-
-
1 Query Complete
-
Multi Query Node
Inspiration
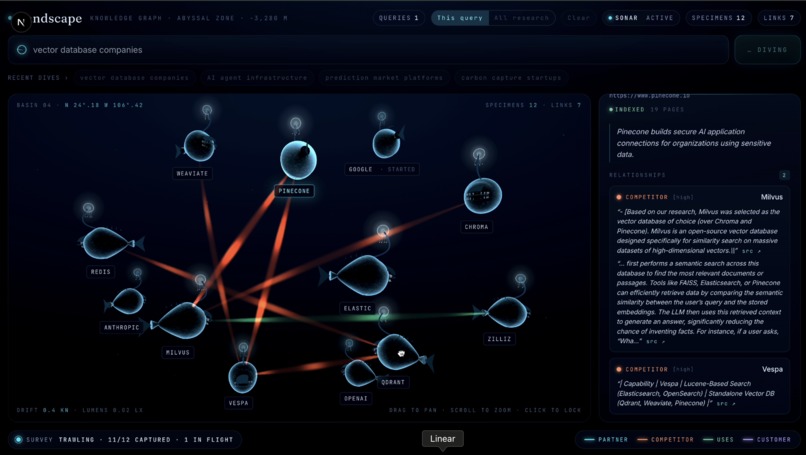
Every researcher - VC's founders, journalists, job seekers build an industry map in their head. That map is always incomplete, out of date and impossible to share. LLM's web search often hallucinate relationships that don't really exist. Sites like Crunchbase is often expensive and can't keep up with new categories. I wanted a research tool that looked like a map instead of a chatbot. With evidence baked into every claim so you can trust what you see and follow it back to its source.
What it does
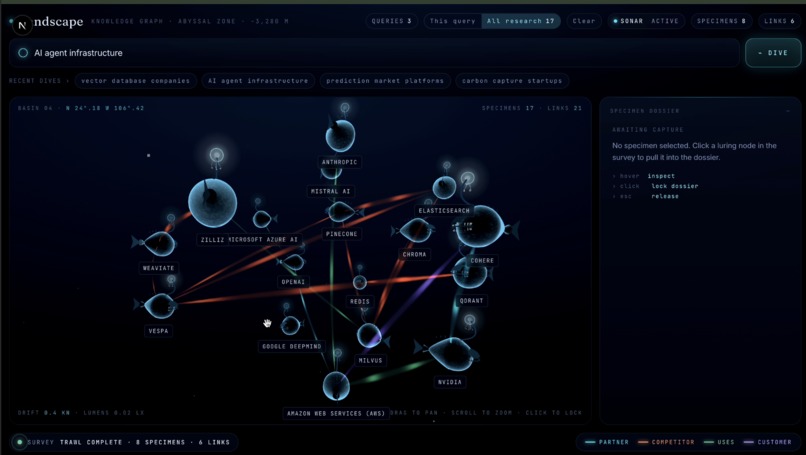
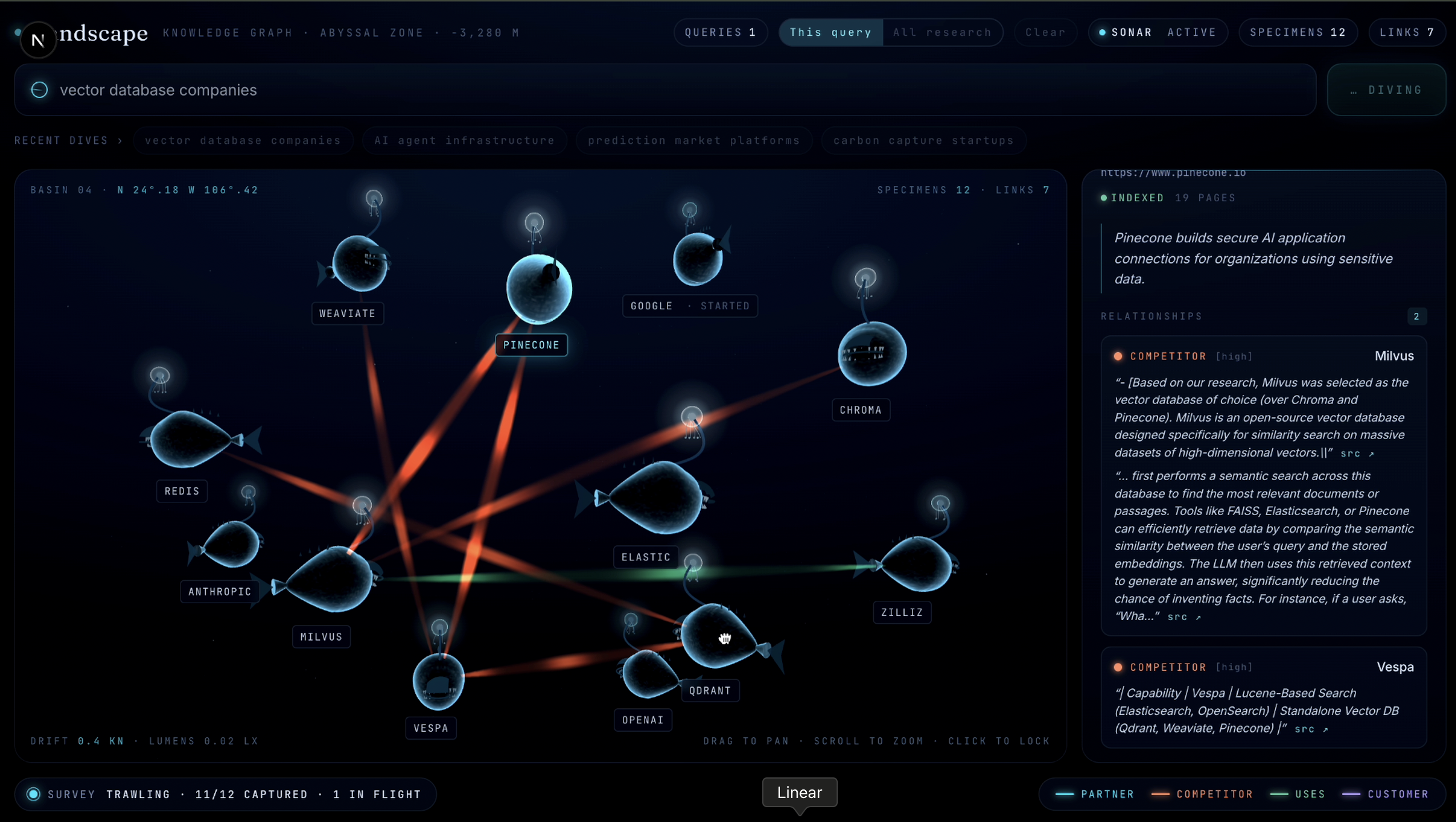
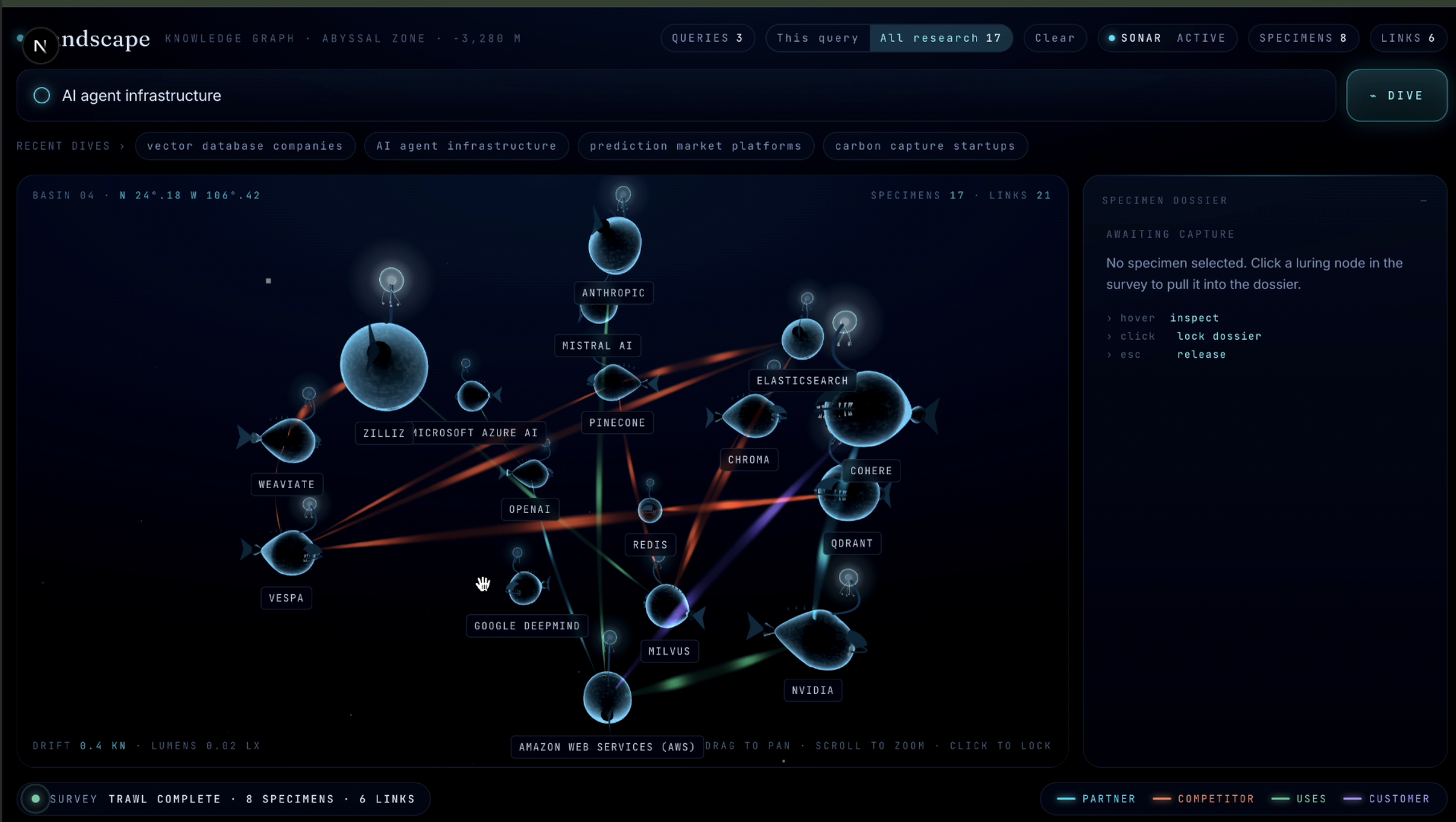
You type a query "AI Agent infrastructure companies", "Vector database companies" It asks Gemini 2.5 flash-lite for around 10 canonical companies that match the query. It indexes each company live using Human Delta's crawler. Homepages, about us, blogs, docs, partner pages etc. Everything relevant to establish what the company does and who it works for. Our application Greps across the indexed corpora using human deltas sandboxed shell to cross reference company pairs. This is engineered to handle false positives like image URLs and code imports. Gemini classifies each relationship and requires a quote pulled from the actual grep output. Before any connection is accepted the quote is validated against the raw corpus. Using server side events it renders the result live each company its own node. Click any node and a side panel slides in with a sentence summary of the company and every relationship cited to its real source URL. Click "Find more like this" and uses the company's corpus, and goes through the pipeline again to populate found companies.
How we built it
Backend: Python on FastAPI with Human Delta's indexing and sandboxed shell endpoints, plus word-boundary grep, image/code-line filters, and exponential backoff retries. A crawl orchestrator runs 4 indexes in parallel and a pair extractor rejects any edge whose evidence quote isn't a literal substring of the grep output. LLM layer: Google Gemini 2.5 Flash-Lite via Vertex AI Express with structured output on every call. Four prompts carry the pipeline - parsing the query into a company list, classifying each relationship with a validated evidence quote, surfacing expansion candidates, and writing a one-sentence company summary capped at 20 words. Storage & streaming: SQLite in WAL mode for the temporal store, tracking crawl versions and the full edge lifecycle - first seen, last confirmed, status - so stale edges flip instead of disappearing silently. The whole pipeline streams to the browser over Server-Sent Events, so every index start, completion, and edge found hits the client in real time. Frontend: Next.js, React, TypeScript, and Tailwind, with the graph rendered in three.js using custom GLSL shaders for the anglerfish bodies and flowing ribbon edges. The chrome is a submarine research HUD - radar-scan query input, pulsing phase status bar, and monospace telemetry readouts drifting over depth fog and marine snow.
Challenges we ran into
-Hallucinated Relationships - the model invents a plausible partnership that doesn't exist anywhere on either company's site. The fix was to require every edge to carry a quote that is a literal substring of the grep output, validated before the edge ever reaches the client - if the quote isn't in the corpus, the edge is rejected. -Evidence resolution - A quote isn't useful without a clickable source, so for every expansion candidate a second grep finds the exact markdown file the quote came from, and the public URL is reconstructed by stripping the sandbox path prefix. One extra round trip per candidate in exchange for every citation being a real link. -crawl latency - Indexing a mid sized company's site through Human Delta can take 30 seconds to 2 minutes, and with 10 companies per query that's a lot of wall clock time if you run serially. Parallelizing 4 at a time pulls the total down to the slowest single site, and an index cache means previously indexed companies are near instant on repeat queries.
Accomplishments that we're proud of
-Every edge has a real source. The substring check makes it structurally impossible for the model to fabricate a quote, so every relationship in the graph points at text you can read on a page you can click. A research tool that lies to you is worse than no tool, and this was the single thing I cared about most.
-Expansion with full provenance. Click a node, pick candidates, and watch the graph grow with tags showing where each new node was discovered - "discovered via this company's partners page" - with no re-extraction on edges that already exist. Every query you run adds to a persistent, queryable knowledge base.
What we learned
Structured output beats prompt tuning. Forcing the model to fill a schema with a validated evidence field did more for reliability than any amount of prompt wording. Give yourself a substring check and you stop worrying about hallucinations entirely. Caching changes what's possible. Indexing is the expensive step - 30 seconds to 2 minutes per company - so a cheap file existence check before re-indexing cuts the time in half. Expansion queries reuse corpora from the original graph, which means the second and third hops cost a fraction of the first and the product actually feels interactive.
What's next for Fathom
Shareable graphs. Snapshot a graph to a URL so you can send an industry map to a friend, embed it in a post, or drop it into a pitch deck. Right now every graph lives in a single session, and the whole point of a map is that you can pass it around. Improve the relationship mapping as well as speed of find more similar companies
Built With
- fastapi
- googlegemini
- humandelta
- nextjs
- python
- react
- sqlite
- tailwind
- typescript



Log in or sign up for Devpost to join the conversation.