-
-
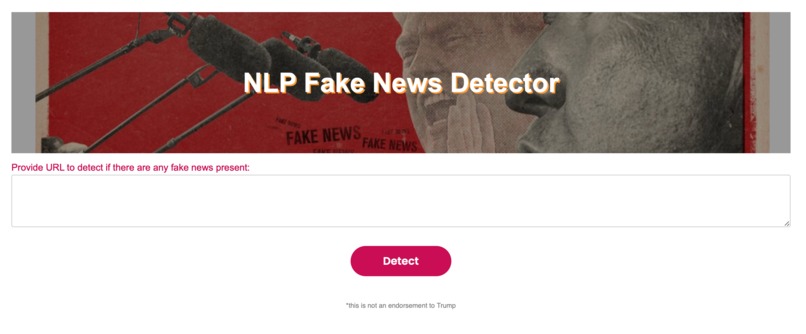
web home page

Categories we would like to go for: Student Life, Health and Fitness, Social Good, Humor, General, Beginner (Team entirely composed of students in second year)
Inspiration
Information Technology is increasingly being used to spread false or misleading information. Since it is difficult for readers to distinguish between real and fake news, we decided to build an Machine Learning (ML) model to do it for them!
What it does
When the user suspects an online article of being fake, they can pass the article URL to the program. The program uses web scraping to gather the article headline and contents, then passes the text to a BERT-based NLP model which returns whether the article is real or fake, as well as the percentage likelihood.
How we built it
The BERT model is based off of this Kaggle Notebook with slight variations. The model is trained in Google Colab, and the final weights file is downloaded. A local Python script reconstructs the model and loads the weights file so it can make predictions based on the input news article.
Challenges we ran into
Some of the challenges we ran into were the lack of sleep from our team members, and our Flask backend not properly interfacing with our ML model. However, with encouragement and support from the 4 of us, we pushed through the lack of sleep. As well, after doing some studying of our own, we were able to diagnose our Flask error and correct it.
Accomplishments that we're proud of
Our team has very little experience with Flask but we managed to learn it within 12 hours and build a fully functioning app from scratch. As well, we are proud that this is not only a data science project but also a web application that uses the latest model Bert for Natural Language Processing in our ML model, thus becoming a trusted tool for users to determine fake news from real news.
What we learned
We learned how to utilize the power of friendship and teamwork so that we can come together as one to build an impactful project in the span of this weekend! As well, our entire team learned how to use Flask and how to interface it with our ML model and the Natural Language Processing within the ML model.
What's next for Fakeout
We are looking at building a mobile version/chrome extension, thus making Fakeout more convenient and easy to use. As well, we are looking at expanding our ML model to be also able to analyze audio/video contexts, allowing us to detect fake news beyond the textual interface. Last but not least, due to the time pressure, we don't have time to improve the model with a larger dataset (maybe Trump's Twitter history) so that it gives the most accurate prediction.



Log in or sign up for Devpost to join the conversation.