
Inspiration
In today's modern day, misinformation spreads faster than ever. This makes it difficult for people to distinguish between credible news and fake news ("fausses nouvelles" in French). We were inspired to create Fausses Nouvelles to empower users with a tool that helps them critically evaluate the news they consume. We combined AI-powered fake news detection (with our custom fausses-model) along with NLP-based corroboration in order to provide users with a reliable way to assess the credibility of news articles in real time. As students, we gained inspiration from an English teacher at my school, named Ms. Austin, who is determined to read more nonfiction such as news sources to attain valuable real-life information. However, her achieving this goal is hindered by the presence of vast amounts of fake news in todays' world. She is frustrated with reading a news source and then it drastically affecting her political views. This was our main inspiration for this project.
What it does
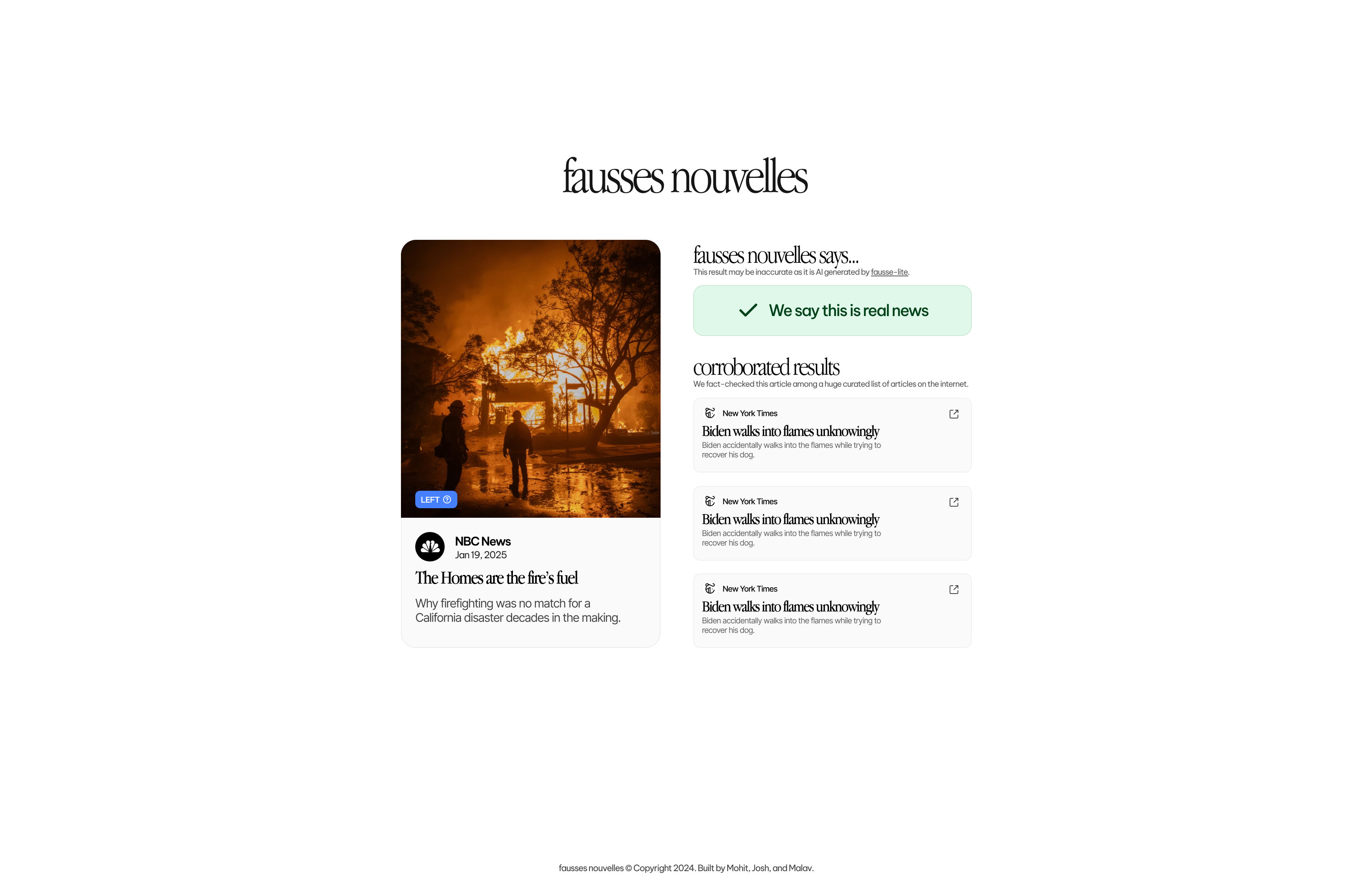
Fausses Nouvelles is a browser extension (for Chrome) that detects when you're on a news website and provides a fake news meter to evaluate the article's credibility. The extension identifies when you're on a news site, extracts the article's content, and then sends the text to the backend for analysis. The backend uses a custom trained AI model to detect whether the article is likely to be fake news and then compares it with other sources to determine its consistency. These results, including a fake news likelihood score, and a list of similar articles (through a very specific, technical, and difficult process, explained in the "How we built it" section) are displayed in the extension's interface, which helps make users make informed decisions about the news they read.
How we built it
The project is built using a combination of modern tech and AI tools. The frontend is composed of a browser extension that is built with React. It detects when the user is on a news site, then extracts the article text, and then sends the text to the backend for analysis. The challenge here is we only want to include whatever is actually part of the article, not things like the ad information, the navbar, etc. The backend is fully written in C# using ASP.NET Core, a highly performant framework for building REST APIs (which is what we used it for). We then ran this on Oracle Cloud Infrastructure (OCI) where we rented dedicated hardware so we can ensure scalability and reliability. This allows us to handle multiple requests simultaneously whilst also maintaining low latency.
The backend performs many important tasks. First it uses NLP techniques to preprocess the article text. This involves tokenizing the text into individual words or phrases, removing stopwords (e.g., "the," "and"), and normalizing the text by converting it to lowercase and stripping punctuation. The tokenized text is then passed through an entity scanning pipeline, which identifies and extracts key entities such as people, organizations, and locations. This is achieved through a combination of rule-based matching and trained NLP models fine-tuned for entity recognition. These entities are then used to query NewsAPI for similar articles from credible sources.
The backend also includes a custom trained AI model for fake news detection. We trained this model on Cohere's GPU-powered platform on a dataset of around 150,000 news articles from various sources. The dataset included reliable sources like Reuters and also unreliable sources like The Onion. The NLP pipeline for training involved these steps: preprocessing the text data by cleaning and tokenizing it, feature extraction using TF-IDF and word embeddings, and then training a transformer-based model fine-tuned for fake news detection. The model was evaluated on a separate test dataset to ensure high accuracy and precision.
Once the backend analyzes the article, it compares the original article with a set of retrieved articles using cosine similarity and sentiment analysis. The cosine similarity algorithm is a mathematical technique used to measure the similarity between the two orders in an inner product space. In our case, the vectors are text embeddings generated by Cohere's R+ infrastructure. The algorithm calculates the cosine of the angle between the two vectors, which represents their similarity. Mathematically, cosine similarity is defined as:
Challenges we ran into
Building Fausses Nouvelles came with its fair share of challenges, particularly in the NLP and algorithmic aspects of the project. Extracting clean and relevant text from news websites with varying structures was a significant hurdle, which we overcame using Readability.js. However, preprocessing the text for NLP tasks introduced additional complexities. For example, tokenization required handling edge cases such as hyphenated words, abbreviations, and multi-language support. We implemented a rule-based tokenizer combined with a pre-trained tokenizer from Cohere to ensure accurate and consistent results.
Another major challenge was entity extraction. While pre-trained models like Cohere’s NER models are highly accurate, they struggled with domain-specific entities (e.g., lesser-known organizations or niche topics). To address this, we fine-tuned the NER model on a custom dataset of news articles, which improved its performance but introduced additional computational overhead. We also had to balance precision and recall during entity extraction, as overly aggressive entity matching led to false positives, while conservative matching missed key entities.
The cosine similarity algorithm, while mathematically straightforward, posed challenges in implementation. Calculating cosine similarity for high-dimensional embeddings (e.g., 768-dimensional vectors from Cohere’s models) required optimizing for both speed and memory usage. We implemented batch processing and vectorized operations to reduce latency, but this introduced challenges in handling large datasets. For example, comparing a single article against 100 retrieved articles required computing 100 cosine similarity scores in real-time, which strained our backend infrastructure. To mitigate this, we leveraged Cohere’s R+ infrastructure, which uses distributed computing and GPU acceleration to perform these calculations efficiently.
Training the custom fake news detection model was another significant challenge. The dataset of 150,000 articles required extensive preprocessing, including text cleaning, stopword removal, and label balancing to ensure the model wasn’t biased toward either class (real or fake). We experimented with multiple architectures, including BERT, RoBERTa, and DistilBERT, before settling on a fine-tuned transformer model. Training this model on Cohere’s GPU infrastructure was computationally expensive, but the serverless architecture allowed us to scale resources dynamically, reducing training time from weeks to days.
Finally, integrating all these components into a cohesive system required careful pipeline optimization. For example, the entity extraction and cosine similarity steps had to be executed sequentially, but we parallelized independent tasks (e.g., preprocessing and embedding generation) to improve throughput. We also implemented caching for frequently accessed articles to reduce redundant computations and improve response times.
Accomplishments that we're proud of
We’re proud of several key accomplishments in this project. First, we successfully trained a high-accuracy fake news detection model using a large, diverse dataset. This model was seamlessly integrated into the backend, enabling real-time analysis of news articles. We also built a user-friendly browser extension that provides real-time fake news detection and article comparison, complete with an intuitive and visually appealing UI. The backend was designed to be scalable and robust, capable of handling multiple requests efficiently. Finally, the entire system—from the frontend to the backend to the AI model—was integrated into a cohesive product that delivers on its promise of helping users identify fake news.
What we learned
Throughout this project, we gained valuable experience in AI and NLP, particularly in training transformer-based models and building NLP pipelines. We learned how to curate and preprocess large datasets for machine learning tasks, as well as how to leverage GPU-accelerated training to handle computationally intensive workloads. On the development side, we gained hands-on experience building browser extensions and integrating them with backend APIs. Perhaps most importantly, we improved our ability to work as a team, dividing tasks effectively and integrating individual contributions into a final product.
What's next for Fausses Nouvelles
Looking ahead, we have several exciting plans for Fausses Nouvelles. First, we aim to expand the range of news sources by integrating additional news APIs, which will improve the breadth and depth of article comparisons. We also plan to fine-tune the AI model on additional datasets to further improve its accuracy. Another key feature we’re exploring is political bias detection, which would show users whether a news source leans left, right, or center. Additionally, we’re considering developing a mobile version of Fausses Nouvelles for on-the-go news analysis. Finally, we plan to collect user feedback to continuously improve the extension’s functionality and user experience.
Built With
- ai
- cohere
- cosine
- gpu
- ml
- model
- training




Log in or sign up for Devpost to join the conversation.