-
-
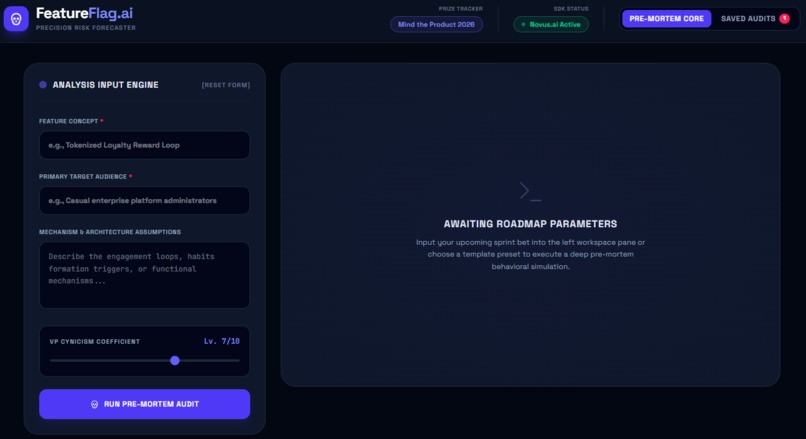
Feature Flag home page
Inspiration
We realized that Product Managers are the most biased people in the room. We fall in love with our own features. We spend weeks writing PRDs and mobilizing engineering teams for ideas that haven't been stress-tested. The result? We ship features that nobody uses. We needed a "Chief Skeptic Officer"; someone to brutally roast our ideas before we write a single line of code. But hiring a consultant takes weeks. We wanted one that runs in milliseconds.
What it does
FeatureFlag.ai is an instant "Pre-Mortem" generator for Product Teams. The Input: A PM types in a raw feature idea (e.g., "Add social stories to our banking app"). The Roast: Our AI Product VP (powered by Groq + Llama 3.3 70B versatile) instantly analyzes the feature for market fit, technical debt, and user value. The Output: It generates a Failure Risk Score (0-100) and a bulleted list of "Why This Will Fail" so you can fix the holes in your logic before sprint planning.
How we built it
We optimized for speed; both in development and user experience. Frontend: We used React + Vite with Tailwind CSS to build a clean, interface that looks professional without wasting time on custom assets. The Brain: We leveraged the Groq SDK to run Llama-3.3-70b-versatile. We chose Groq specifically because a "conversation" with a stakeholder needs to feel instant; waiting 10 seconds for a response breaks the flow. Deployment: Shipped continuously via Vercel for zero-downtime updates. Analytics: Integrated Novus.ai concepts to track product engagement signals.
Challenges we ran into
The "Model Death" Crisis. Mid-hackathon, our core AI model (llama3-70b-8192) was suddenly decommissioned by the provider! Our entire app started throwing 400 Bad Request errors. We had to debug the live server logs, identify the deprecation notice, and hot-swap our infrastructure to the newer llama-3.3-70b-versatile model without breaking the frontend state. It was a real-world lesson in managing AI dependencies.
Accomplishments that we're proud of
Sub-Second Latency: The "Pre-Mortem" feels like a real-time chat, not a loading screen. Resilience: We successfully migrated models in production under pressure. The "Shipped" Mentality: We resisted the urge to build complex user auth or save states and focused entirely on the core value loop: Input -> Roast -> Insight.
What we learned
Dependency Management: Always check your AI provider's deprecation schedule! Prompt Engineering: Getting the AI to be "critically helpful" rather than "rudely toxic" required fine-tuning the system prompt to act like a senior leader, not a troll.
What's next for FeatureFlag.ai
Jira/Linear Integration: Automatically scanning new tickets and posting a Risk Score comment on them. Multi-Persona Mode: Switching the AI from "Product VP" to "Overworked Lead Engineer" or "Confused User" to get different angles of feedback. Saved Reports: Allowing teams to look back at their "Pre-Mortem" history to see if they avoided the risks we predicted.
Built With
- groq
- node.js
- react
- tailwind-css
- typescript
- vercel
- vite

Log in or sign up for Devpost to join the conversation.