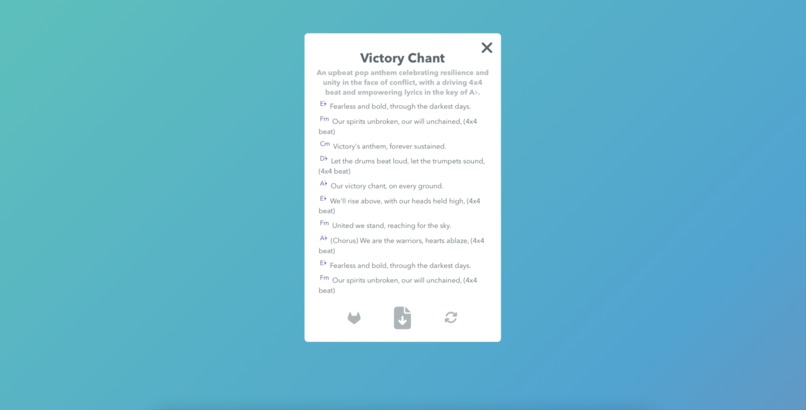
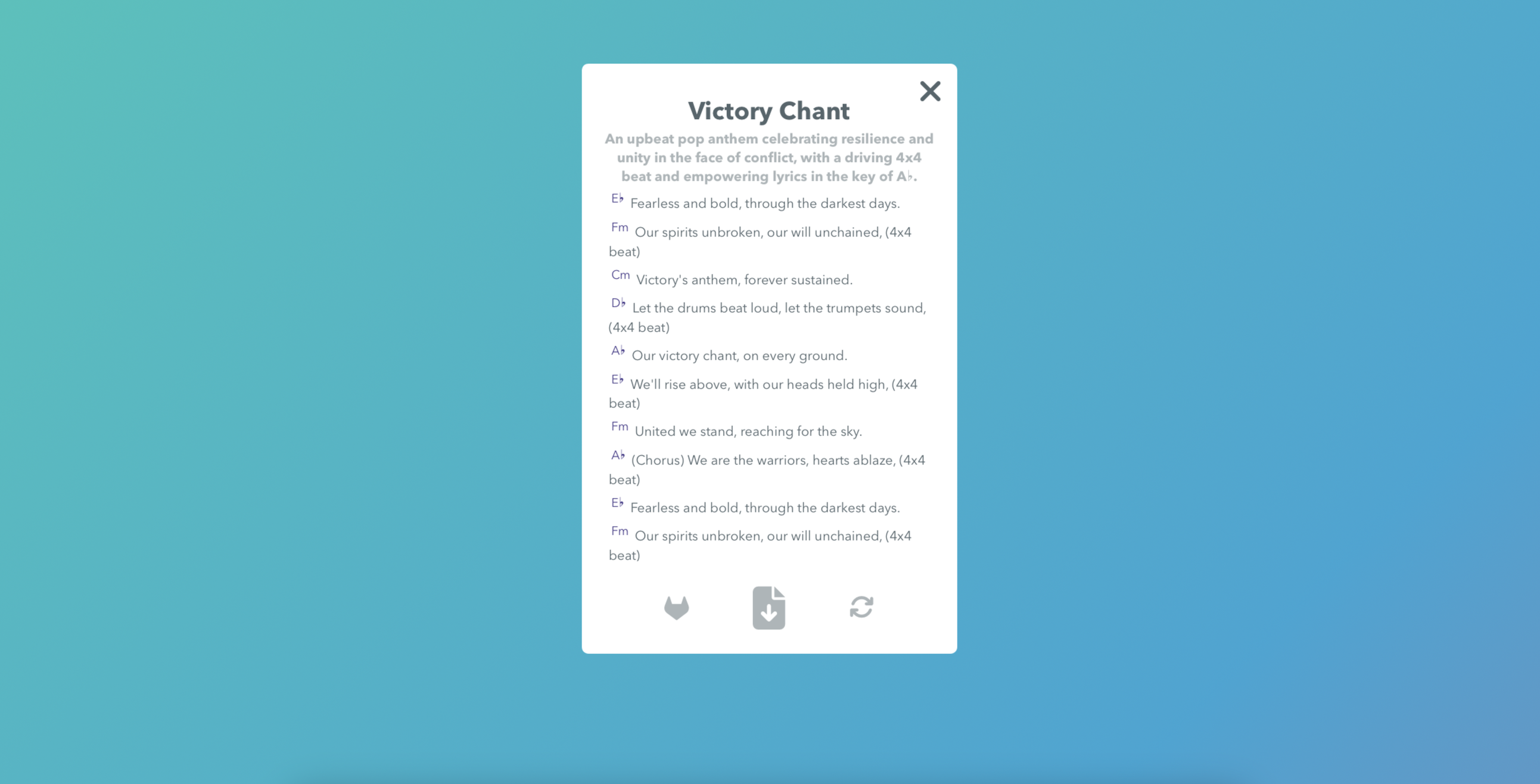
Outputs with notation and beats to rapidly prototype a song tune
-

Refresh outputs to truly JAM with Gemini and get an awesome song output

Inspiration
The recently launched Gemini Multimodal Prompting API for Gemini 1.5 Pro in the Beta v1 API gave us the idea to solve a long running question we had: What if we could use Gemini to complete songs. Not just in terms of lyrics, but In Tune and with the Same Theme as it is being sung/played in. With enough flexibility to alter it by adding a Mood, Theme, Genre or Style. This allows artists to rapidly prototype song ideas, cure mental blocks or brainstorm ideas with just a few lines and notes predefined.
Here's what our UI looked like, with options for selecting any of the above prompt modifiers, plus a custom text modifier, and then using the browser Javascript's built in getUserMedia API to record a few seconds of a voice singing a song, musical instruments optional.

What does it do
JAMini records short audio (6-10s) directly in browser of a verse of a song, and then completes the song in the same scale (or makes changes according to your prompting). The audio is not stored or understood in any speech to text format, instead it is only used by us on the client side to prompt Gemini. The flowchart below describes it quite well.
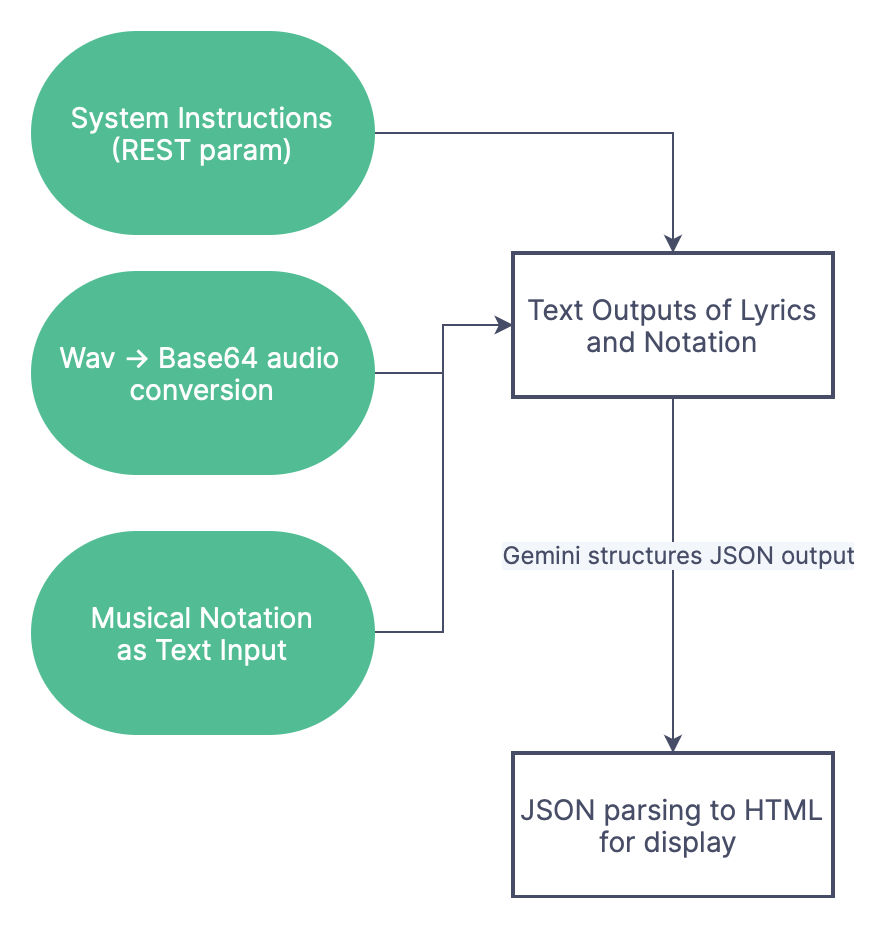
Solves a Problem: It takes most hobbyist singers very little time to think of 2-4 lines for a verse, but a lot longer to complete the song in a meaningful way that makes sense. Gemini acts as a helpful assistant and adds to the creation process that works alongside the artist without trying to replace them.
How we built it
We used the experimental API features from v1 beta, and also ran into some issues (that we submitted as feedback) while generating using the experimental features. From the available features in the API We used:
- Audio WAVs encoded as
Base64for REST inputs - System Instructions for
JSON Outputs - Safety Checker for
High Probabilities Only(for multilingual outputs the checker is aggressive ) Musical Notationsas Textual Context (Gemini sometimes messes these up)
We were pleasantly surprised by the language awareness of Gemini in terms of handling multilingual audio inputs natively. We did not have to write even a line of preprocessing or context setting code while providing inputs to Gemini in Hindi, German and even Korean. While some Indic languages (for example we tested unsuccessfully with Kannada) showed a lack of robustness, mostly we were able to get intelligible outputs from the model. Below is an example output of an English song with upbeat celebration themes and a specific keyword in prompts.
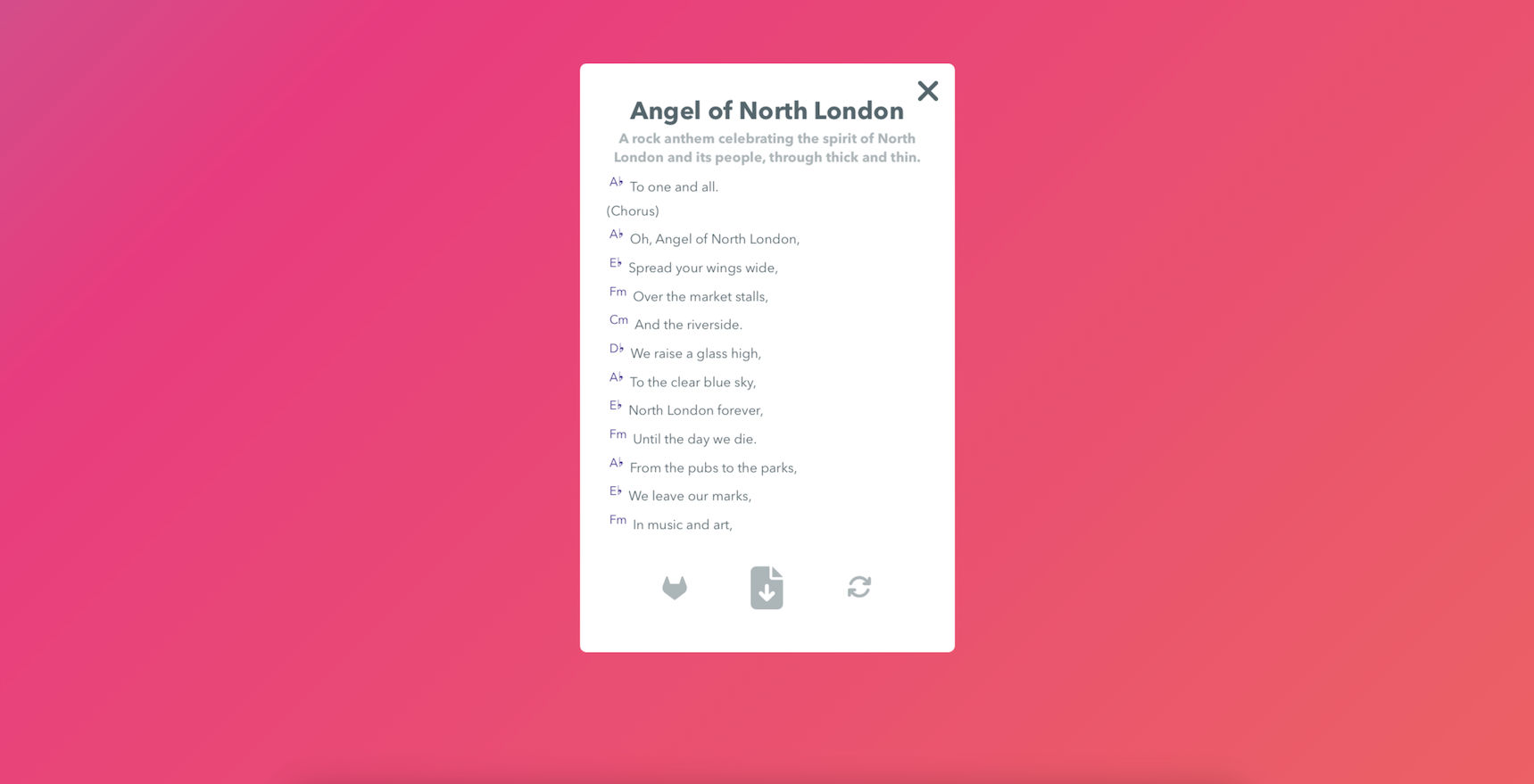
We could then get Human in the Loop Song Creation, with multiple iterations used to create the perfect song in the perfect key, that made sense to the artist. Basically we found the experimentation and brainstorming process for a creative artist could be reduced to a large extent, by incorporating AI ideas into the loop.

Challenges we ran into
We used the REST APIs purely from the client side in order to build encapsulated app logic without requiring servers. Here's the challenges we ran into since the API seemed to not support a lot of features in the REST API that we assumed would be supported; Also it seemed like there was some inconsistency of documentation between Vertex and Gemini Studio APIs. These are as below:
HarmCategorynot documented correctly (only 4 as opposed to 10 enum fields supported)- No
File blobupload support, ormultipart form data, instead everything needs to beBase64, and the base64 mime type needs to be removed from the string. This is not explicitly documented anywhere.
Accomplishments that we're proud of
We literally spent 5 hours singing to our laptops, with all sorts of useless lyrics and in extremely degraded keys, and got actual usable songs that made not just lyrical but musical sense as well. It was pretty incredible!
We believe the future is one where diffusion models are used to generate music as feedback to Audio modal LLMs, to provide artists a one-click experience where they think of a few lines as a theme for a song, and then get a catchy hook or bridge to complete the entire song. This would speed up the creative process by a lot, and also allow much faster production of music.
What we learned
Gemini 1.5 is a really powerful model. Multilingual and Multimodal is where it really shines! This makes developers lives much easier, since localisation worries are a thing of the past. We used Gitlab CI to deploy our app and you can view the code in our repo here: https://gitlab.com/bitanathed/jamini
What's next for JAMini - Song Autocompletion with Scale Shifts using Gemini
We'd really like to experiment downstream tools like audio generation to completely auto generate a song from just a few seconds of audio. We also hope someday Gemini gets Audio Generation Capabilities, something like an audio2audio model where humming a tune could generate a song with the correct scale, rhythm and themes. It would have immense practical significance, think of the birthday rhymes or advertisement jingles that could be sung in a commercial or non-commercial setting, simply, casually and easily using Gemini.


Log in or sign up for Devpost to join the conversation.