Inspiration
Modern elections are shaped by social media platforms like Twitter. Discussions that occur on the platform are of great importance to voter informedness, the policy of candidates, and the ultimate outcome of the vote. But like most corners of the internet, Twitter is rife with misinformation.
We wanted to build a dashboard to exemplify how much misinformation there is on Twitter!
What it does
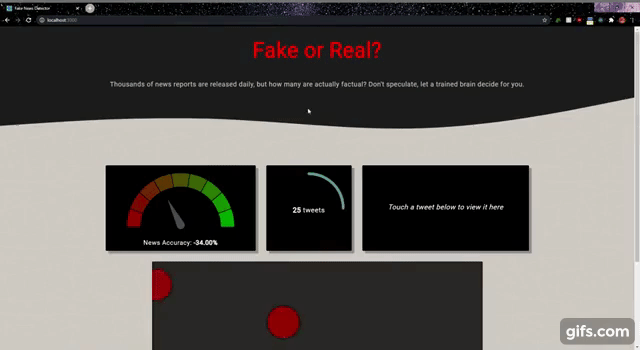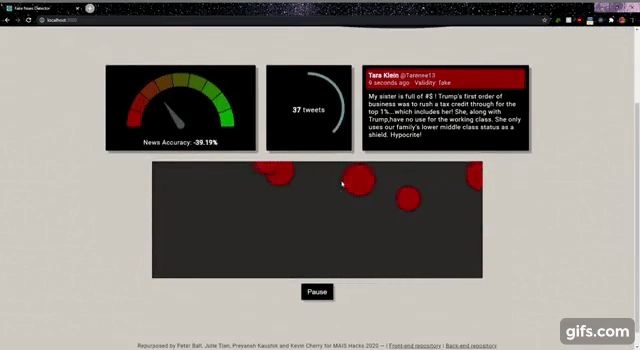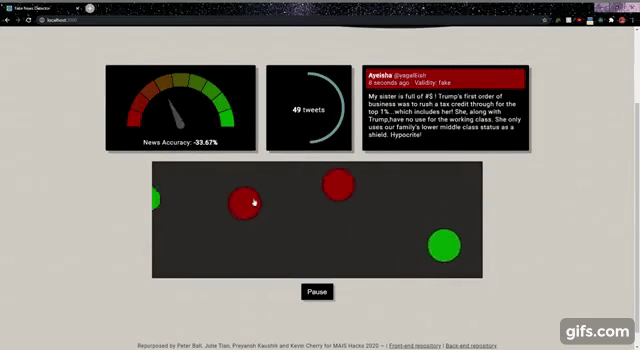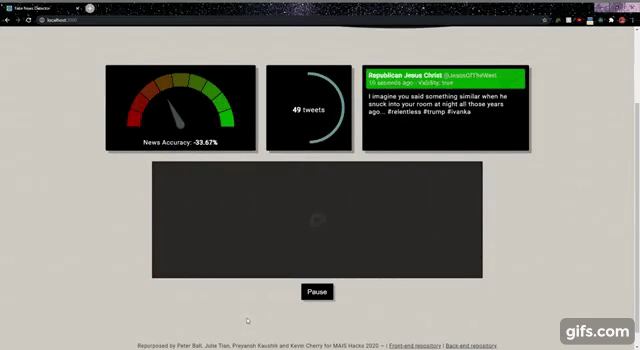
Our goal was to create an interactive dashboard that displays the flow of truths and lies that stream through the platform each day, using NLP to flag tweets that may contain misinformation.
A visualization like this could serve independent election watchdog organizations to monitor the health of the election, be deployed by newspapers in a data journalism piece, or simply provided to the electorate for their consideration.
How we built it
Most fake news detection datasets provide full news articles. Since we wanted to classify tweets, we needed data that looked a bit more tweet-like. We used the Fake News Inference Dataset, which provides one-sentence statements from news articles labelled by Politifact as "fake" or "real". While these do not perfectly resemble tweets, they were closer than the other options we found. We used this dataset to build a model using binary Naive Bayes model, and created an application implementing the model and pulling tweets from a twitter stream. The application shows the news accuracy, number of tweets processed and an interface to interact with the tweets. By hovering over the rolling dots, we are able to see exactly what the tweet is. Additionally, the dots are also coloured to match the news accuracy widget to indicate if the tweet is true or false.
Tech Stack:
- A binary Naive-Bayes model that does our ML work (notebook)
- A flask backend to wrap this into an API, pushed with Docker to GCP (github)
- A modern react frontend (github)
- coffee
Challenges I ran into
Our baseline classifier, a binary Naive Bayes run on tf-idf transformed data, achieved accuracy of 64%. This was lower than expected, and pointed to the problem being rather difficult to solve. Through tuning, we managed to achieve an accuracy of 70%. We also implemented a simple neural network and spent many hours tuning the parameters, but were unable to beat this baseline.
Deploying the backend was not as easy as it should have been.
Accomplishments that I'm proud of
We still managed to get decent accuracy, which is great! We also learnt a lot about deploying ML models to the cloud
What's next for Fake-Tweet-Visualizer
- Keep training and working on improving the performance of our ML Model
- Add widget allowing users to input tweets/text found on the internet to check for truth/fake
- Update the visualizer!




Log in or sign up for Devpost to join the conversation.