-
-
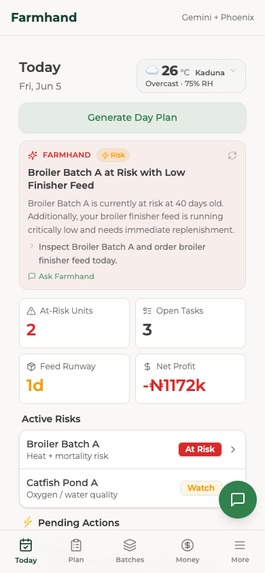
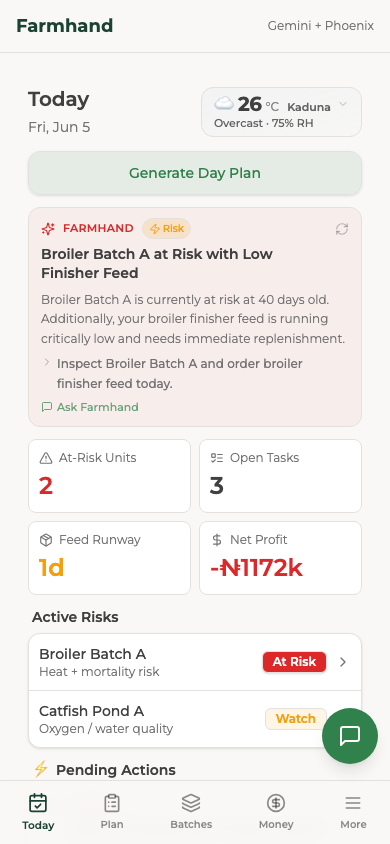
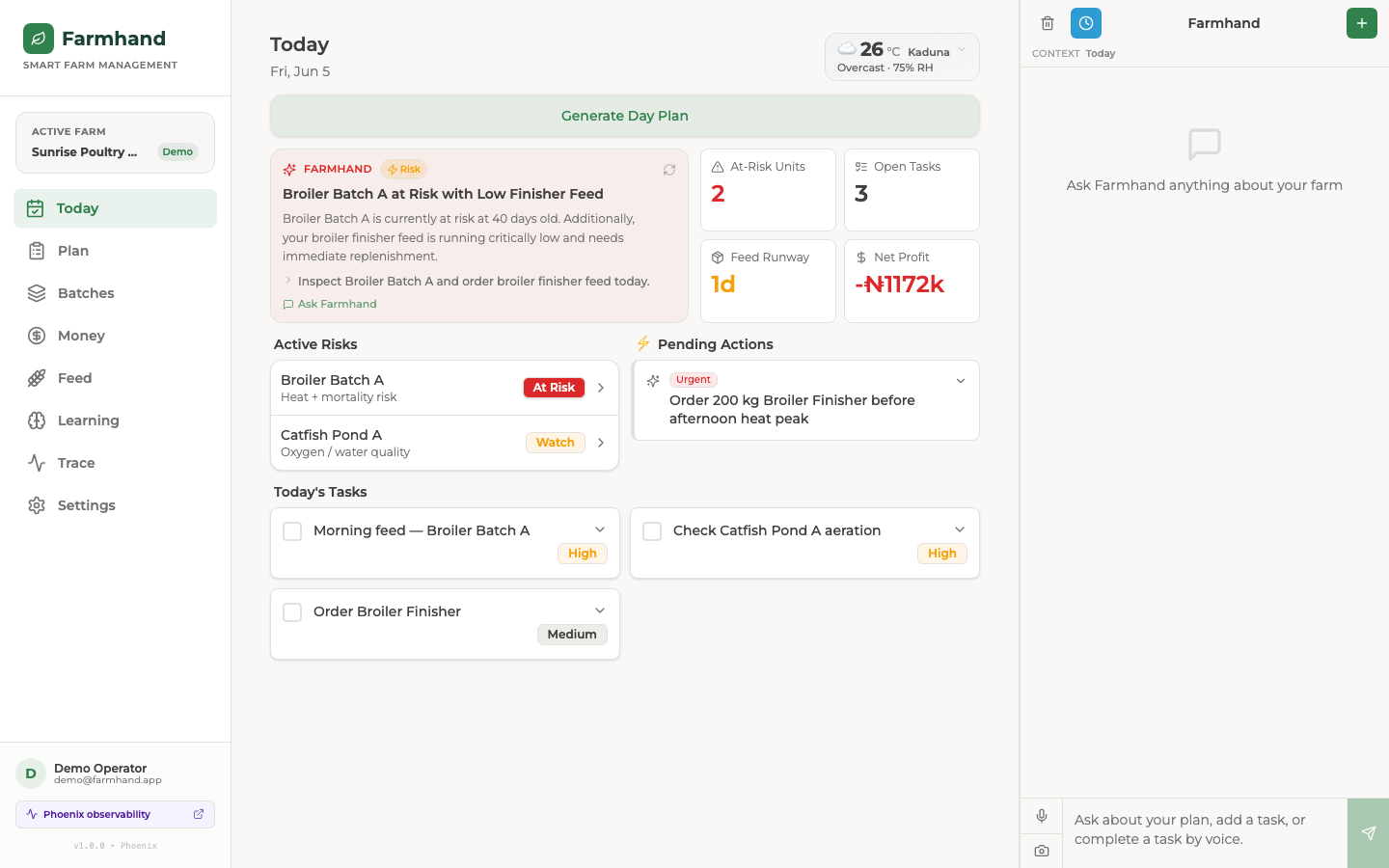
Today page mobile
-
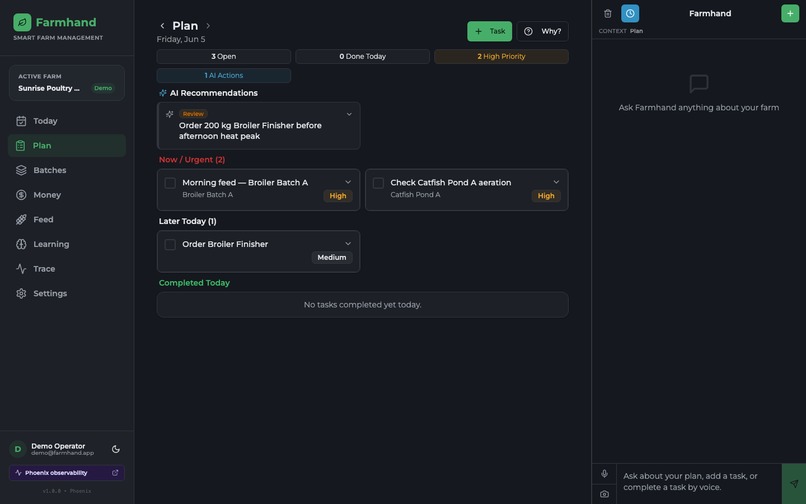
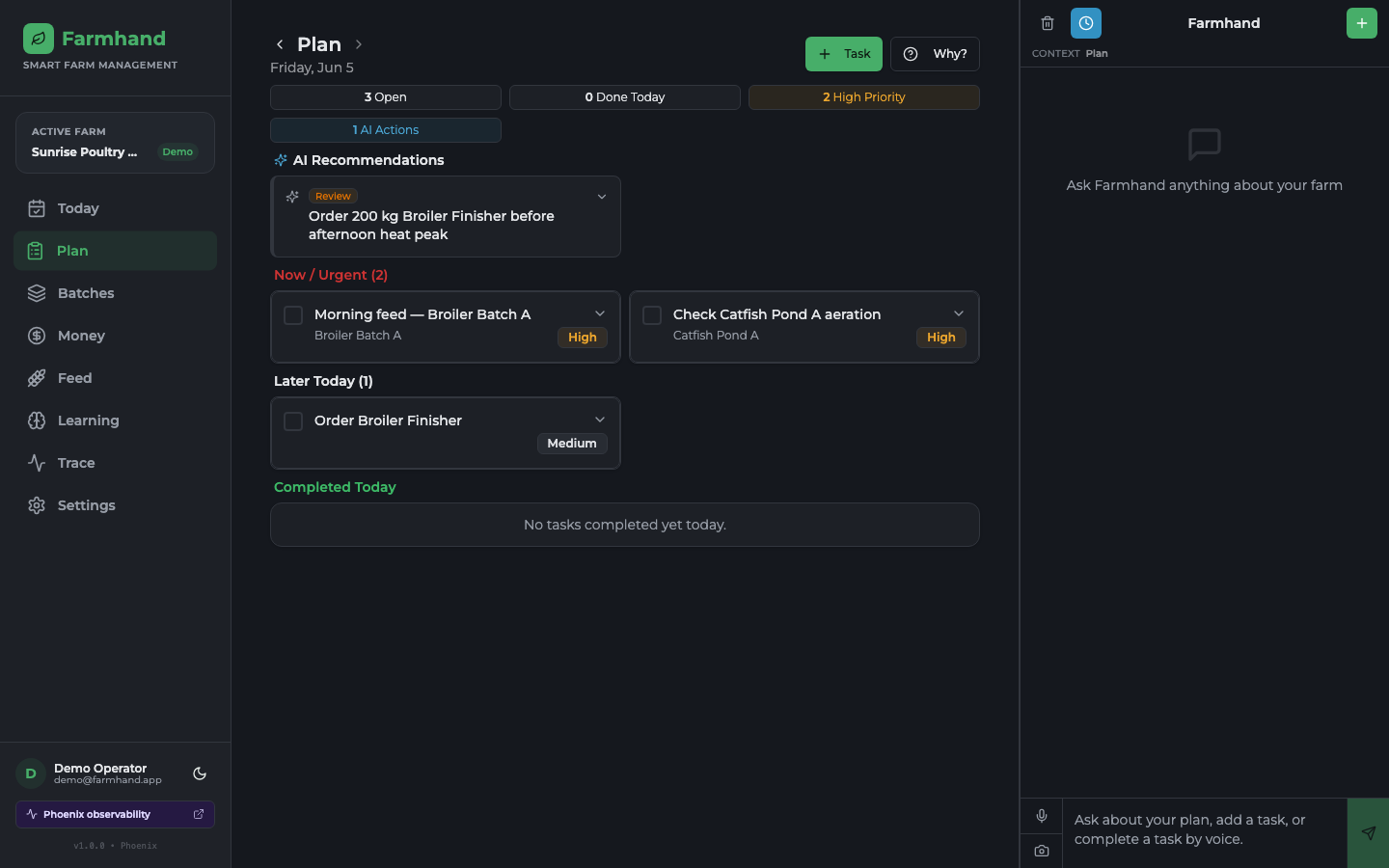
Plan and recomendations page
-
Settings page
-
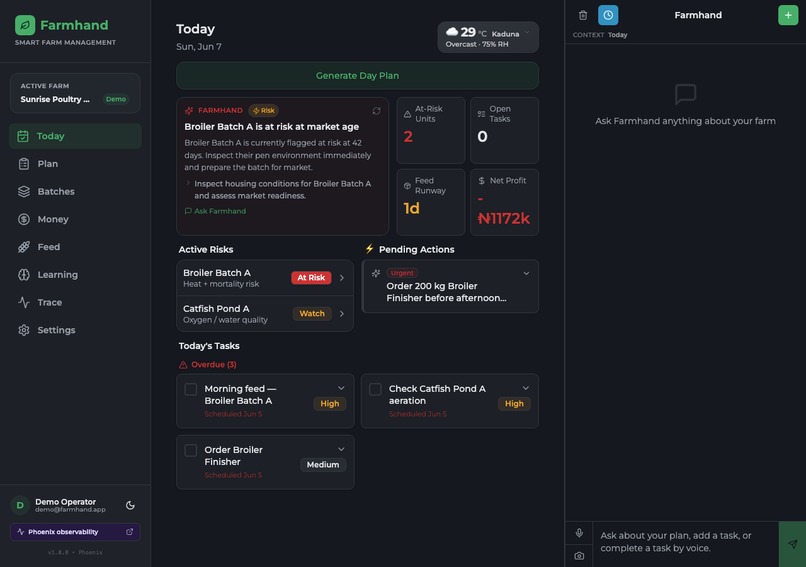
Today page Dark
-
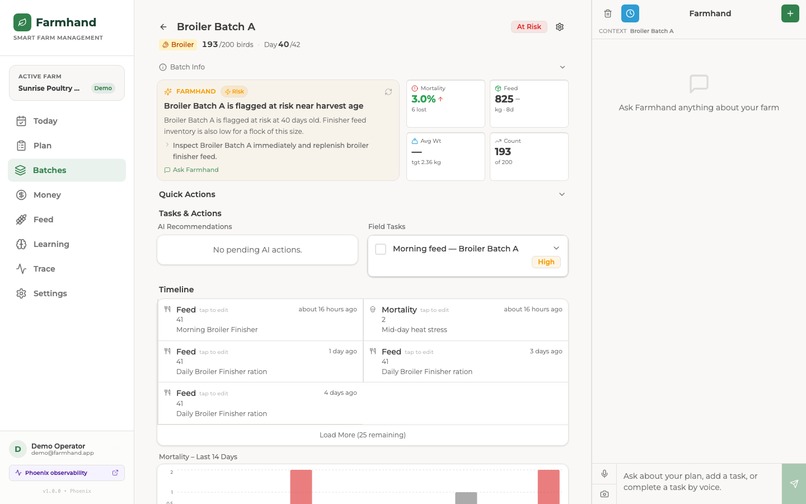
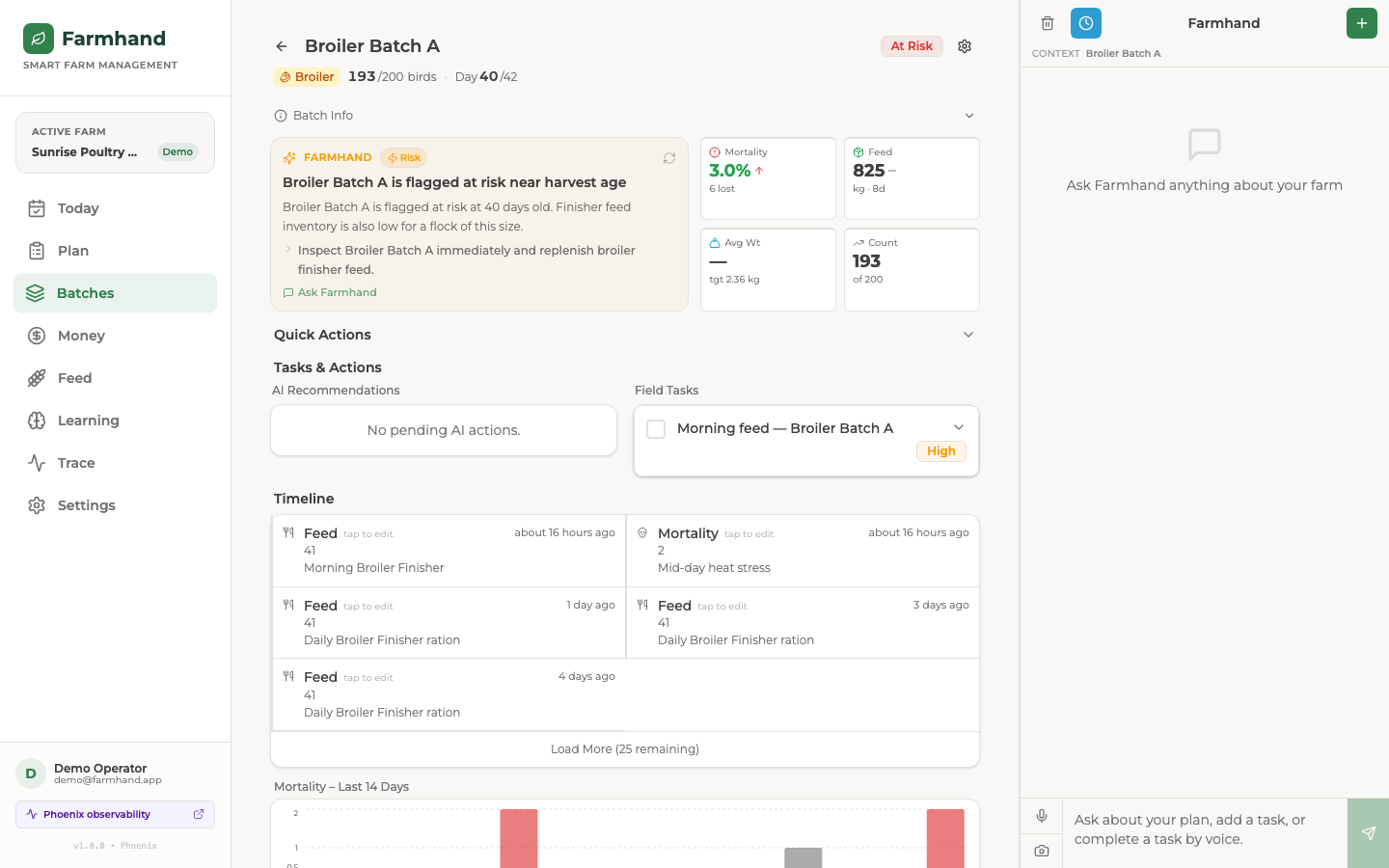
Batch Detail Page
-
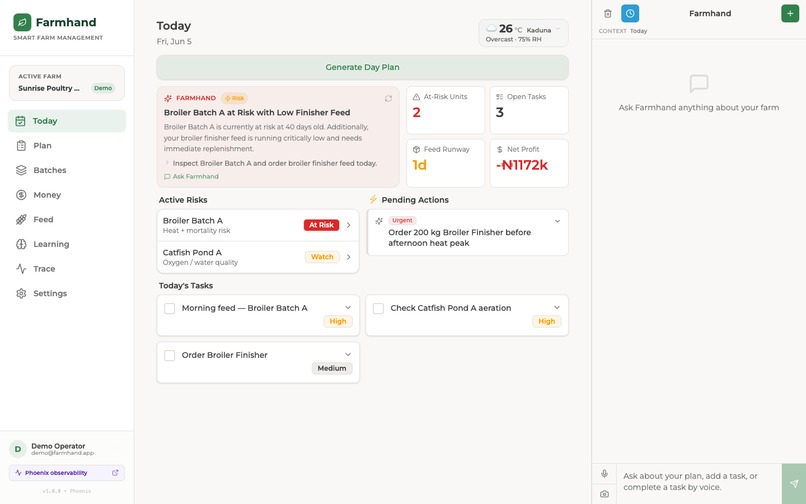
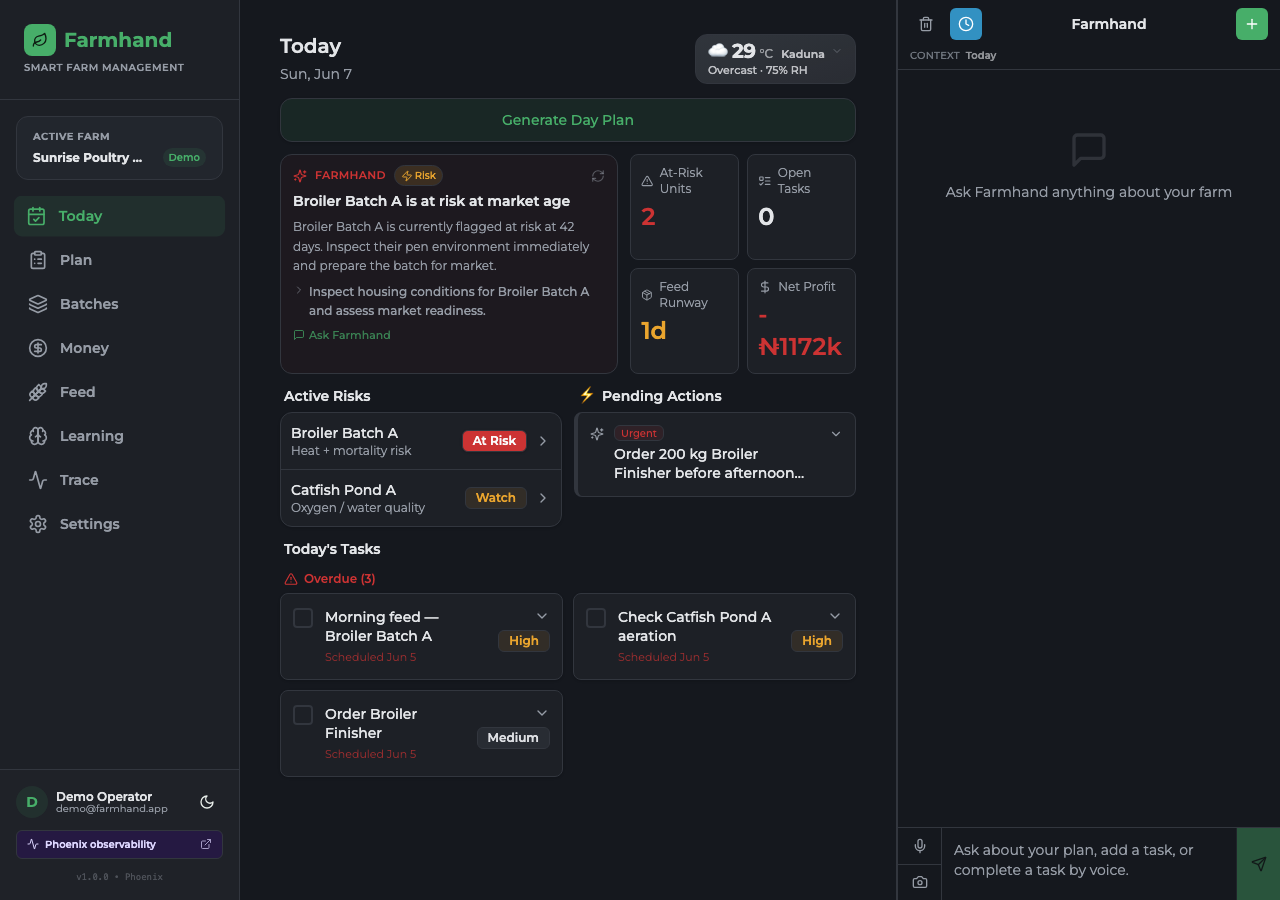
Today page light
-
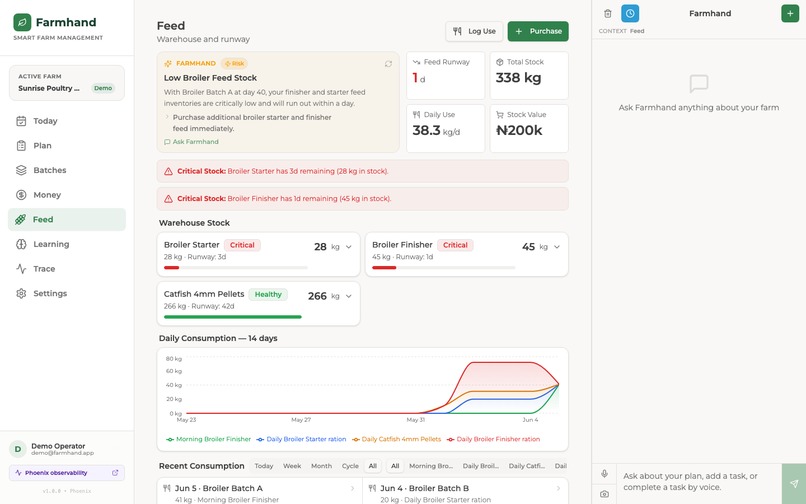
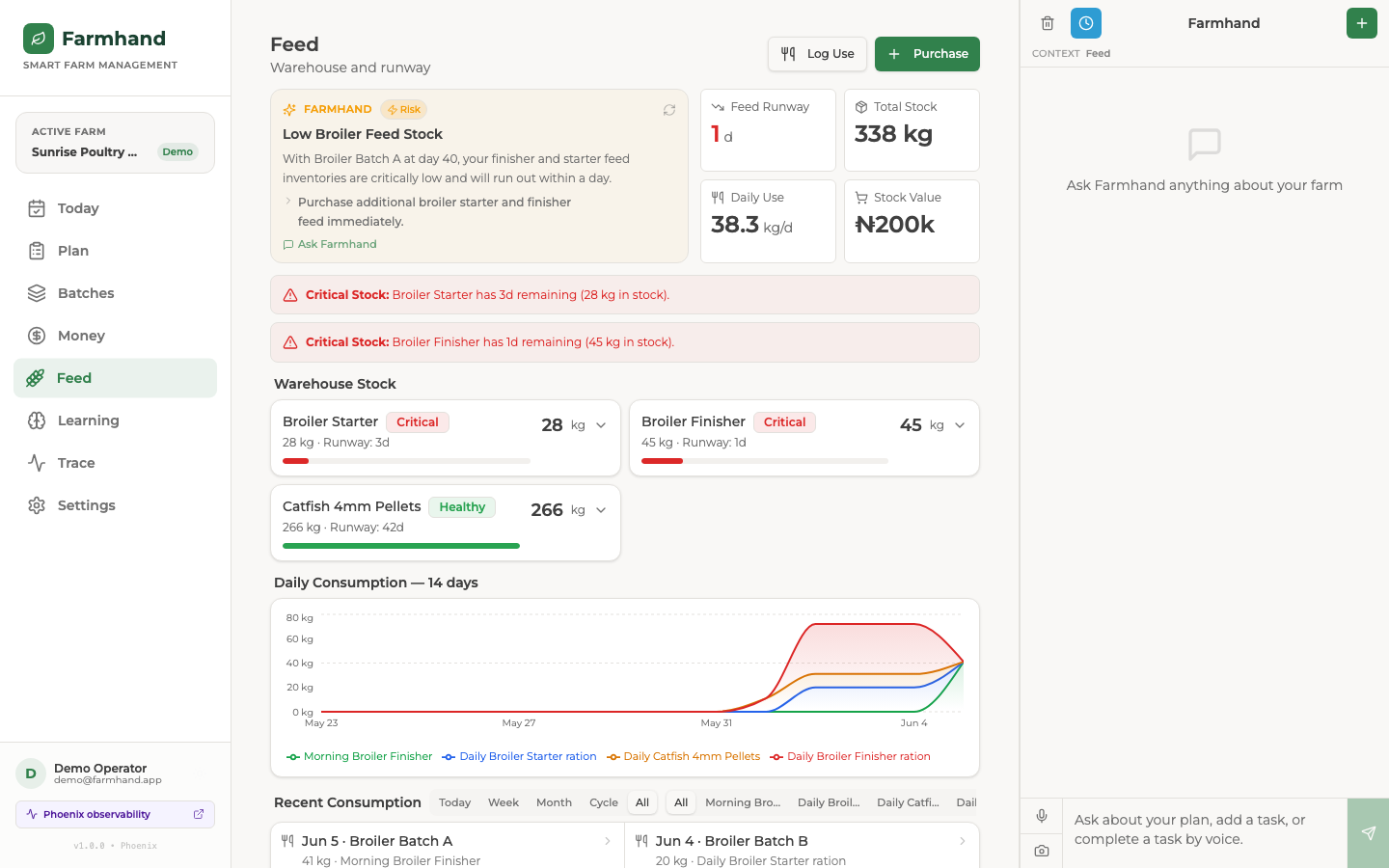
Feed page
-
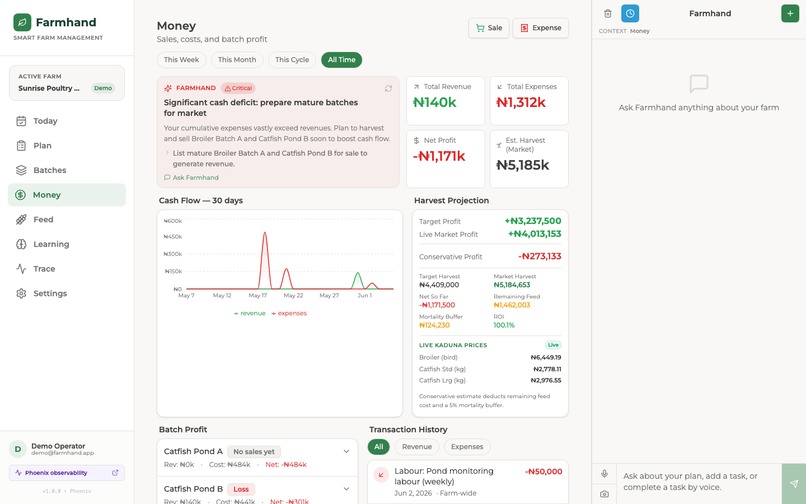
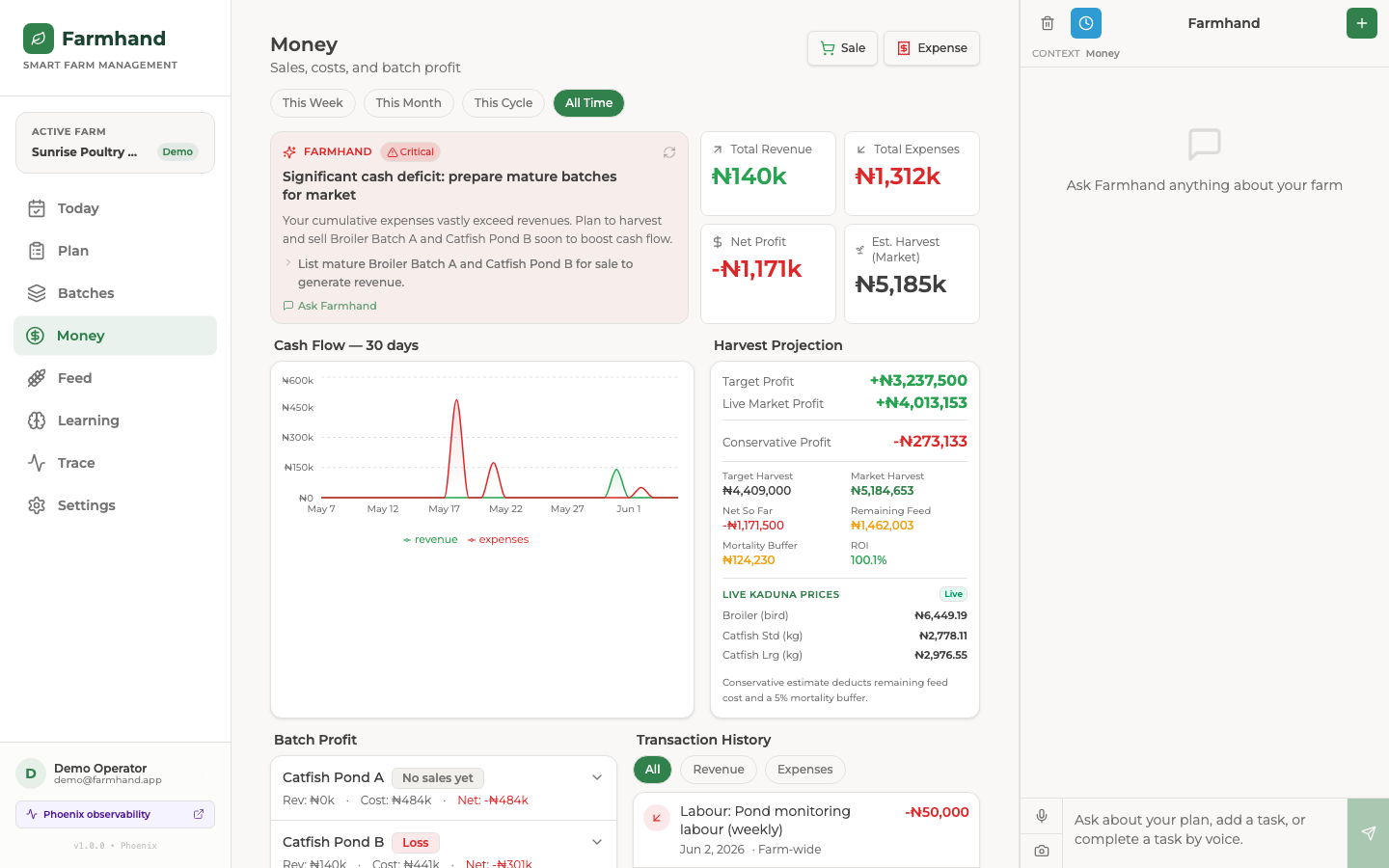
Money Page
Inspiration
I keep broilers and catfish. On a bad morning you walk into the pen before the sun is properly up and you start counting the ones that didn't make it through the night. A late feed run, a missed water check, one cold Harmattan night you didn't plan for, and a batch you've fed for weeks turns into a loss you carry for months. The margins are thin, the mistakes are expensive, and most of us are running the whole thing on a dry-erase board, a paper ledger, and a noisy WhatsApp group.
What I actually wanted every morning was an answer to one question: "what should I do today?" Not a dashboard. Not another app to fill in. Just a straight answer, based on my real birds and my real ponds.
But I'd also been burned by AI tools that are brilliant for a week and quietly wrong by the second month. They never learn from the times they get it wrong. So I set myself a harder goal. I wanted an agent that could watch its own mistakes, suggest a fix, and slowly get better, while I stayed in charge and approved every change. That self-improvement loop ended up being the whole heart of Farmhand.
What it does
Farmhand is a farm assistant you can just talk to.
It plans my day around real units. I ask for a plan and it reads my live farm state (mortality, feed runway, water, money, the weather and the season) and gives me specific tasks for named units like Broiler Batch A or Catfish Pond B. The feed-runway warnings come from real growth and intake numbers, not a generic checklist.
It speaks the way I do. I type "10 birds died in Batch A" or "bought 5 bags of finisher feed," and it separates the livestock event from the money, then drafts the records for me to confirm. No forms to fill.
It never quietly touches my books. This is the rule I care about most: recommendations are not records. Approving a plan is just feedback. My ledger, my inventory, and my bird counts only change when I confirm a record myself. The AI can suggest. It cannot reach into my money on its own.
And it gets better, with my permission. Farmhand watches its own runs. When it slips up, like naming a batch that doesn't exist or suggesting medicine without telling me to see a vet, it gathers those mistakes, writes one rule to fix itself, and shows it to me on a learning page. I approve it, and the next plan stops making that mistake.
How we built it
I built it code-first on Google ADK, with a FastAPI backend and a Postgres database. There are six small agents working behind one coordinator: a router, a planner, a record parser, a judge, a trace inspector, and the one I'm proudest of, a self-improvement agent. They share 17 tools. The read tools pull live farm state, weather, market prices, and past notes. The write tools only ever draft something. They never change a record on their own.
To keep the cost sane I run Gemini Flash on Vertex AI in two tiers. A smarter tier with more thinking handles the hard work like planning and self-improvement. A lighter tier on minimal thinking handles the routine stuff like routing, parsing, and judging. That split cut the token bill a lot without making the real reasoning any weaker.
The part that ties it all together is Arize Phoenix. Every plan run becomes a trace tree. One root span, then the planning agent, then each tool it calls, then the Gemini calls, all tagged by farmer and session. On every run I fire two kinds of checks. Deterministic ones (no medication dosage, no culling on its own, the plan has to name a real unit, the right tool was used) and LLM judge ones (is it grounded, is it actionable, is it safe). The results get written straight back onto the run as Phoenix span annotations. And every time I approve, reject, or edit something, that decision gets written as a human annotation on the exact span that produced it.
That trail of traces and evals is what powers the loop. The trace inspector and self-improvement agents read the project's own traces and failing evals through the Phoenix MCP server, group the failures together, and write the proposal. The frontend is a TanStack Router and Vite PWA with a little tray that shows me every tool call, how long it took, and what went in and out, so I can see exactly why the agent said what it said. The whole thing runs on Cloud Run.
Challenges we ran into
A few things genuinely fought me.
The first was Vertex's global location. My agents kept throwing silent 404s from a regional Cloud Run service, and it took me a while to work out why. The Gemini Flash models I needed are only served from the Vertex global location. I had to point the Vertex location at global while keeping the database regional before the calls would go through.
The second was that the telemetry was slowing everything down. Running the evals and writing annotations in the middle of a request made the whole app feel heavy. I moved all of it onto a background worker queue with retries, so the traces and annotations write in the background and I never sit there waiting on observability.
The third was the agent losing the thread of a conversation. Early on, if it asked "which batch?" and I answered "batch a," it treated my two words as a fresh, confusing new message. I fixed it by feeding recent chat history back in and sending short replies straight to the record parser, so talking to it actually feels like talking.
Accomplishments that we're proud of
The self-improvement loop actually closes, and that's the thing I'm happiest about. It isn't a fake screen. The agent reads its own Phoenix traces over MCP, finds the evals that failed, writes one clear proposal, and once I approve it the next plan behaves differently and the eval that was failing passes. Watching the thing fix its own behaviour, on my say-so, still feels a little unreal.
It also genuinely understands my farm. Feed runways come from real broiler intake curves and catfish feed-to-bodyweight ratios. It knows the Harmattan is coming. It talks in 25kg poultry bags and 15kg fish bags, and it tells me to check pond colour, foam, smell, and whether the fish are gasping before it ever mentions a sensor.
I'm proud that the telemetry is something I can actually see, instead of being buried in a backend somewhere. And the safety rule held the whole way through. A recommendation never quietly turned into a change in my money or my bird counts. 64 tests, all green.
What we learned
Telemetry is a feature for the user, not just a tool for the developer. I always thought of tracing as backend monitoring. The moment I put the spans, the tools, and the evals in front of the farmer, the AI stopped feeling like a black box. That visibility is how you earn trust.
You really don't need the biggest model for everything. Letting a smart tier do the reasoning and a light tier do the routine work was the difference between an agent I could actually afford to run and one I couldn't.
And keeping myself in the loop made it better, not slower. Farmhand is at its best when it suggests and I decide. The self-improvement loop only works because nothing changes without me approving it first.
What's next for FarmHand
Sensors. I want to wire real-time temperature, humidity, and pond pH straight into the agent's tools, so the environmental checks happen without me logging them by hand.
Working offline. The network out here drops all the time, so I want to queue logs on the phone and sync them up when the connection comes back.
More hands. I want an owner to be able to hand tasks to workers and see what actually got done, so a cooperative or a bigger farm can run on it too.
Built With
- arize
- cloudsql
- fastapi
- gcp
- google-cloud
- phoenix
- postgresql
- tanstack

Log in or sign up for Devpost to join the conversation.