Inspiration
Every month, finance and internal-audit teams do the same exhausting thing: comb through hundreds of vendor payments by hand, hunting for duplicate invoices, ghost vendors, policy breaches, off-hours payments, and sanctioned payees. It's slow, repetitive, and error-prone — yet the stakes are high, because a missed duplicate or a sanctioned payee is real money and real risk.
This is exactly the kind of work an AI agent should own — but it's also work where you can't just let an AI press the button. A wrong write to a financial ledger isn't a typo you shrug off. So we asked: can an agent do the heavy lifting of a multi-step audit, while a human stays firmly in control of every consequential decision? FaultAuditAI is our answer.
What it does
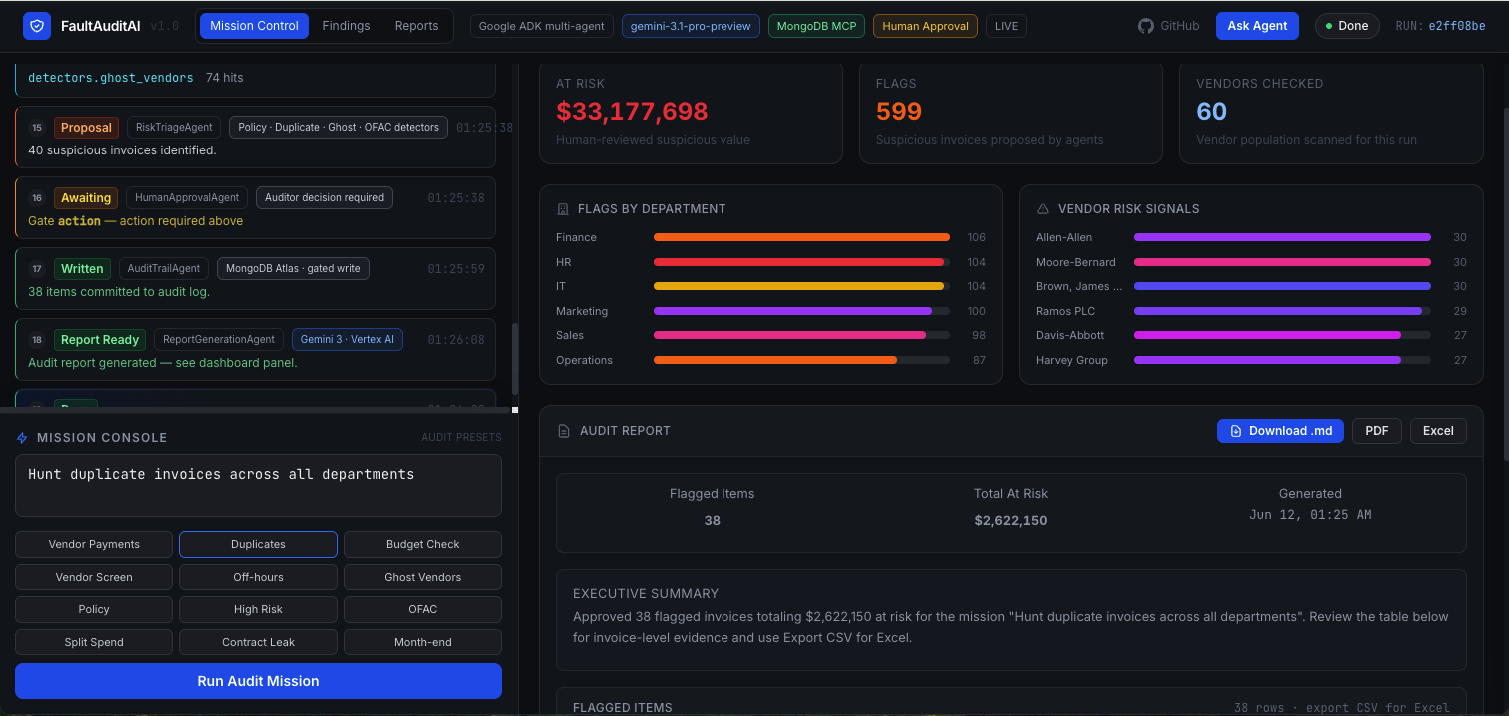
You give it a plain-English mission — "Audit this month's vendor payments for duplicates, suspicious vendors, and sanctions risk." FaultAuditAI then:
- Plans the audit and stops for your approval.
- Investigates the data with specialist agents — semantic vector search, spend aggregation, fraud/policy detectors, and a live OFAC sanctions screen.
- Proposes a flagged list with evidence for each item, and stops again for your approval.
- Writes flags and an audit log — only for the items you approved — and generates a finance-review report.
It moves beyond chat: it manages a live database, calls an external sanctions service, streams its reasoning live, and produces a real artifact — not just an answer.
How we built it
FaultAuditAI is a multi-agent team on Google Vertex AI Agent Builder (the google.adk SDK), reasoning with Gemini 3. A root FaultAuditCoordinatorAgent orchestrates eight specialist LlmAgents — planning, transaction screening, spend analysis, risk triage, human-approval, audit-trail, report generation, and an assistant for follow-up questions.
MongoDB is the agent's evidence engine, not just storage. Transactions, vendors, and policies live in MongoDB Atlas alongside their 768-dimensional gemini-embedding-001 vectors — no separate vector database. The two read agents query Atlas through the official MongoDB MCP server, launched read-only. The agent embeds the mission and runs Atlas Vector Search, which ranks candidates by cosine similarity:
The two human gates are structural, not prompt-based: the write tool (mark_flagged) is an ADK LongRunningFunctionTool that suspends the run until a human decision arrives, relayed by a FastAPI + Server-Sent Events backend that streams every agent step to a two-pane web console. The whole thing ships in Docker and runs a full scripted demo in mock mode with no credentials.
Challenges we ran into
- Parsing MCP output safely. The MongoDB MCP server wraps results in an
<untrusted-user-data>security envelope; we had to extract the JSON payload reliably without trusting injected content. - A nasty async bug. Wrapping MCP calls in
asyncio.wait_forcancelled the MCP client's internal task groups and raised an exception before the result was captured. The fix was to drop the timeout wrapper and guard reliability a different way. - Reliability without faking it. A live demo can't hang. So if the MCP subprocess hiccups, reads fall back to the direct driver; if a Gemini call times out, planning and reporting fall back to concise deterministic text — the run always completes, and we're transparent that these fallbacks exist.
- No usable dataset. No public dataset is simultaneously corporate-grade, fraud-labeled, and commercially licensed, so we generated a synthetic ledger with Faker — ~1,500 invoices across 60 vendors with deliberately injected duplicates, near-duplicates, ghost vendors, policy violations, and off-hours payments — fully reproducible from a fixed seed.
Accomplishments that we're proud of
- Human control that's enforced in code, not prompts. The agent physically cannot write until you approve — guaranteed by the runtime, not by hoping the model behaves.
- A genuine MongoDB MCP integration as the agent's investigation layer — vector search, aggregation, schema inspection, and counts — with a clean read-only reads / gated single write security boundary.
- A real 8-agent ADK team on Gemini 3, deployable to Vertex AI Agent Engine, running live on real Gemini + real Atlas Vector Search.
- It's testable and reproducible: 154 tests on an in-memory MongoDB (no credentials), and a one-command Docker demo.
What we learned
- Human control has to be structural, not polite. Early "always ask before writing" prompt guardrails were unreliable. Moving the gate into a
LongRunningFunctionTool— where the runtime physically pauses — turned approval from probabilistic into deterministic. - MCP makes a clean security boundary. Routing all reads through a read-only MCP server, and funneling the single write through a separate gated tool, gave us least-privilege access by construction.
- Semantic search earns its keep. Vector similarity caught reworded near-duplicates that exact matching and aggregation missed — the single most valuable detector.
- Streaming builds trust. Showing each tool call live, instead of a spinner and a verdict, is what makes a human comfortable approving an agent's findings.
What's next for FaultAuditAI
Connect to real ERP / accounts-payable exports, add scheduled recurring audit missions, and introduce reviewer roles so audit teams can split approval duties — while keeping the human firmly in the loop on every consequential write.
Built With
- agent-development-kit
- atlas-vector-search
- docker
- fastapi
- gemini
- google-cloud
- javascript
- model-context-protocol
- mongodb
- mongodb-atlas
- python
- vertex-ai

Log in or sign up for Devpost to join the conversation.