
FastCoV19: ML solution for SARS-COVID-2 Blood Test
Objectives
This project is aim to predict confirmed COVID-19 casess based on laboratory result from anual physical exams.
We consider whether it be possible to predict the test result for COVID 19 (either positive or negative) based on the result of blood test?
Data Set
We retrieve the dataset from patients seen at the Hospital Israelita Albert Einstein in São Paulo, Brazil,who perform the COVID 19 test and additional laboratory tests.
This dataset has 109 variables, a Patient ID and one target outcome variable showing the result (positive/negative) of COVID 19.
Data Cleaning
Data cleaning procedures consist of: Making variable names syntactically valid, Replacing column values that should be empty for NA, Convert string categorical values to factors, Convert the variable Urine...pH to integer.
The outcome variable SARS.Cov.2.exam.result is a binary by which we convert such that $SARS.Cov.2.exam.result = 1$ for being positive and $SARS.Cov.2.exam.result = 0$ for being negative with COVID 19.
However, there are too many missing data points (>= 95%); we decided to remove them along with poor sample. But we choose to keep negative samples that have at least 10 variables with data points available.
Predictive Analysis
Model Training
To predict the likelihood that a patient is infected with the COVID 19, we split the dataset randomly into training and testing tests in a train-to-test split ratio of 4/5.
We train a GBM-Gradient Boosting Machine- to produce a prediction model in the form of an ensemble of weak prediction models, typically decision treesmodel using the remaining dataset variables as predictors. By defining a relatively high bag fraction, this introduces randomnesses into the model fit and reduces overfitting.
Model Interpretability
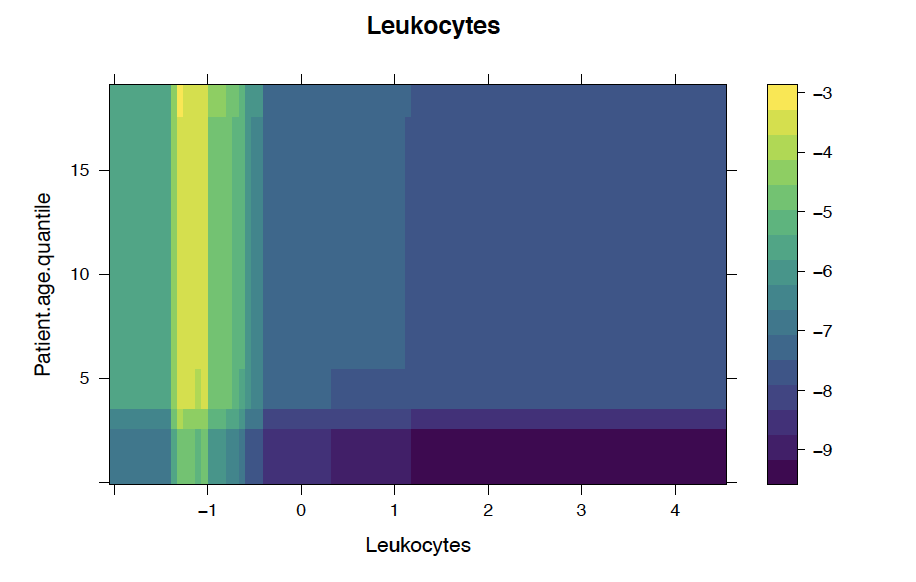
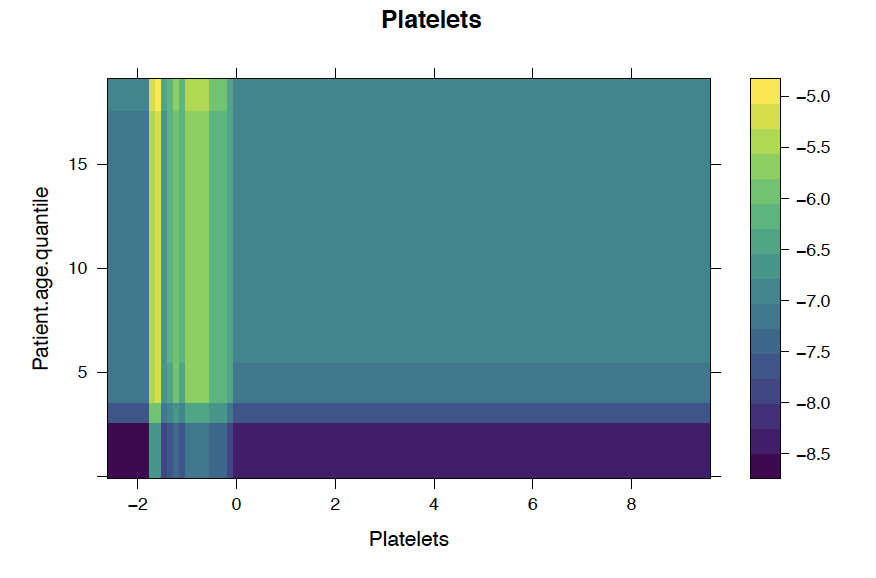
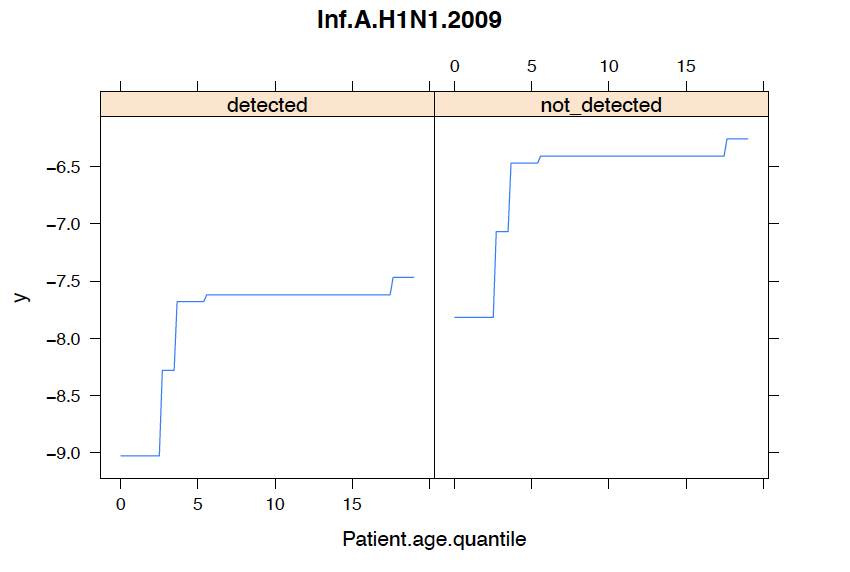
We also analyze the conditional probability plots of the top 5 most important variables below, where the x-axis represents the predictor and the y-axis represents the likelihood of infection .
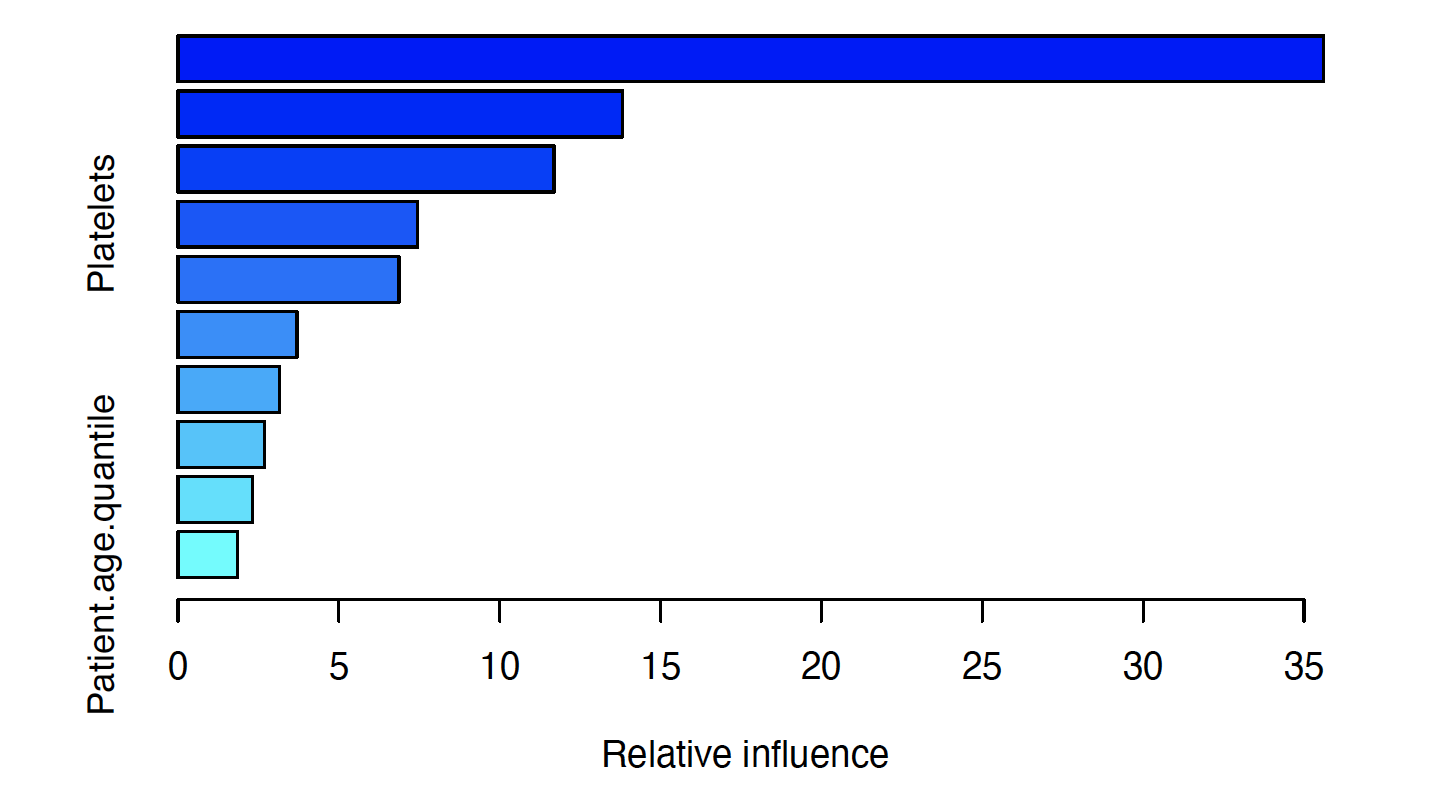
We also analyze the conditional probability plots of the top 5 most important variables below, where the x-axis represents the predictor and the y-axis represents the likelihood of infection .
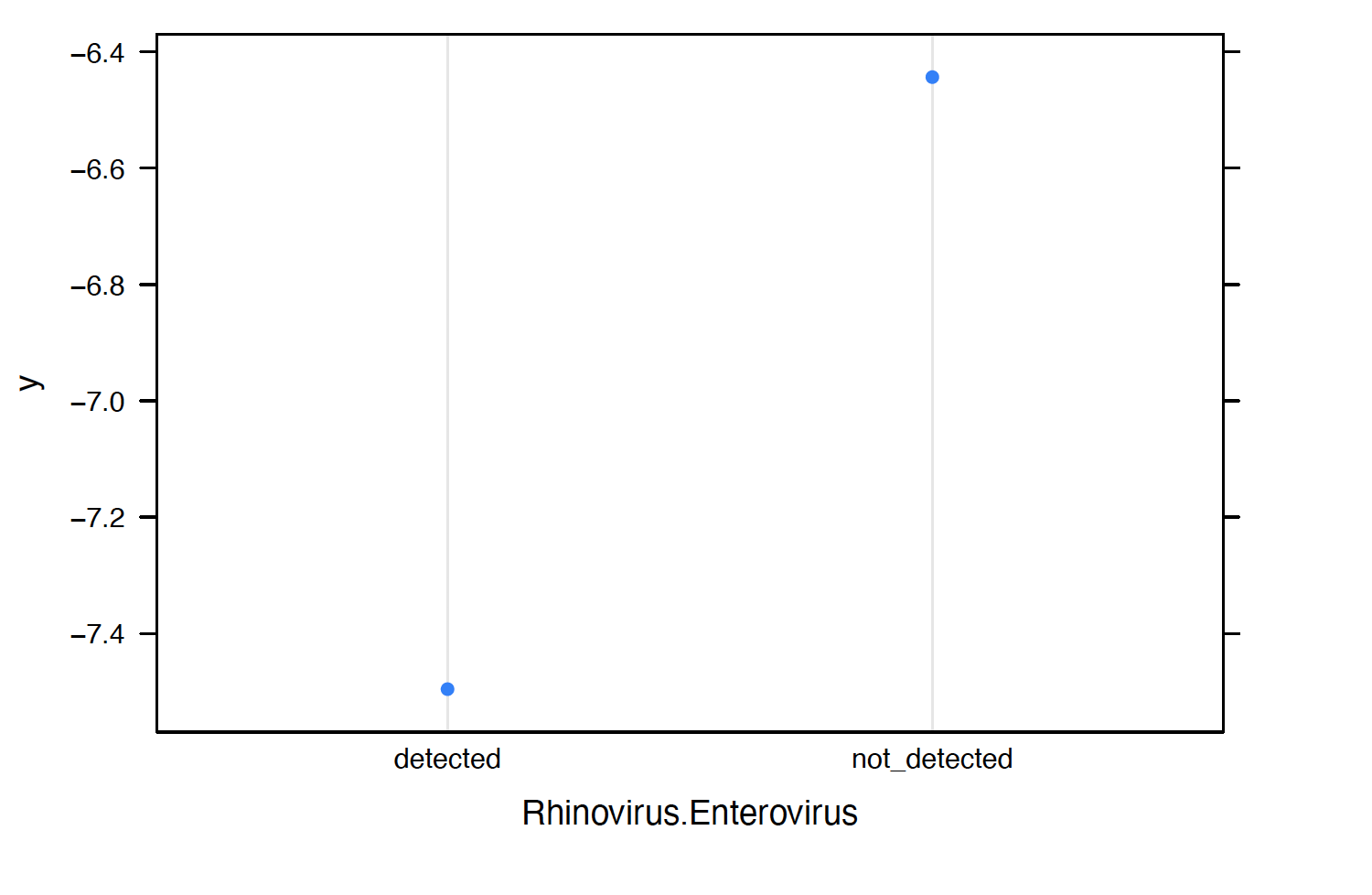
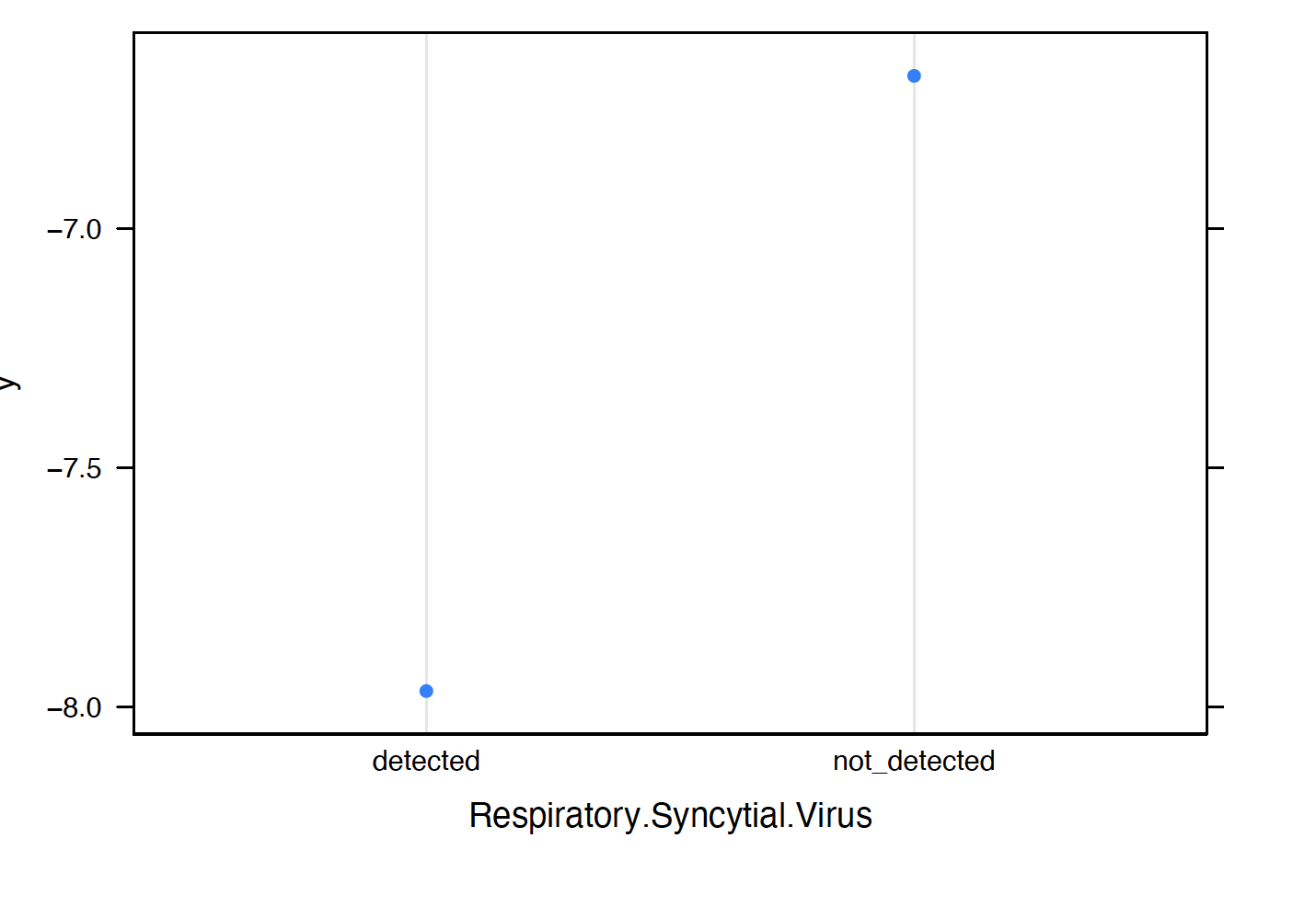
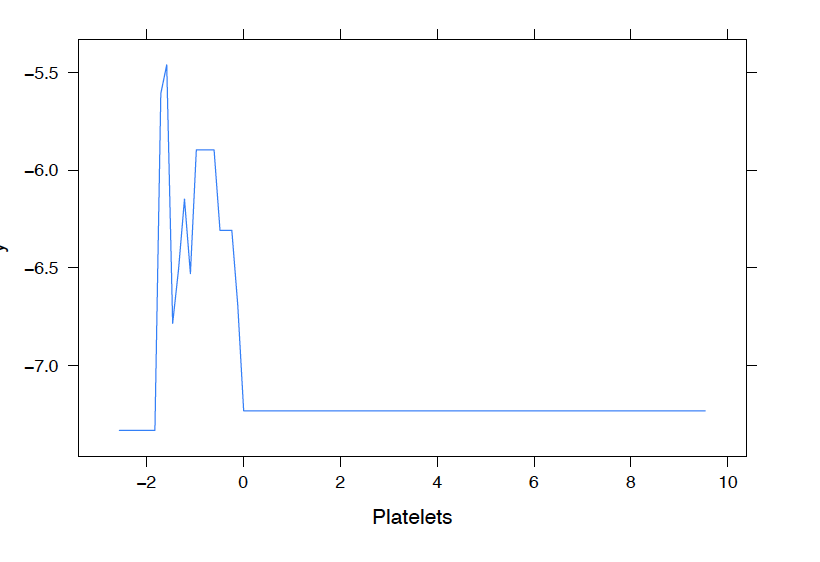
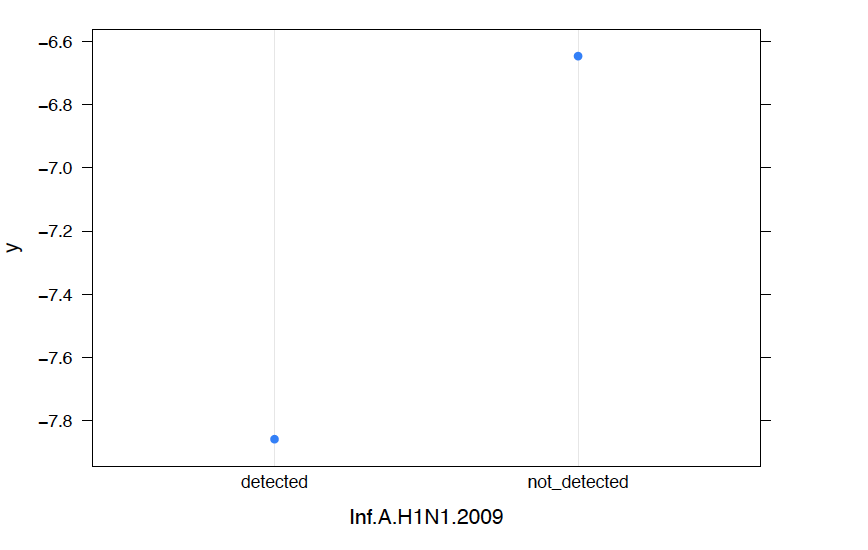
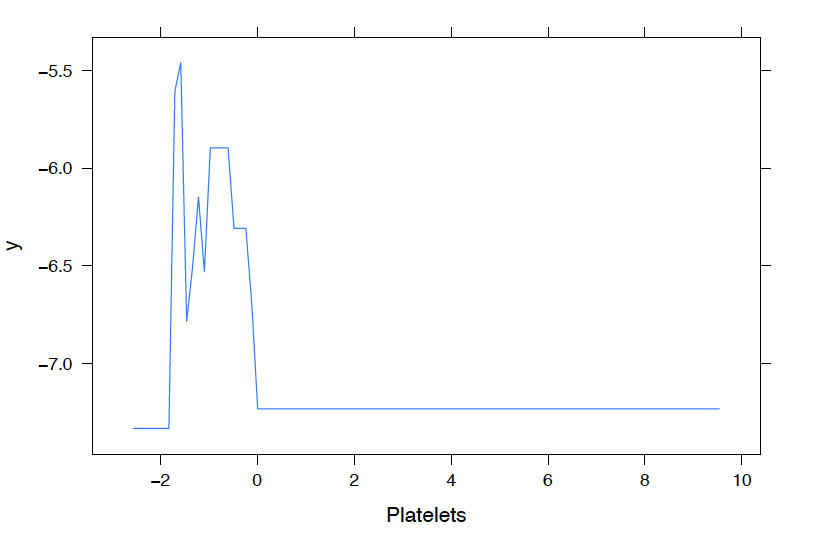
We observe the following:
Patients are more likely to test positive for COVID 19 when Rhinovirus.Enterovirus, Influenza.B or Inf.A.H1N1.2009 are not detected
Patients with low Leukocytes or Platelets are more likely to test positive for COVID 19
Age is widely discussed as a leading indicator of severe COVID-19 cases. Therefore, we analyze the correlationship between the variable age_quantile and the top 5 most important variables discussed previously.
We observe that a patient's age quantile can increase the likelihood of COVID 19 infection regarding top 5 variables.
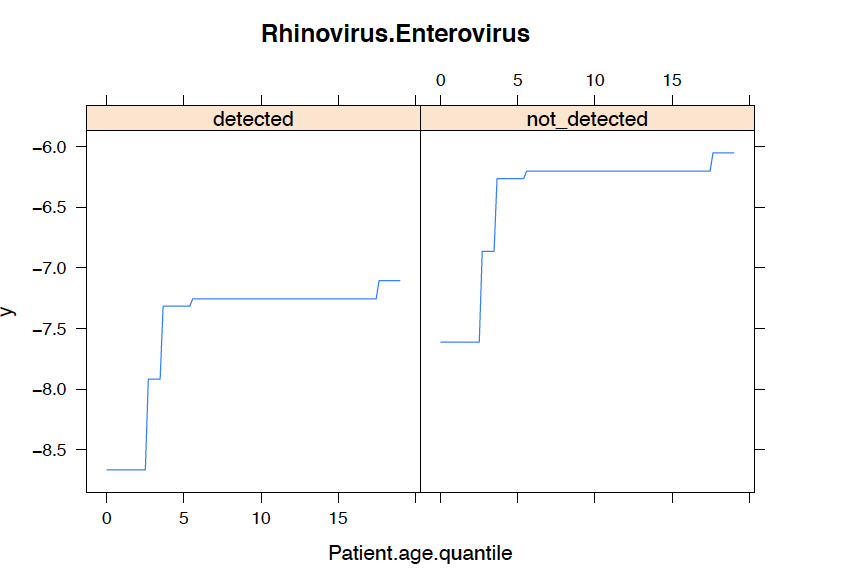
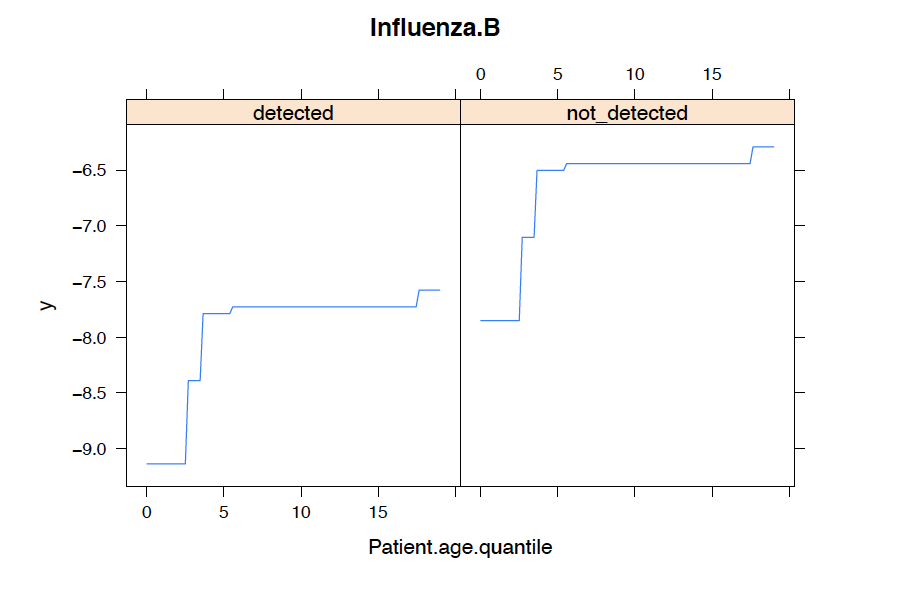
Prediction
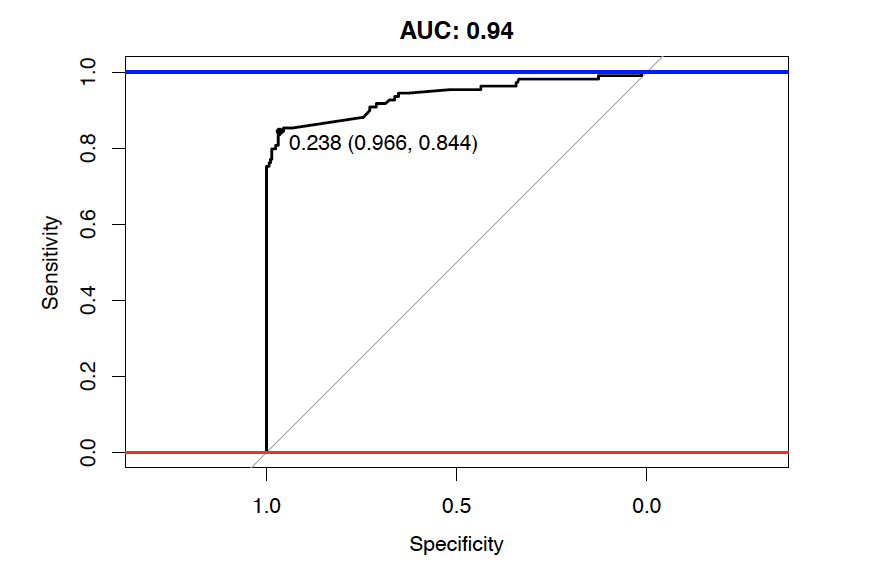
When we apply the trained model to the test dataset, the model turn out to perform very well with an AUC of 94%. However, the determination of model's specificity and sensitivity relies on the definition of a likelihood threshold to determine patients that will be considered as likely positive COVID-19 cases among suspected cases.
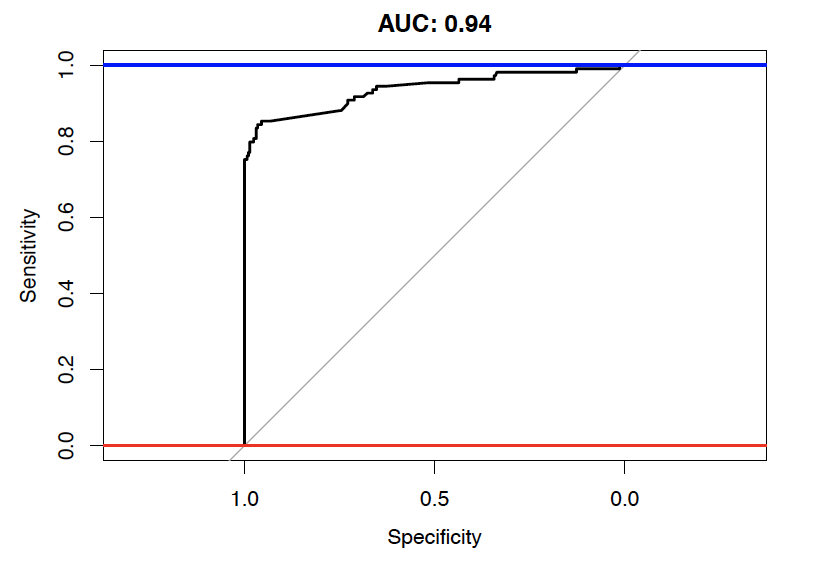
A model with high sensitivity achieves good results in finding positive patients among those true positive patients. However, the number of patients predicted to be positive can be too high and impact the model's specificity.
Moreover, the hospital may not have enough resources to apply the necessary procedures for all patients assigned with a positive label if that number is too high. Hence, an ideal model is one that is well-balanced, i.e., one that has high sensitivity but it does not over-assign patients with positive labels.
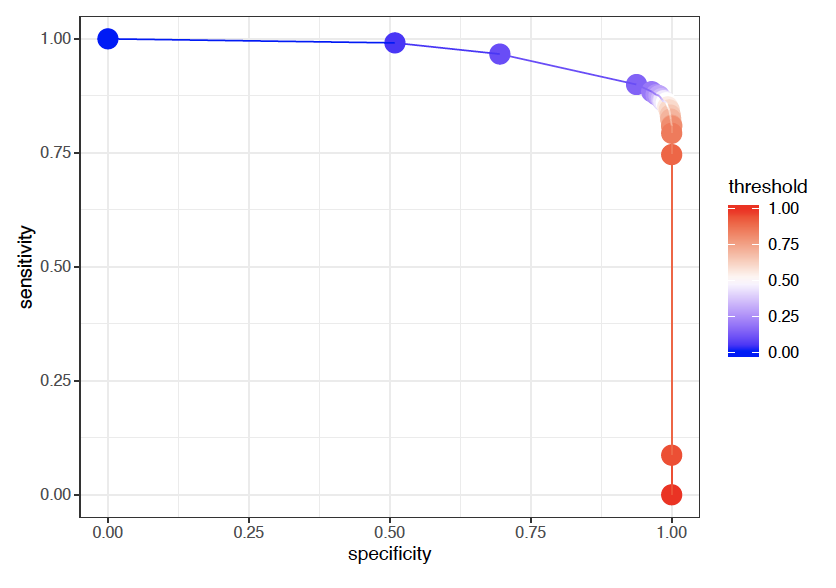
Scenario 1: High availability of resources
In Scenario 1, Let say that the hospital prepares enough resources. In that way, the model can be relaxed and over-estimate the number of positive cases. Hence, our objective function is one that maximizes sensitivity.
We use the train data to select the threshold that maximizes the model's sensitivity. We then apply this threshold in the predicted probabilities in the test set. The procedure returns a probability threshold of 5.8% and the model presents a high sensitivity value of 98%, as intended.
However, the high recall comes at the cost of specificity, which presents a low value of 21%. Moreover, about 79% of the patients from the test set were labeled as positive, hence the model has limited usage as a prioritization tool.
Scenario 2: Limited resources
In Scenario 2, we assume an environment with limited resources, hence a reduction in the model's sensitivity is acceptable if we can obtain a well-balanced model, overall. For that purpose, we choose as objective function one that maximizes the Youden J's statistic defined as $max(sensitivity + specificy)$.
After making a prediction on the test set, we will then choose a threshold from the train set that maximizes the Youden J's statistic to achieve a well-balanced model. We observe that the model under Scenario 2 now delivers a Sensitivity of 82% compared to 98% from Scenario 1. However, it returns a Specificity of 97% while maintaining a high AUC of 94% (as the choice of threshold does not influence the AUC), hence delivering a more well-balanced model as expected. Moreover, now the model only assigns 28% of the test set with positive labels, showing to be useful as a potential patient prioritization tool.
Conclusion
The model's output can be used as a tool for prioritization and to support further medical decision making processes. The model has high interpretability further showing that patients admitted with COVID-19 symptoms who tested negative for Rhinovirus Enterovirus, Influenza B and Inf.A.H1N1.2009 and presented low levels of Leukocytes and Platelets were more likely to test positive for COVID-19
Built With
- machine-learning
- model-prediction
- r
- visualization
- wraggling



Log in or sign up for Devpost to join the conversation.