-
-
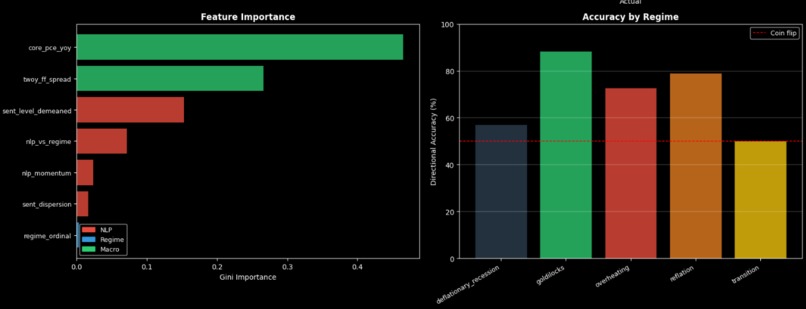
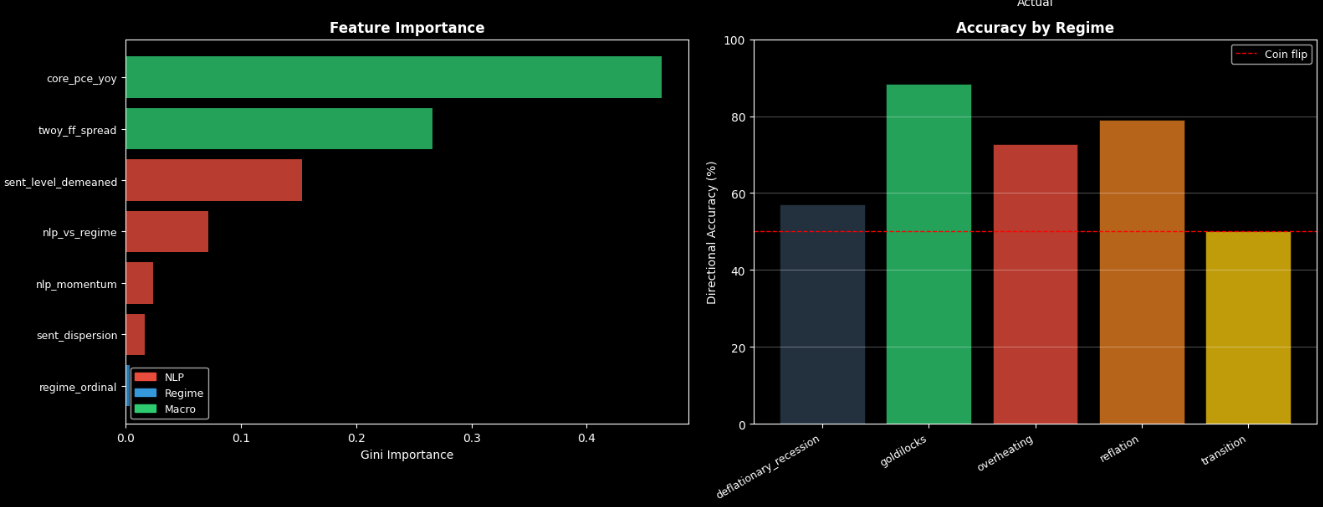
Feature importance vs Regime change
-
Main UI
-
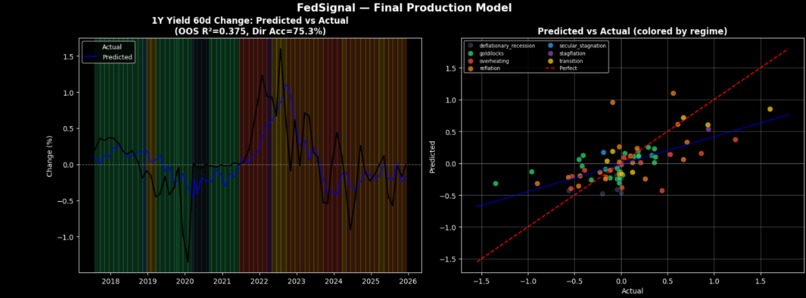
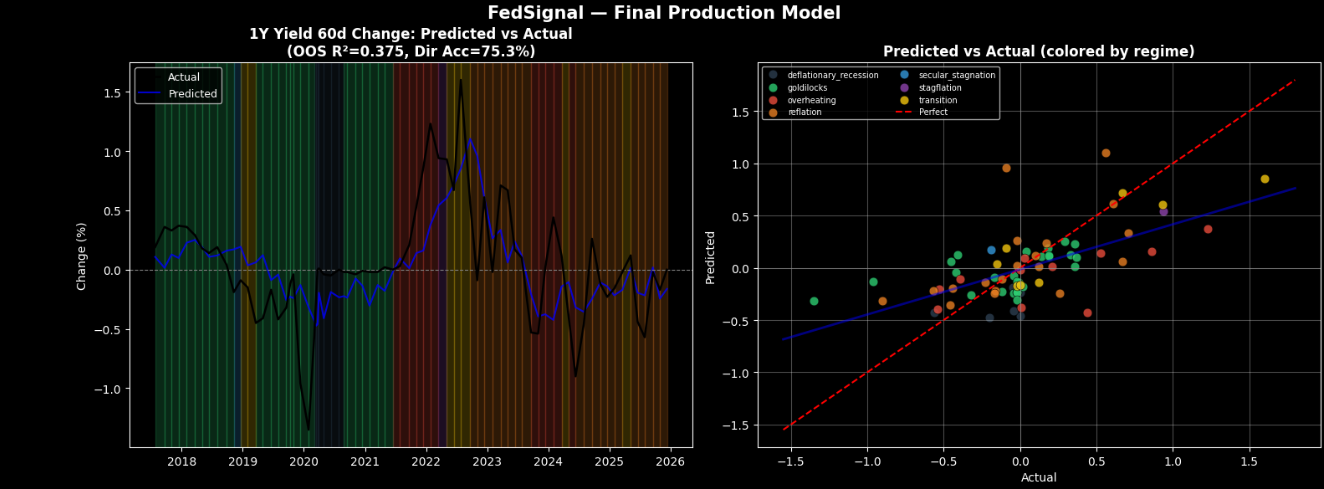
Predicted vs Actual (Accuracy)
Inspiration
Looking for market inefficiencies. Optimizing trading efficiency using Machine Learning to analyze data
What it does
FedSignal predicts short-term yield changes following central bank meetings across three countries:
US: A Gradient Boosting model using 7 features (NLP sentiment, NLP momentum, NLP-vs-regime surprise, sentence dispersion, 2Y-FF spread, Core PCE, economic regime) with walk-forward cross-validation
Australia & UK: OLS models using NLP sentiment + short-rate spread with leave-one-out CV
How we built it
We pulled US macro data from the FRED API and scraped central bank statements directly from the Fed, RBA, and BoE websites, caching both to avoid re-fetching. We fine-tuned a separate DistilBERT model for each central bank on hand-labeled training sentences (88 for the US, with dedicated sets for AU and UK), scored 0–1 from dovish to hawkish. New statements are scored sentence-by-sentence and averaged into a single sentiment score.
For the US model, we engineered 7 features including an NLP surprise term (sentiment relative to what the current economic regime would predict) and NLP momentum (deviation from an exponential moving average), then trained a shallow GradientBoostingRegressor with walk-forward CV. AU and UK used linear regression with LOO-CV given smaller sample sizes. The prediction target is the 60-day change in the 1-year yield, chosen after testing 1-, 2-, 3-, and 60-day horizons — all shorter windows produced negative OOS R².
Challenges we ran into
Data leakage: An early model trained directly on 60-day yield changes hit OOS R² of 0.645 — far too high. Correlation analysis showed the model had memorized labels (r = 0.821) rather than learning language. We rebuilt the NLP training pipeline to use zero market data.
Scraping heterogeneity: The Fed, RBA, and BoE each format their press releases differently across years. We wrote dedicated parsers for each with fallback logic for edge cases.
Small AU/UK samples: Not enough observations to apply GBR + walk-forward, so we kept those models at 2 features with LOO-CV to avoid overfitting.
Yield data for AU/UK: Standard APIs were unreliable, so we built a multi-source fallback chain: RBA/BoE direct statistical tables → investing.com → WSJ → pandas-datareader.
Accomplishments that we're proud of
The US model (75.8% directional accuracy). We also caught and fully documented the leakage issue rather than reporting inflated numbers. The nlp_vs_regime feature — how hawkish a statement is relative to what the current economic regime would predict — is a construct that measures policy surprises rather than policy levels. And each central bank has its own DistilBERT model calibrated to its specific communication style
What we learned
Short-horizon prediction (1–3 days) is essentially impossible with NLP — markets reprice statements within hours, so every method we tried produced negative OOS R² at those windows. The 60-day horizon works because the statement sets a policy narrative that shapes how subsequent data releases get interpreted over the following two months. We also found that the yield spread does most of the predictive work directionally, but the NLP score adds marginal information about the pace of policy that the spread alone misses.
What's next for FedSignal
1) Expand to more countries 2) Continue to improve the models 3) Try to find more relevant data to train on

Log in or sign up for Devpost to join the conversation.