-
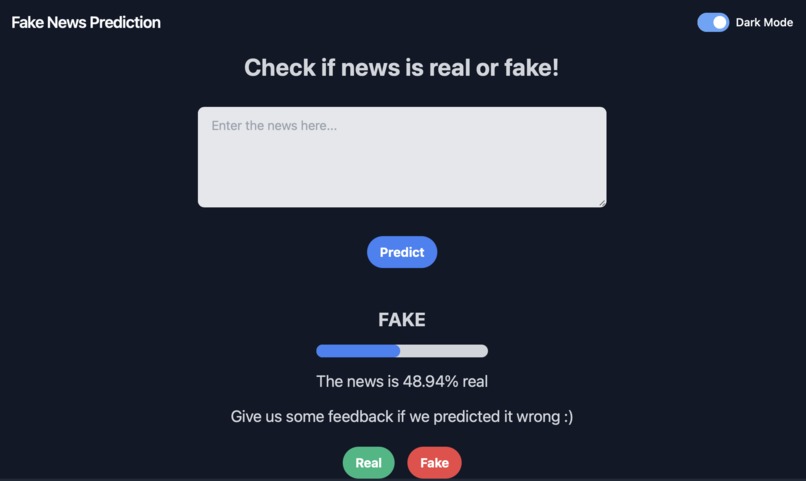
Dark Mode
-
Light Mode
-
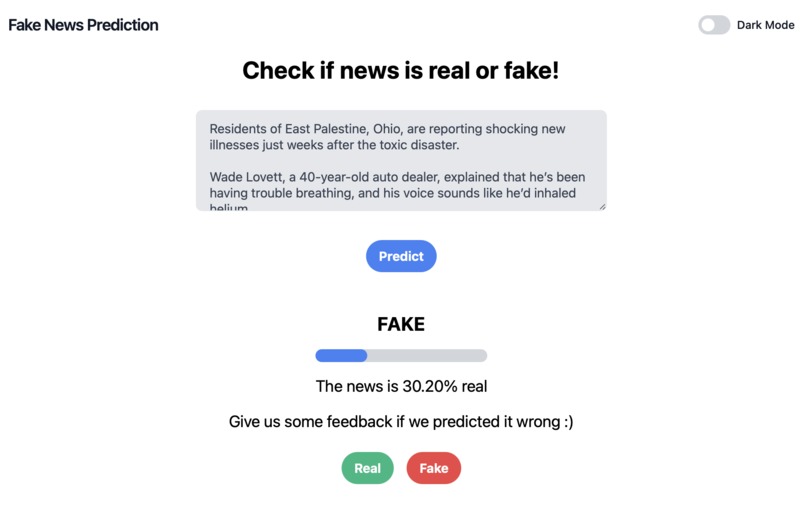
Live Prediction



Inspiration
In recent years, we've seen how misinformation can have serious consequences, from influencing political campaigns to fueling public health crises. We believe that combatting fake news is an important way to promote responsible journalism and protect the public.
What it does
The fake news detector project uses Flask, a Python web framework, to build a web app that allows users to check whether a given news article is real or fake. The app takes in a news article input by the user and applies machine learning models to predict its authenticity. The models used are loaded from pre-trained files stored in the backend server and made using different models in a Python notebook file, where we explored the runtime and square error of different models on a Fake News dataset. The app presents the prediction results to the user, along with a probability score. Users can also provide feedback by clicking on buttons indicating whether the prediction was correct. The feedback data is stored in a CSV file on the server for future analysis. The app also features a dark mode option, enabled by a toggle switch.
How we built it
We built the fake news detector using Flask, a web application framework for Python, as the backend server. The server receives user input, which is the text of the news article and passes it through several machine-learning models to predict whether the news is real or fake. We used the Natural Language Toolkit (NLTK) library to preprocess the text and extract its features. The models we used include Random Forest, Bernoulli Naive Bayes, Decision Tree Classifier, and Principal Component Analysis. We also used a TF-IDF vectorizer to convert the text to numerical data that can be fed into the models.
We also built a simple user interface using HTML, CSS, and JavaScript. The interface allows users to enter the text of the news article, submit it to the backend server for prediction, and see the result. We also added a feedback system to allow users to indicate whether the prediction was correct or not. This feedback is stored in a CSV file that can be used to improve the performance of the machine learning models over time. Finally, we added a dark mode feature to the interface using JavaScript and CSS.
Challenges we ran into
During the development of our fake news classifier, we faced several challenges. One of the main challenges was the imbalance in the dataset, as we had more true news articles than fake ones. This could lead to bias in the model towards predicting most articles as true. To overcome this, we employed oversampling and undersampling techniques to balance the dataset.
Another challenge we faced was the selection of the right set of features for the classifier. We experimented with different feature sets and finally decided to use the TfidfVectorizer to convert the text data to a numerical representation. However, fine-tuning the hyperparameters of the vectorizer was a time-consuming task, as it required several iterations to find the optimal values.
Accomplishments that we're proud of
We're proud to have successfully built and deployed a machine learning model to detect fake news with an accuracy of over 98% on our test dataset. Our team put in countless hours of research, experimentation, and collaboration to develop and fine-tune our model to achieve this high level of accuracy. We're also proud to have created a user-friendly interface for our model, which allows users to enter text and get a prediction on whether it's fake or real news.
In addition, we're proud of the technical skills we developed throughout this project, including proficiency in data cleaning, natural language processing, and machine learning. We also honed our teamwork and communication skills, working together to overcome challenges and achieve our goals. Finally, we're proud to have contributed to the ongoing effort to combat the spread of misinformation, which has become a critical issue in today's society.
What we learned
Throughout this project, we learned how to build a machine learning model to classify news articles as real or fake. We used the Passive Aggressive Classifier algorithm and a TfidfVectorizer for feature extraction. We also learned how to preprocess text data by removing special characters and punctuation, lowercasing the text, and removing stopwords.
In addition, we learned how to use the Kaggle API to download the dataset and how to mount Google Drive in Colab to access files stored in the cloud. We also learned how to use the pandas library to manipulate and combine datasets.
We also learned how to evaluate the performance of the model using metrics such as accuracy and confusion matrix. We also learned how to save the trained model and the vectorizer to disk using the pickle library.
Overall, this project provided us with valuable experience in working with text data and building a machine learning model to classify it. We gained insights into the preprocessing techniques, feature extraction, model selection, and evaluation that are essential in building a successful machine learning model.
What's next for Fake News Detector
Improve accuracy: The current detector version is based on a simple machine learning algorithm, the Passive Aggressive Classifier. While it has shown decent accuracy, there may be more advanced models that could perform better. Developers could explore using more complex models, such as neural networks or ensemble methods that combine multiple models for improved accuracy.
Expand to new domains: The Fake News Detector is trained on news articles from a specific dataset. However, it could be expanded to work with other text types, such as social media posts or product reviews. This would require retraining the model on a new dataset but could greatly expand the project's scope.
Integrate with news apps: The Fake News Detector could be integrated with news apps or websites to help users evaluate the credibility of articles they are reading. This could help users make more informed decisions about what they read and share, potentially reducing the spread of fake news.
Develop a browser extension: A browser extension could be created that allows users to quickly evaluate the credibility of news articles they come across while browsing the web. This would make the Fake News Detector more accessible to a broader audience and help combat the spread of fake news online.

Log in or sign up for Devpost to join the conversation.