-
-
fed avg job sim
-
login init ui/ux
-
user init ui/ux
-
-

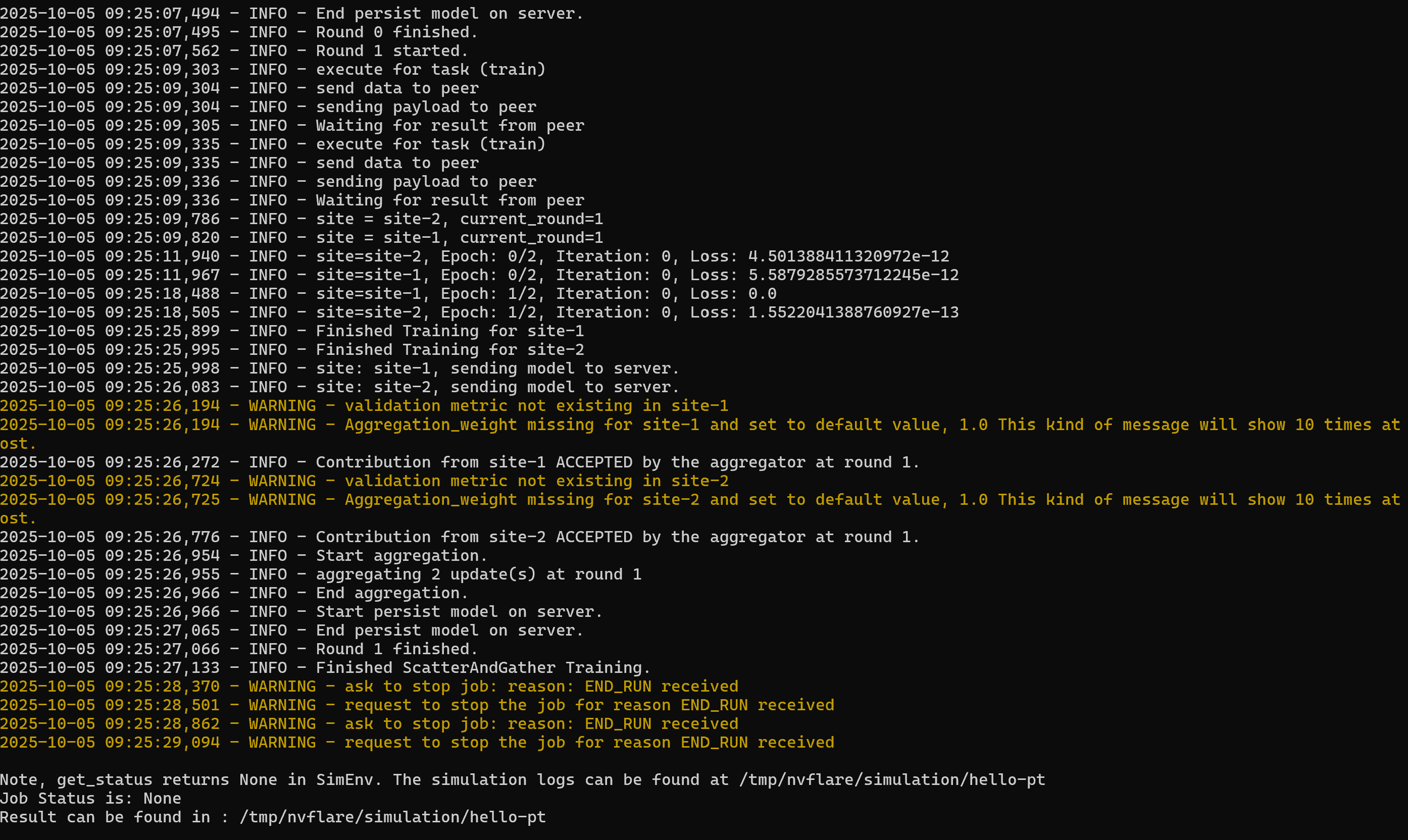
init testing model
-
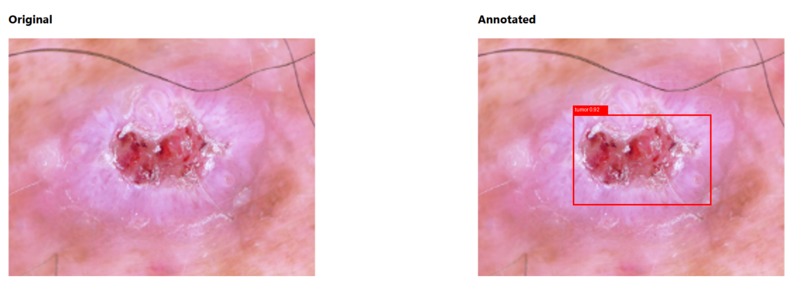
init testing model 2

Inspiration
A lot of concerns have been raised about the environmental impact of training LLMs. Every year, data centers across the US have used exponentially more energy for AI, making it necessary to find ways of training large models without running hundreds of GPUs around the clock. To make matters worse, models are finding it more difficult to find good data for training, due to lack of data publicly available for use. One example of this is in hospitals, where a lot of models are difficult to fine-tune to the HIPPA regulations that prevent hospitals from sharing patient data. Federated learning was a method we found recently that was explored in NVIDIA Flare's API tools, so we figured now was the best time to investigate alternatives to training models other than what is traditionally done today.
What it does
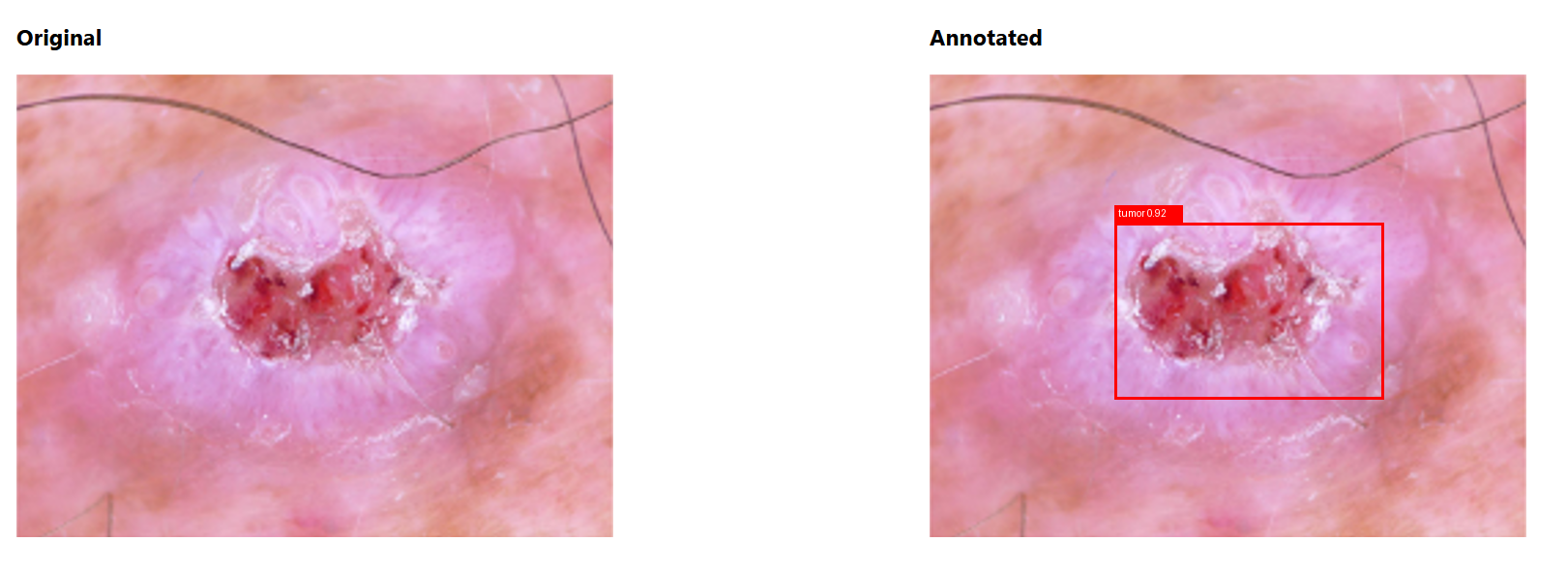
We attempt to provide a web application that allows hospitals to host their own local models, so that there is no need for them to send private patient information over a network. Instead, they use their data in-house to train a local model and then send the updated version of that model to a global model on a central server. This global model will train on an aggregate of many smaller models across different hospitals, then feedback the global model's updates back to the local model. The model itself is a CNN that attempts to label and classify tumors based on X-ray scans.
How we built it
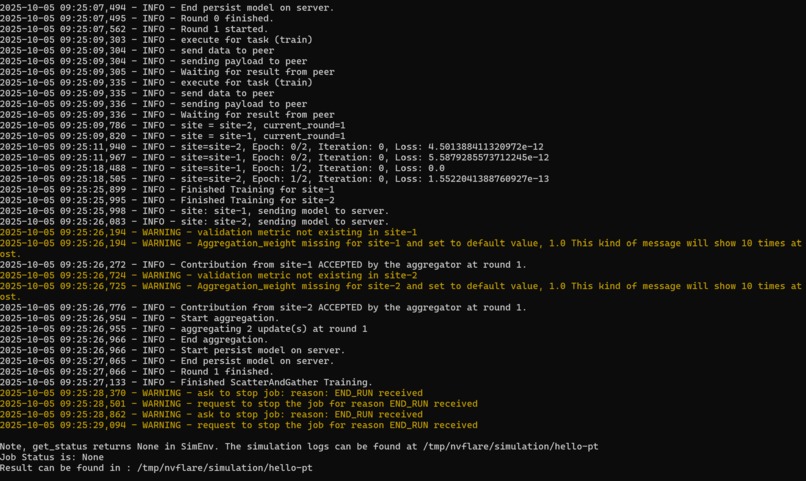
We used NVIDIA Flare's API tools in order to set up the federated averaging algorithm between the server and clients. Pytorch was used to build the model and send weights between the server and client for training. Flask and React were used to create the initial web application for hospital login and accessing the NVIDIA Flare API. We also used the NIH-Chest-Xray-14-subset to quickly train our smaller models and demonstrate that the federated averaging algorithm works.
Challenges we ran into
Doing networking with NVIDIA Flare had a lot of issues. Version control was a big rate limiting factor in completing the project, as we figured out much later on that we needed to revert to Python 3.10 and exclusively use x86 in order for some of the features to work. Also, a lot of the secure hashing algorithms to allow the server and client to communicate were unstable in our build -- so we were only able to simulate and remove the secure communication features usually used in federated learning. In addition, we tried to deploy our services on the cloud (we tried both Google Cloud and AWS..), but for whatever reason NVIDIA Flare was not compatible with Google Cloud and we could not get AWS VM to boot.
Accomplishments that we're proud of
We managed to successfully simulate a few rounds of federated learning! We also got to visually see the labelling with the tumors in our dataset. Lastly, we were able to get some of the UI working on the front-end in React/Vite.
What we learned
We learned a lot about NVIDIA Flare and different algorithms to decentralize training. Figuring out this API was a ton of work and reading through documentation, but it was totally worth it. We also learned how to quickly scale a web app in a small team, since we tried out SCRUM on GitHub and tried to collaborate to ship a full-stack application.
What's next for Federated Learning for Hospitals
In the future, we want a fully functional secure communication channel between the global model and local models. We also want to apply this algorithm to other use cases, since it has a lot of potential in robotics and industry and finance! Also, we want to add other optimization techniques like distillation so that we can have a larger global model distilled into much smaller models that can be run on edge devices. This would allow a network of phones/laptops/embedded systems to collaborate with each other to make an ultra powerful model despite the data scarcity issues plaguing the real world right now.


Log in or sign up for Devpost to join the conversation.