🌱 FarmSage: Crop Recommendations for Sustainable Farming 💡 Inspiration Agriculture is a lifeline for millions, but choosing the right crop for a specific location can be difficult due to changing climate, soil degradation, and inconsistent rainfall. We were inspired to create a solution that empowers farmers with intelligent, data-driven decisions, allowing them to choose the best crop based on measurable soil and weather parameters.
By leveraging machine learning, we aim to contribute to more sustainable farming practices, better yields, and improved resource usage.
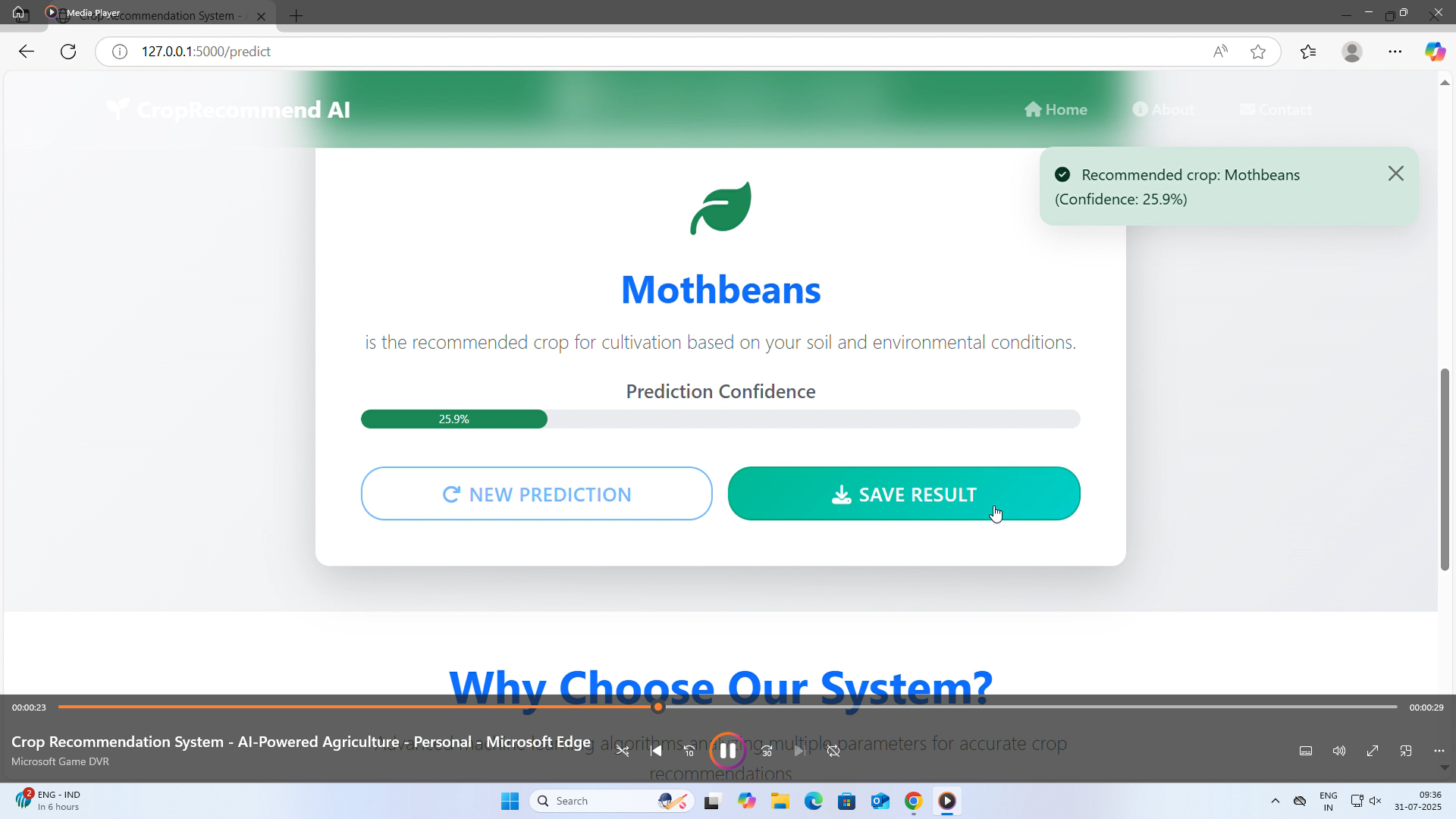
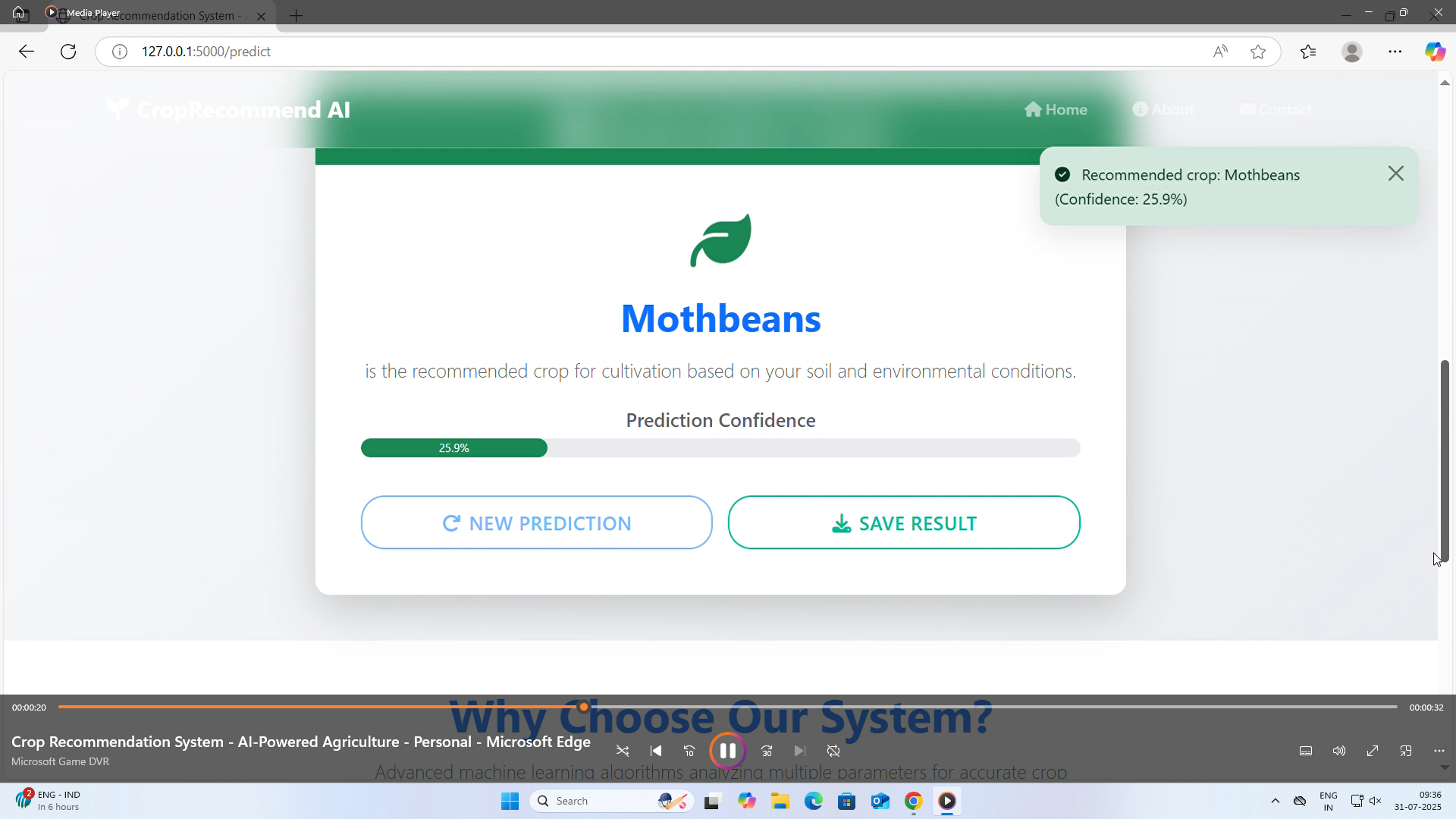
🤖 What it does FarmSage is a crop recommendation system that:
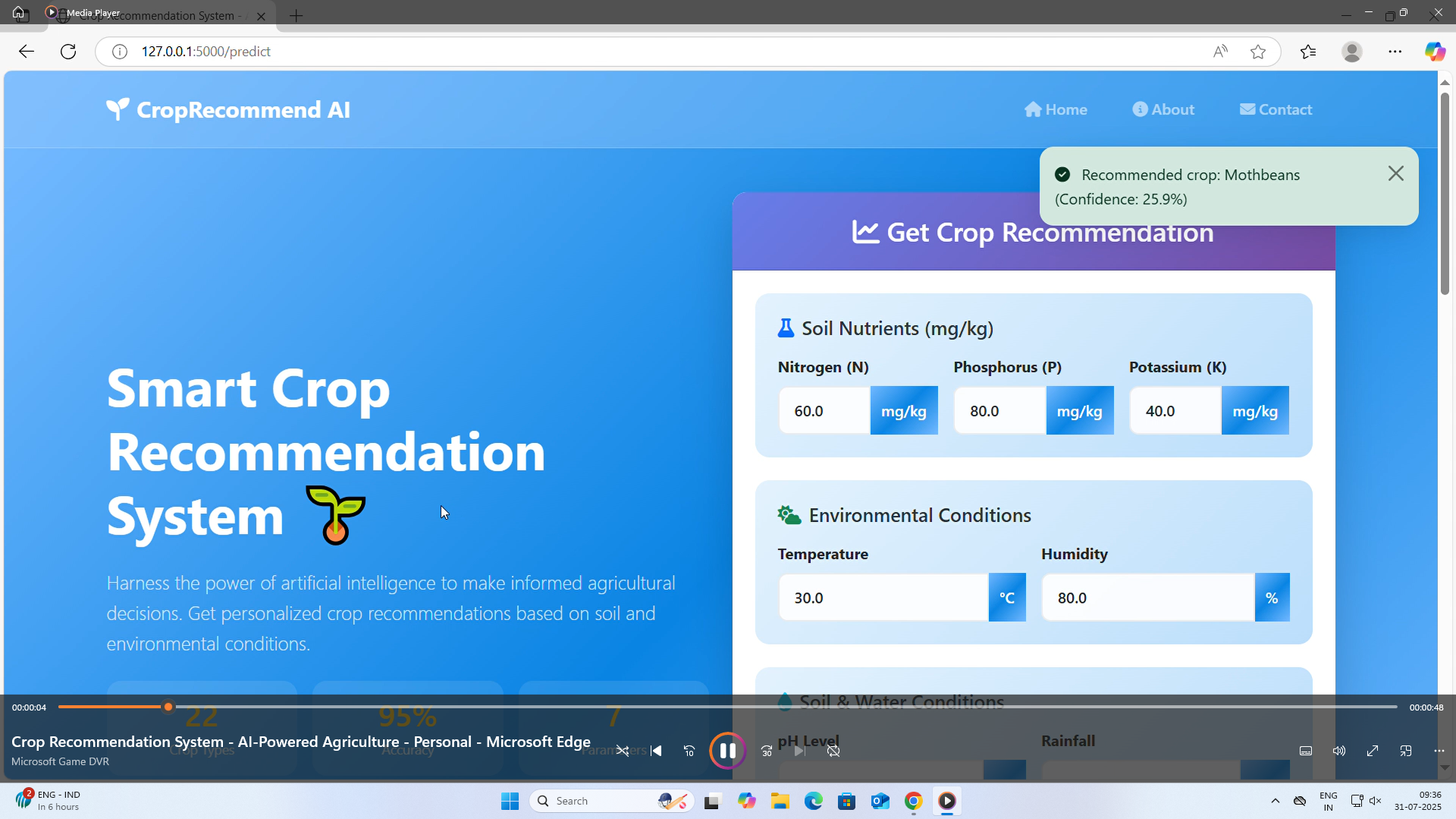
Takes soil nutrient values ((N), (P), (K)), pH, rainfall, temperature, and humidity as inputs
Uses a trained machine learning model to predict the most suitable crop for the given conditions
Offers a user-friendly web interface built with Streamlit for accessibility
🛠️ How we built it Dataset We used a public dataset containing features like:
Nitrogen ((N))
Phosphorus ((P))
Potassium ((K))
Temperature
Humidity
pH
Rainfall Each row was labeled with the ideal crop.
Preprocessing
Normalized and cleaned the dataset
Split into training and testing sets using train_test_split
Model Training Tested several classification algorithms:
Logistic Regression
Decision Tree
Support Vector Machine (SVM)
Random Forest Random Forest gave the best performance:
python Copy Edit from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() model.fit(X_train, y_train) Evaluation We used metrics like accuracy and confusion matrix:
Accuracy
𝑇 𝑃 + 𝑇 𝑁 𝑇 𝑃 + 𝑇 𝑁 + 𝐹 𝑃 + 𝐹 𝑁 Accuracy= TP+TN+FP+FN TP+TN
Deployment Built an interactive Streamlit web app where users can input data and receive crop recommendations instantly.
🚧 Challenges we ran into Data limitations: Agricultural datasets often lack diversity or real-time updates.
Model overfitting: Balancing performance on both training and testing data was tricky.
UI/UX for Streamlit: Designing a simple and intuitive form took time and iteration.
Feature scaling: Ensuring consistent scale across variables to prevent bias in prediction.
🏆 Accomplishments that we're proud of Built a fully functional crop recommendation system
Achieved high model accuracy (above 95%) with Random Forest
Successfully deployed the system with an intuitive interface
Translated complex machine learning predictions into real-world utility
📚 What we learned How to work with real-world agricultural data
Importance of data preprocessing in model performance
Strengths of various classification algorithms
Deployment skills using Streamlit
How technology can genuinely impact sustainable agriculture
🚀 What's next for FarmSage: Crop Recommendations for Sustainable Farming 🔄 Real-time weather integration using APIs
📱 Develop a mobile app version for broader reach
🧪 Add fertilizer and pesticide recommendations
🗺️ Use geolocation data to personalize predictions
🧠 Explore deep learning for multi-crop prediction and precision farming
Built With
- decision-tree
- etc.)-data-preprocessing-model-evaluation-streamlit-?-for-deploying-the-machine-learning-model-in-a-user-friendly-web-interface-jupyter-notebook-?-for-prototyping
- git
- jupyter
- matplotlib
- notebook
- numpy
- pandas
- python
- scikit-learn
- seaborn
- streamlit
- svm
- visualizing-data

Log in or sign up for Devpost to join the conversation.