
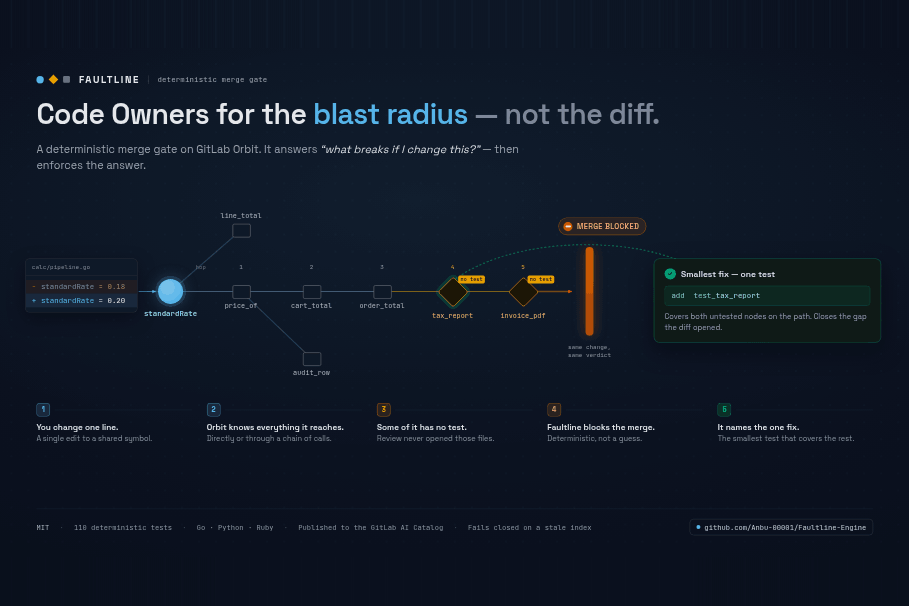
The change was one line. A tax rate went from 0.18 to 0.20, inside a helper nobody thinks about. Every test passed. The pipeline went green. It merged on a Friday.
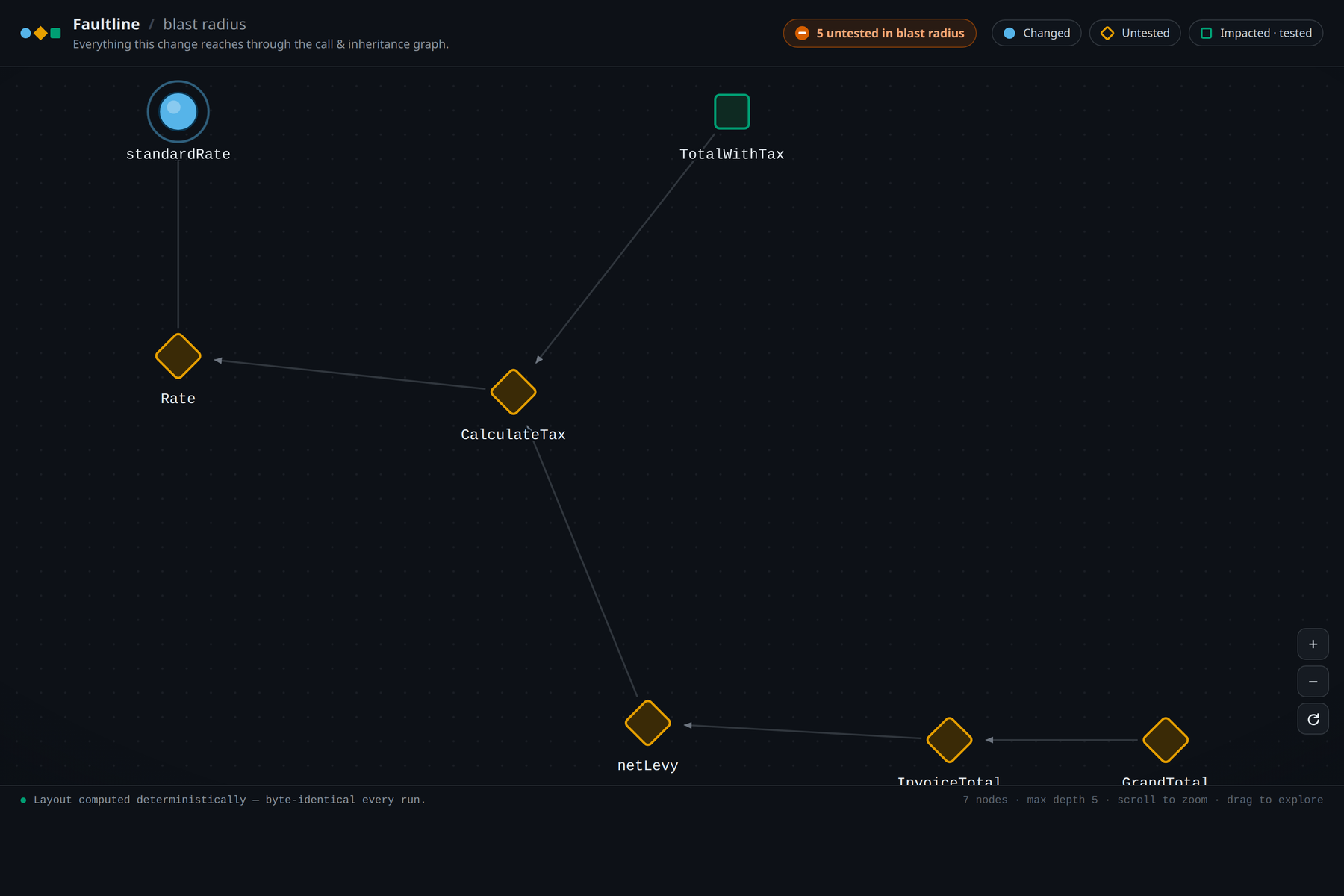
The code it broke sat five calls away, in a file nobody on the review had opened in months. That file had no test, so nothing turned red. The invoices did that later.
Review shows you the diff. It does not show you the damage. Faultline exists to close that gap.

Try it on three real merge requests, no setup:
- A one-line tax change that fails the pipeline — untested impact five calls deep, and the one test that closes it.
- One verdict across Go, Python, and Ruby — a shared rate bumped in three languages, one blast radius.
- Faultline gating its own repository — the same one-line
include:we ship to everyone else.
MIT licensed. 110 deterministic tests. The gate fired on 21 of 32 real regressions from BugsInPy.
What it does
GitLab built Orbit, its code knowledge graph, to answer one question: "What breaks if I change this service?" — from indexed facts, not inference. Faultline takes that answer the last mile.
When you open a merge request, it asks Orbit for the call graph and computes every function that depends on what you touched: direct callers, their callers, all the way down. Then it intersects that blast radius with the code that has no test. If untested code sits in the path, it blocks the merge and tells you, in plain language, the single smallest test that would cover all of it.
Not a risk score stapled to a comment. A decision, with the fix attached.
We didn't want to build another visualizer
The last GitLab AI Hackathon gave its Anthropic Grand Prize to GraphDev, a project that let you, in the judges' own words, "see the full impact of a change before you make it." They loved the demo. So did we.
But seeing the blast radius doesn't stop the bad merge at 4:58 on a Friday. Someone still has to notice the picture, read it right, and decide. Faultline is that idea with one verb changed: from see to enforce. The graph stops being a thing you look at and becomes the thing that holds the line.
What actually makes it different
Two claims, and we'll be precise about them, because this panel will check.
It prescribes a provably-minimal fix. Finding untested impacted code is the easy half. The hard half is what do I do about it, and "go write tests for all six functions" is the answer nobody follows. So Faultline models the untested paths as a graph and solves for the smallest set of test points that covers every one of them: a minimum vertex cut, computed with max-flow, checked on every build against a brute-force oracle so we have to trust our own math. It also runs a Shapley attribution to say which of your changed symbols actually owns the risk. The output isn't "here is the blast radius." It's "add one test at parse_tokens and all five untested paths are covered."
We went looking for prior art on this and didn't find a shipping tool that does minimal-cut test prescription on a code graph. This is the part we're proudest of.
It gates the untested slice, not the whole diff. Every other blast-radius tool we found stops at a report: N callers, risk HIGH, posted as a comment. None of them look at your tests. A comment can afford to be vague. A gate that blocks your merge cannot, so Faultline only blocks on the one thing it can prove — impacted code with no coverage — and stays quiet about the rest.
The rest of the kit earns its place too. It's polyglot: one verdict across Go, Python, and Ruby, on real Cobertura and lcov data. It runs in CI on Orbit's free graph API, with no model anywhere in the decision. And it fails closed.
How we built it
Two languages, deterministic end to end.
A Rust engine does the graph math as pure functions: the transitive closure, the minimum cut, the coverage ranking, the Shapley shares. A Go agent talks to Orbit, normalizes the graph, runs the engine, works out coverage, and writes the verdict. There is no language model in the path that decides whether your merge passes. The same change produces the same verdict every time, which is exactly what Orbit promises about itself: "the same query returns the same answer every time."
The verdict leads in plain words, with the graph theory folded into an expandable section for anyone who wants to check the receipts. It ships a colorblind-safe interactive graph and a native GitLab Code Quality report, so every untested function shows up in the merge request on the free tier. When it blocks, it hands the minimal test set to a GitLab Duo flow that opens a draft test-MR, and a human approves it. The deterministic part makes the call. The AI does the typing.
Adoption is one line of .gitlab-ci.yml, with a companion agent published and version-pinned in the GitLab AI Catalog. We wanted it to feel like something you would install, not a demo you would clap for.
The hard parts
Orbit hands you one hop; a gate needs all of them. A single Orbit traversal stops at a depth bound. Ask for four hops and the live API answers with a compile_error. That bound is right for an interactive query and wrong for a gate, which needs the complete set. So we compose the full transitive closure offline in CI, over CALLS and EXTENDS, where latency isn't the constraint. That is how the demo reaches code five calls deep that no single query returns.
We almost shipped math theater. We designed a "cost-aware weighted cut" that sounded clever. Before building it, we ran 33,652 random trials to check whether it changed any answer in our formulation. It didn't. It was a guaranteed no-op. We cut it. Complexity you can't justify is just risk in a nicer coat.
Saying "I don't know" on purpose. If Orbit's index is stale or half-built, the honest answer isn't a green check. It's a refusal. Faultline detects a degraded index and returns "can't vouch" instead of a false pass, because a confidently wrong gate is worse than no gate. That mirrors a value GitLab's own indexer already holds: don't act on data you can't trust.
Does it actually catch bugs
We ran the exact engine binary against real, reproduced regressions from BugsInPy, a dataset of 501 real Python bugs. Treating each fix as a merge request: on 21 of 32 analyzable regressions across tornado and black, the buggy change reaches untested code, so Faultline would have blocked it and named the test. The offline graph comes from a conservative static analyzer rather than Orbit in production, so that number is a floor, not a ceiling.
What we learned
The instinct to add was the enemy. Every feature we were proud of cutting (the weighted cut, the cross-domain graph joins Orbit can't reliably support) made the tool more trustworthy, not less. A gate earns the right to block by being narrow. We ended up defending the boundary as hard as we defended the features.
What's next
Real execution coverage by default, building on the Cobertura and lcov support that's already there. More languages as Orbit indexes them. And a tighter loop with Duo, so the draft test-MR it opens comes back already green.
Built with
GitLab Orbit (knowledge graph API) · Rust · Go · GitLab CI · GitLab Code Quality · GitLab Duo and the AI Catalog · Cobertura and lcov.


Log in or sign up for Devpost to join the conversation.