Inspiration
Every six weeks, the Federal Reserve makes a decision that moves trillions of dollars. Markets hang on every word, analysts debate endlessly, and yet, most prediction approaches boil down to gut instinct or looking at one indicator in isolation.
I've spent 18 years in fintech (Mastercard, Scottrade, Wells Fargo, now Capital One) building systems that process financial signals at scale. The question that kept nagging at me: can a machine learning model trained purely on publicly available macroeconomic data actually predict what the Fed will do, especially during the unprecedented shocks of COVID-19 and the 2022-2024 rate hiking cycle?
This project is my attempt to answer that question rigorously, with reproducible code and interactive exploration.
What it does
The Fed Policy Shock Predictor is an end-to-end machine learning pipeline that:
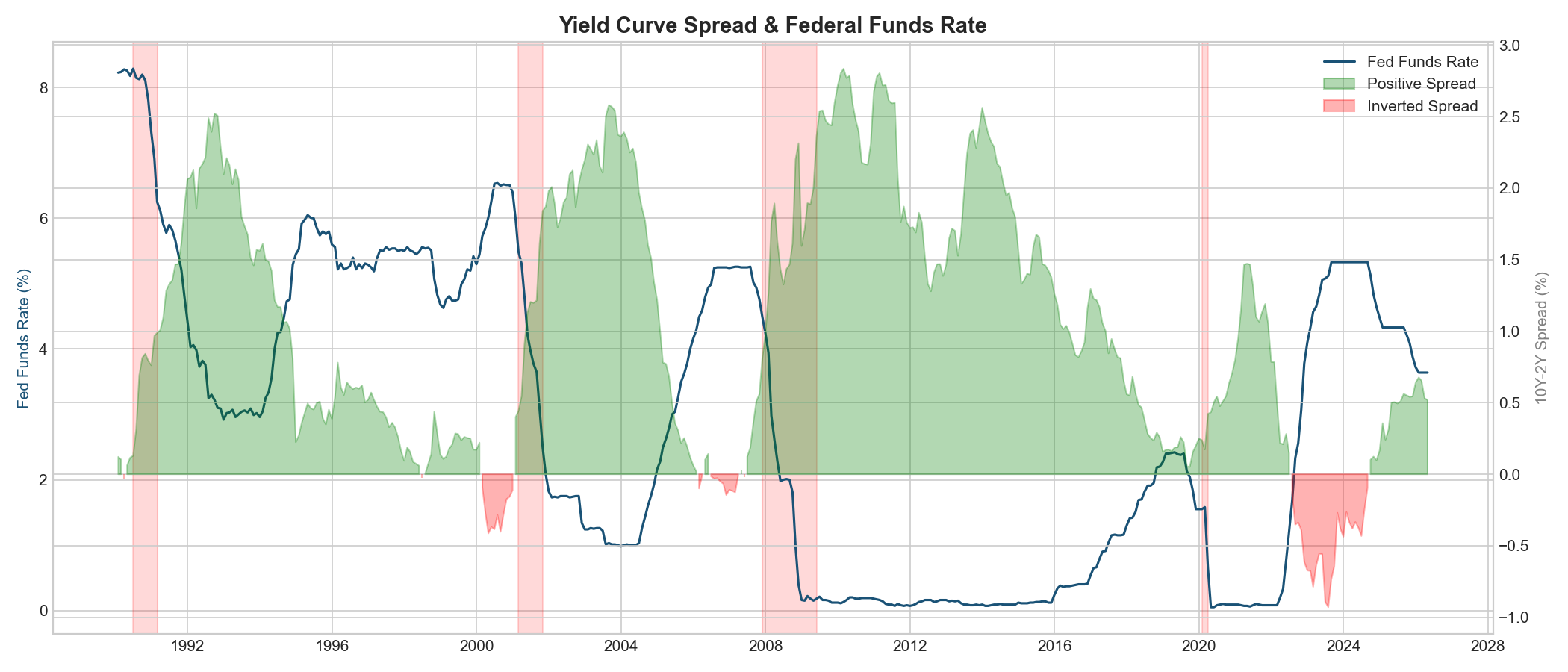
- Collects data from 10 FRED macro series (CPI, PCE, unemployment, GDP, yield curve spread, M2 money supply, nonfarm payrolls, manufacturing employment, housing starts, disposable income) plus S&P 500 data from Alpha Vantage — spanning 1990 to present
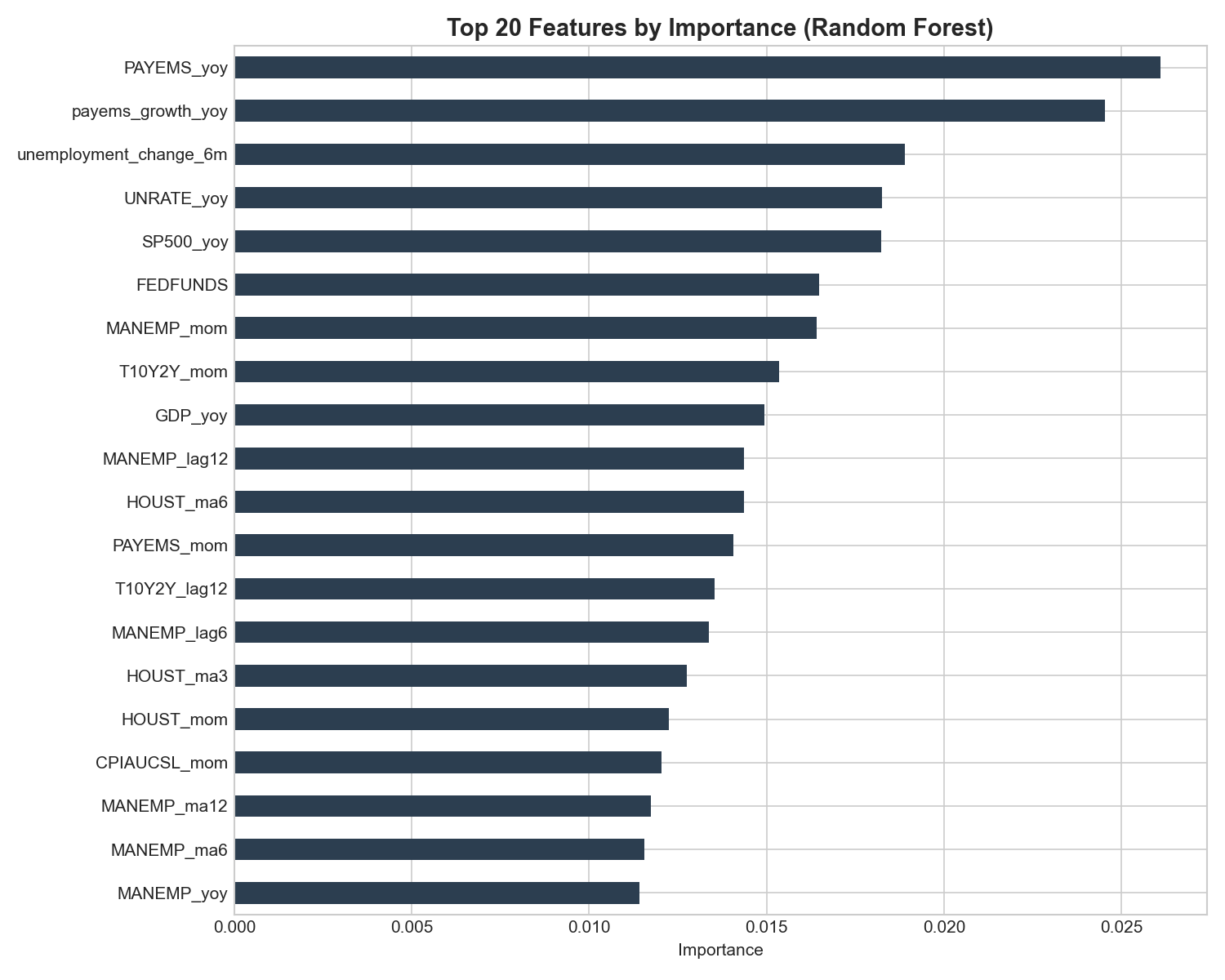
- Engineers 122 features including multi-period lags (1/3/6/12 months), moving averages (3/6/12M), rate-of-change momentum, and derived indicators like the inflation gap (CPI YoY% - 2% target) and yield curve slope
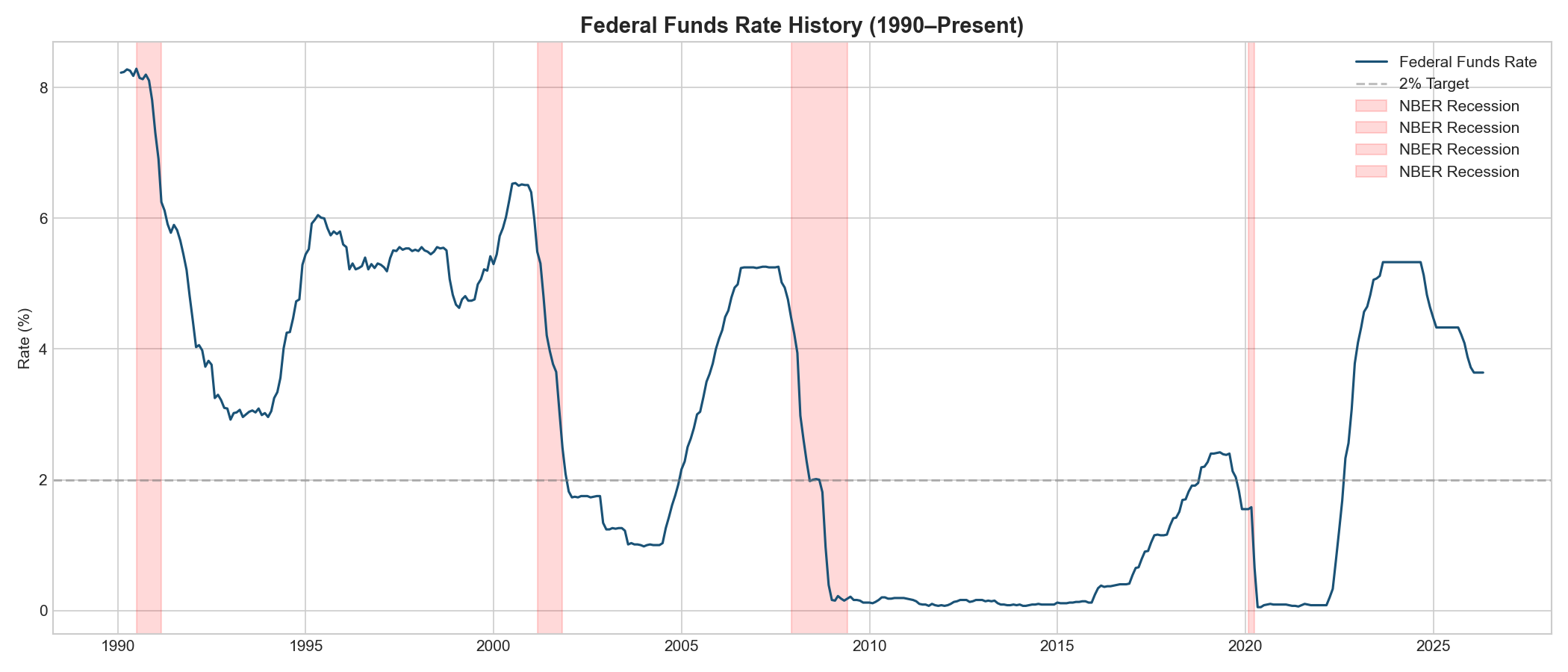
- Trains a Random Forest classifier on 1990-2019 data (348 monthly observations) and tests on 2020-2026 (76 observations): a true out-of-sample test spanning COVID, zero-rate policy, and the fastest tightening cycle in 40 years
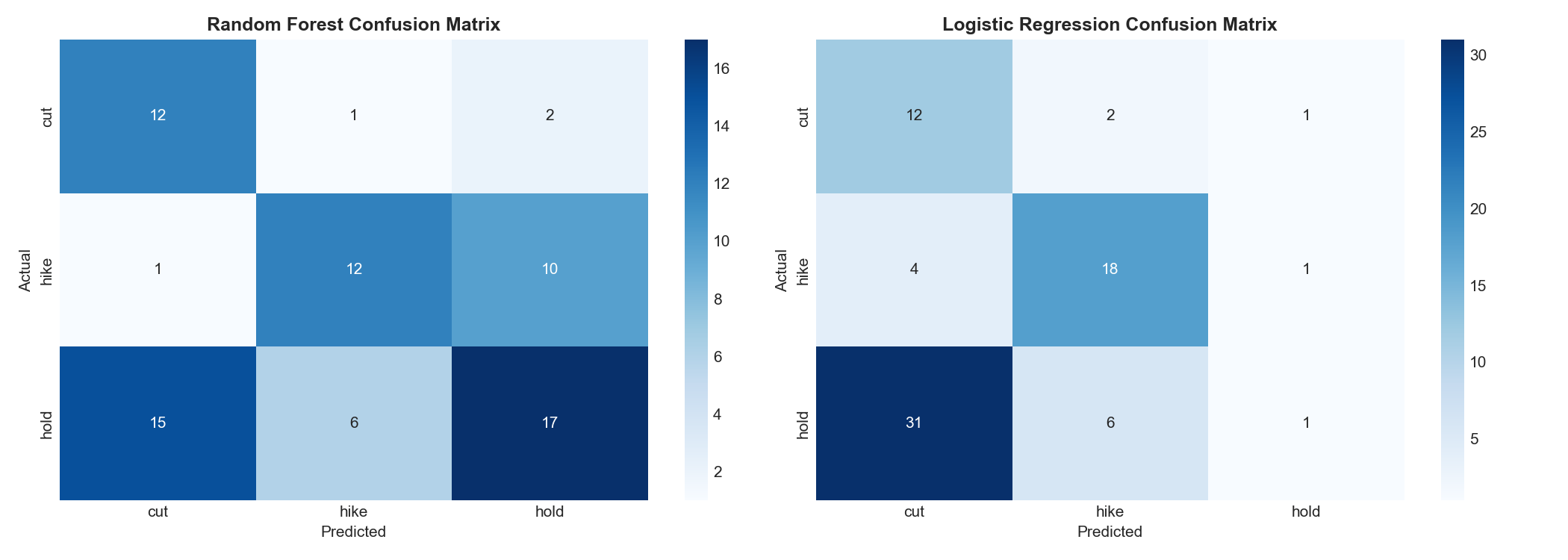
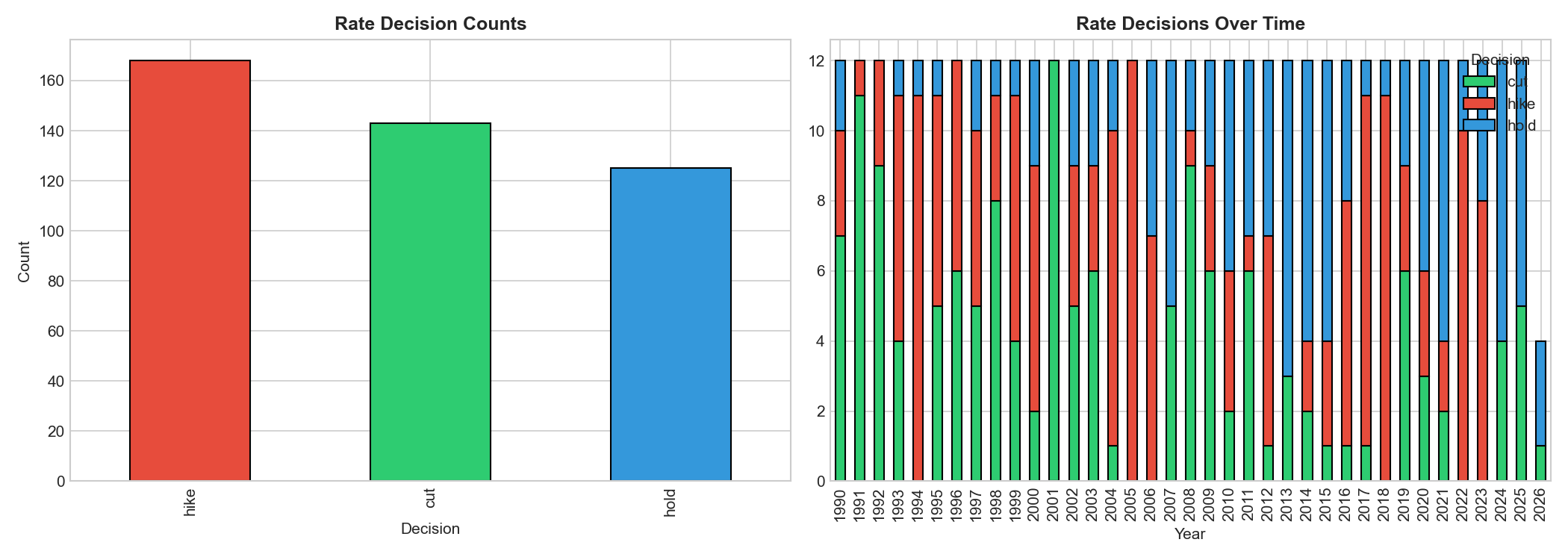
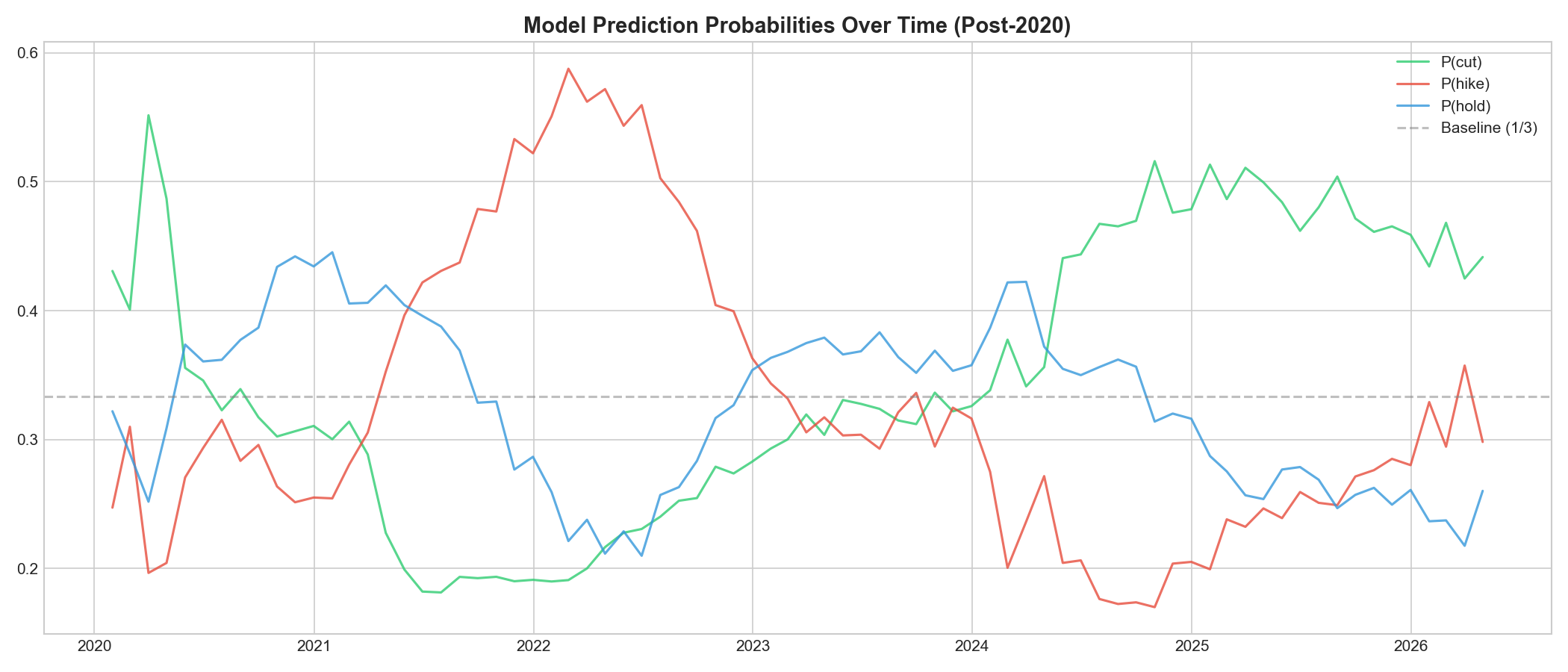
- Achieves 54% accuracy on 3-class prediction (hike/cut/hold) vs a 33% random baseline, with particularly strong recall on rate cuts (80%)
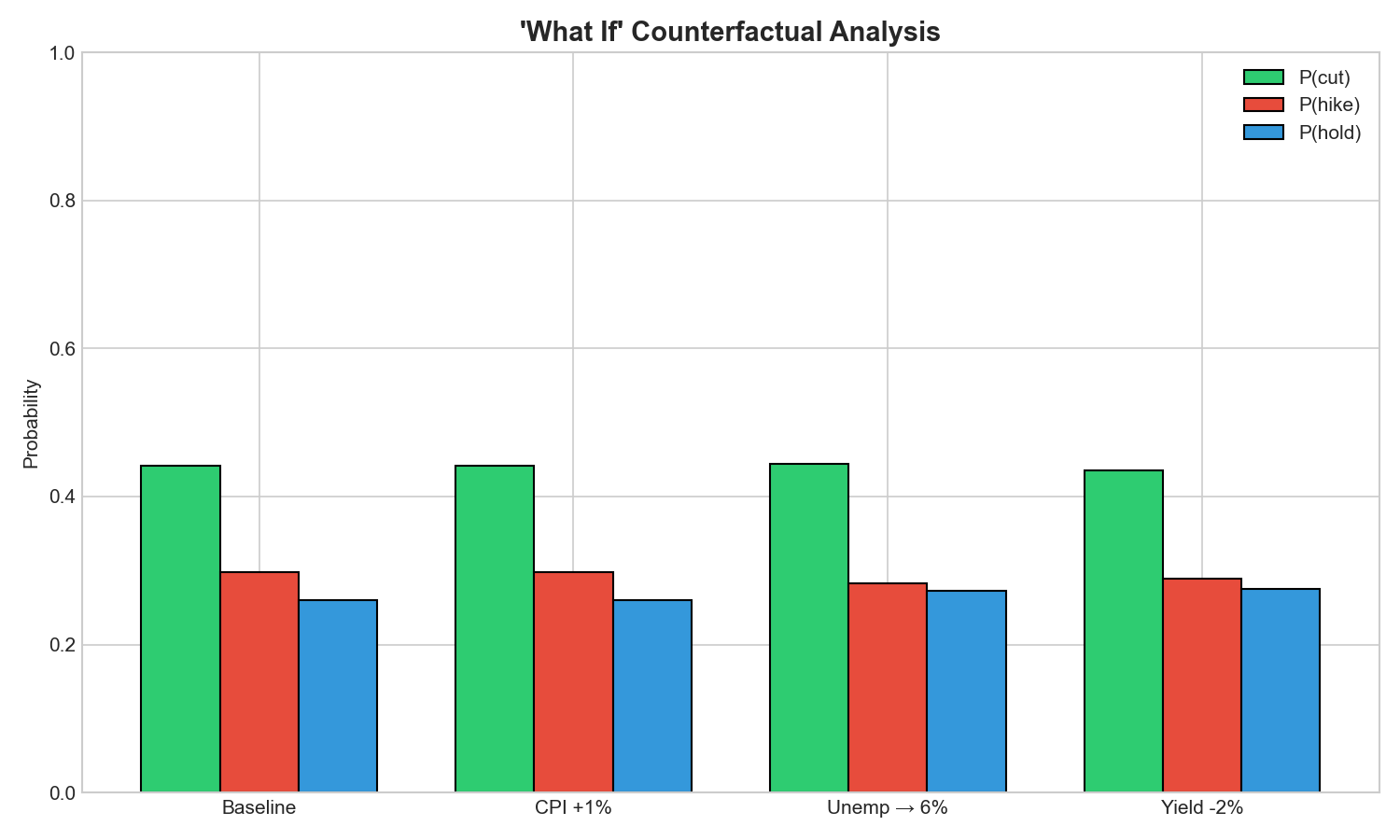
- Provides interactive what-if analysis: see how the model's prediction changes when you shock CPI +2%, push unemployment to 6%, or deepen the yield curve inversion
The deployed app includes 4 tabs: Data & EDA with publication-quality visualizations, Model Results with confusion matrices and feature importance rankings, What-If counterfactual scenarios, and Insights explaining the findings.
How we built it
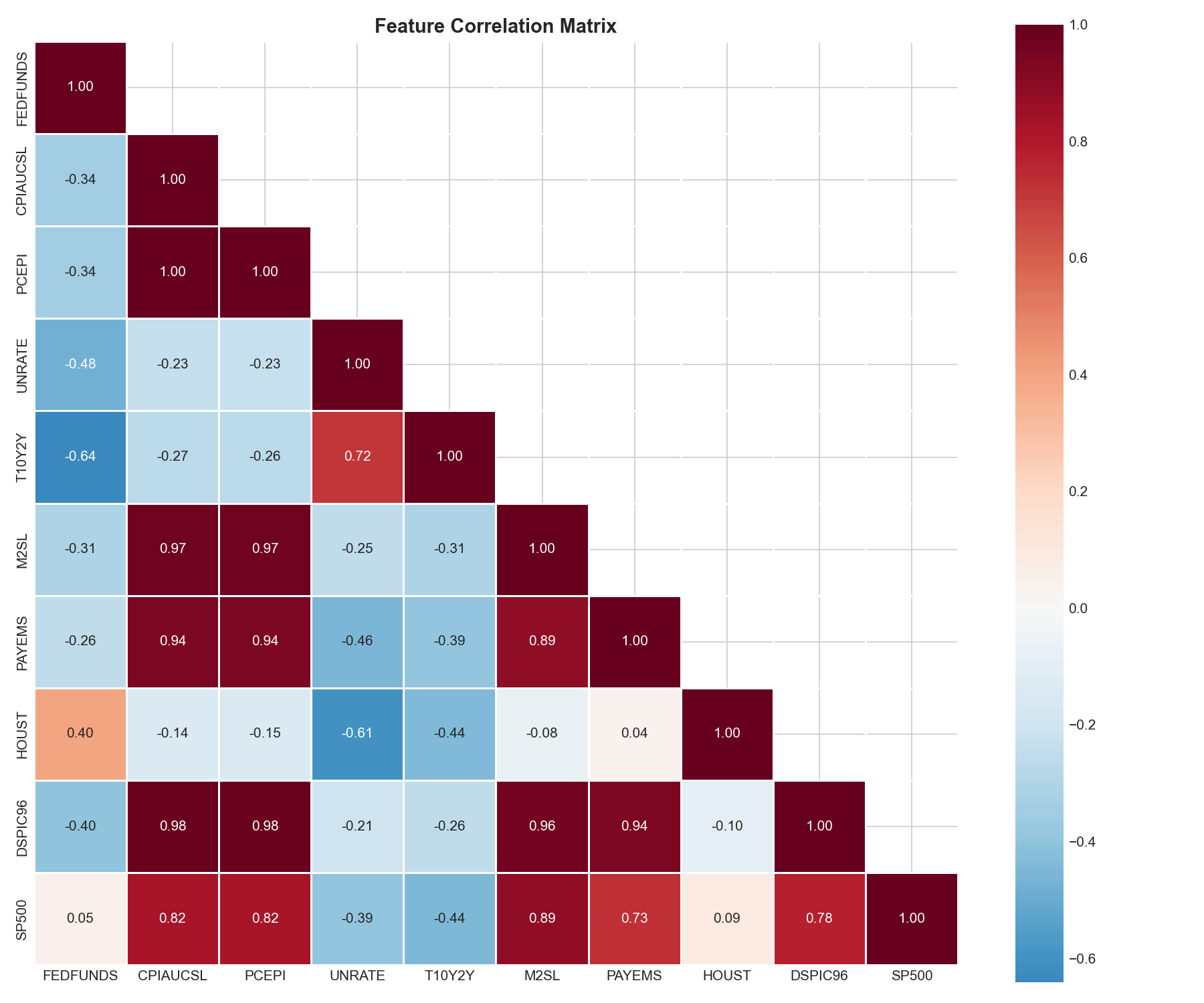
• Data layer: FRED API for 10 macro series, Alpha Vantage API for S&P 500 monthly data, all monthly frequency from 1990-present • Feature engineering: 122 features built from raw indicators viz. lags, moving averages, momentum (MoM and YoY), and derived indicators (inflation gap, yield curve slope, unemployment acceleration, S&P volatility) • Modeling: scikit-learn Random Forest (200 trees, max depth 15, balanced class weights) trained pre-2020, tested post-2020. Logistic Regression baseline for comparison. • Visualization: 10 publication-quality plots viz. Fed funds timeline with NBER recession shading, correlation heatmaps, decision distributions, yield curve analysis, confusion matrices, feature importance rankings • Deployment: Streamlit app deployed on Zerve at fed-shock-predictor.hub.zerve.cloud with interactive what-if analysis • Full pipeline: From raw API data to trained model to interactive app, all in one reproducible notebook
Challenges we ran into
- FRED API intermittently returning 500 errors; built robust retry logic with fallback to PCEPI when CPIAUCSL fails, ensuring the pipeline runs reliably
- GDP is quarterly, everything else is monthly; handled via forward-fill/backward-fill after resampling all series to monthly frequency
- Severe class imbalance post-2020: 38 "hold" vs 23 "hike" vs 15 "cut", used balanced class weights to prevent the model from defaulting to the majority class
- Monaco editor clipboard restrictions: Zerve's browser-based editor blocks programmatic clipboard access, requiring manual code paste workflows
- Credit management on Zerve: The AI agent burned 147+ free-tier credits on web searches without generating code; had to switch to direct Python block approach
- Getting 54% on a 3-class problem over a period that includes two black swan events (COVID, 2022 inflation shock) is actually meaningful: the model is genuinely extracting signal from noise
Accomplishments that we're proud of
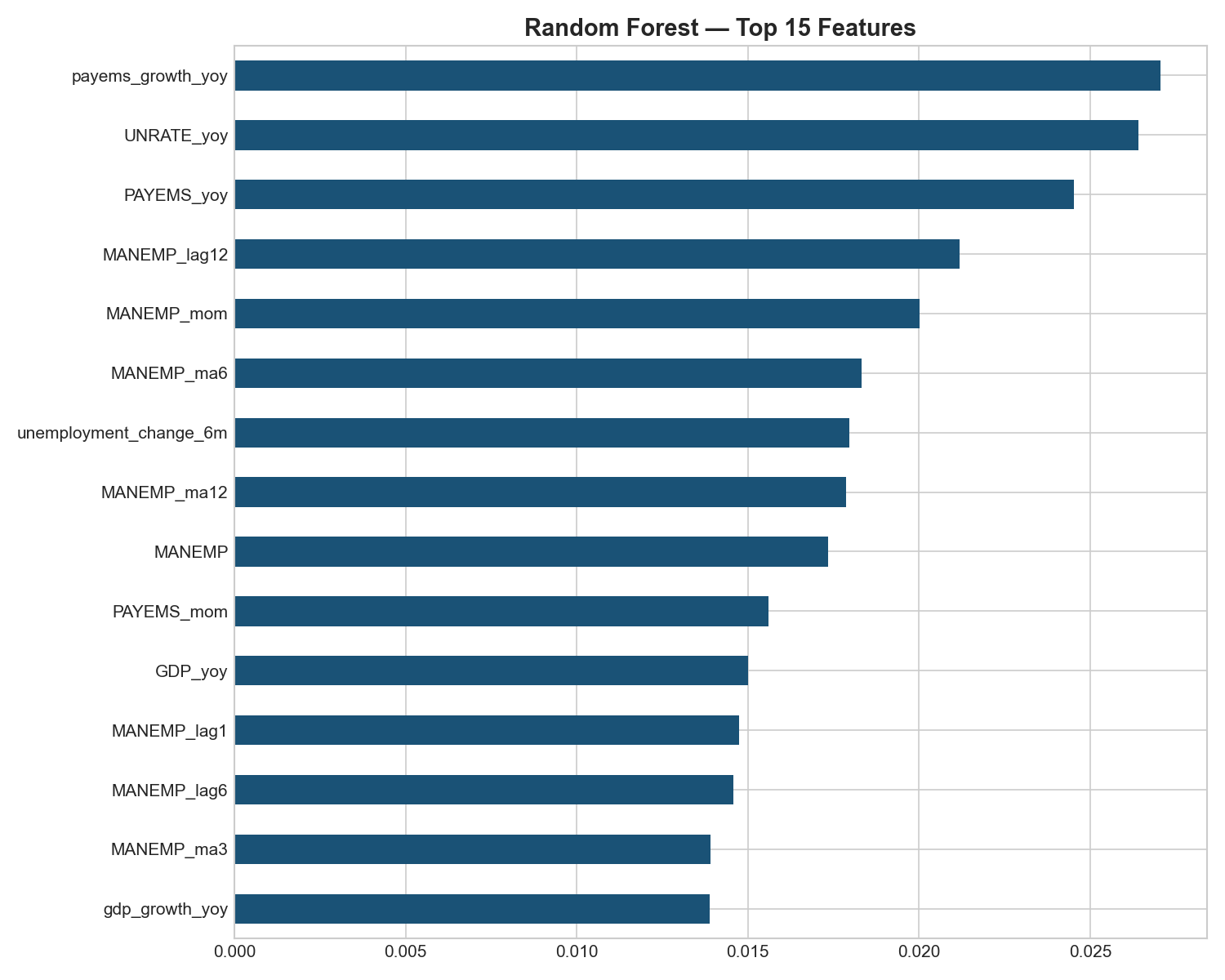
• Building a complete end-to-end ML pipeline (data collection → feature engineering → training → evaluation → deployment) that runs in under 30 seconds • Achieving 54% accuracy on post-2020 data, a period that breaks most macro models, with strong cut-prediction recall (80%) • Identifying that labor market signals (payroll growth, unemployment changes, manufacturing employment) are more predictive than inflation alone: this aligns with Fed Chair Powell's repeated emphasis on "maximum employment" • Creating an interactive what-if tool that makes macroeconomics tangible, you can literally "break the economy" and see what the model thinks the Fed would do • Deploying a working, public Streamlit app that anyone can explore
What we learned
- The Fed is more predictable than people think: 54% accuracy on 3-class prediction with public data is meaningful, especially over a crisis period
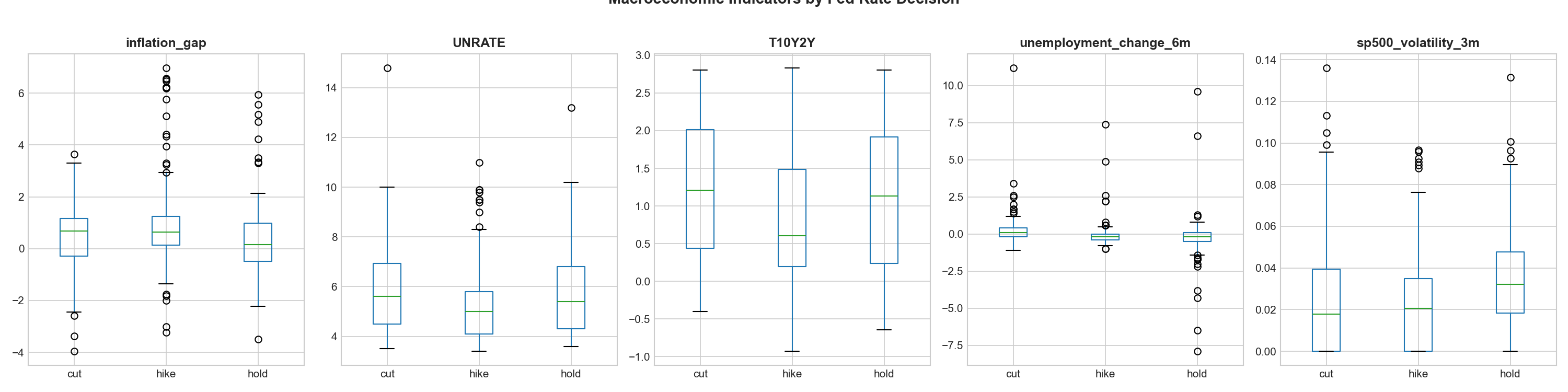
- The Fed's reaction function is asymmetric, cuts are highly predictable (crisis playbook), hikes show strong precision, but "hold" decisions depend on subtle data nuances that are hardest to capture
- Labor data > inflation data: Payroll growth and unemployment changes dominate feature importance, suggesting the Fed watches jobs more closely than CPI
- Inflation alone isn't enough: The model needs labor market confirmation to predict hikes; high inflation with strong employment is what triggers tightening
- Feature engineering matters more than model selection: The engineered features (lags, moving averages, derived indicators) drive most of the predictive power, not the Random Forest itself
What's next for Fed Policy Shock Predictor
• Add walk-forward cross-validation across multiple Fed regimes (pre-2008, 2008-2019, post-2020) for more robust evaluation • Integrate Fed funds futures and CME FedWatch data for a model-vs-market comparison • Add a real-time dashboard that pulls fresh data before each FOMC meeting and publishes a prediction • Experiment with XGBoost and ensemble methods to push accuracy higher • Add natural language features from FOMC statement sentiment analysis • Explore whether the model can predict the magnitude of rate changes, not just the direction
Built With
- alpha-vantage-api
- fred-api
- matplotlib
- numpy
- pandas
- python
- scikit-learn
- seaborn
- streamlit
- zerve

Log in or sign up for Devpost to join the conversation.