Fake News Detector
A multimodal fake news detection web app built with Streamlit, powered by DistilBERT, CLIP, Whisper, and audio prosody features. Detects misinformation in both text articles and videos.
Features
- Article Analysis — Paste text or provide a URL; the app scrapes and classifies the content using a DistilBERT-based model
- Video Analysis — Upload a video or provide a URL; the app transcribes speech (Whisper), extracts visual frame embeddings (CLIP), and audio prosody features (librosa) for multimodal classification
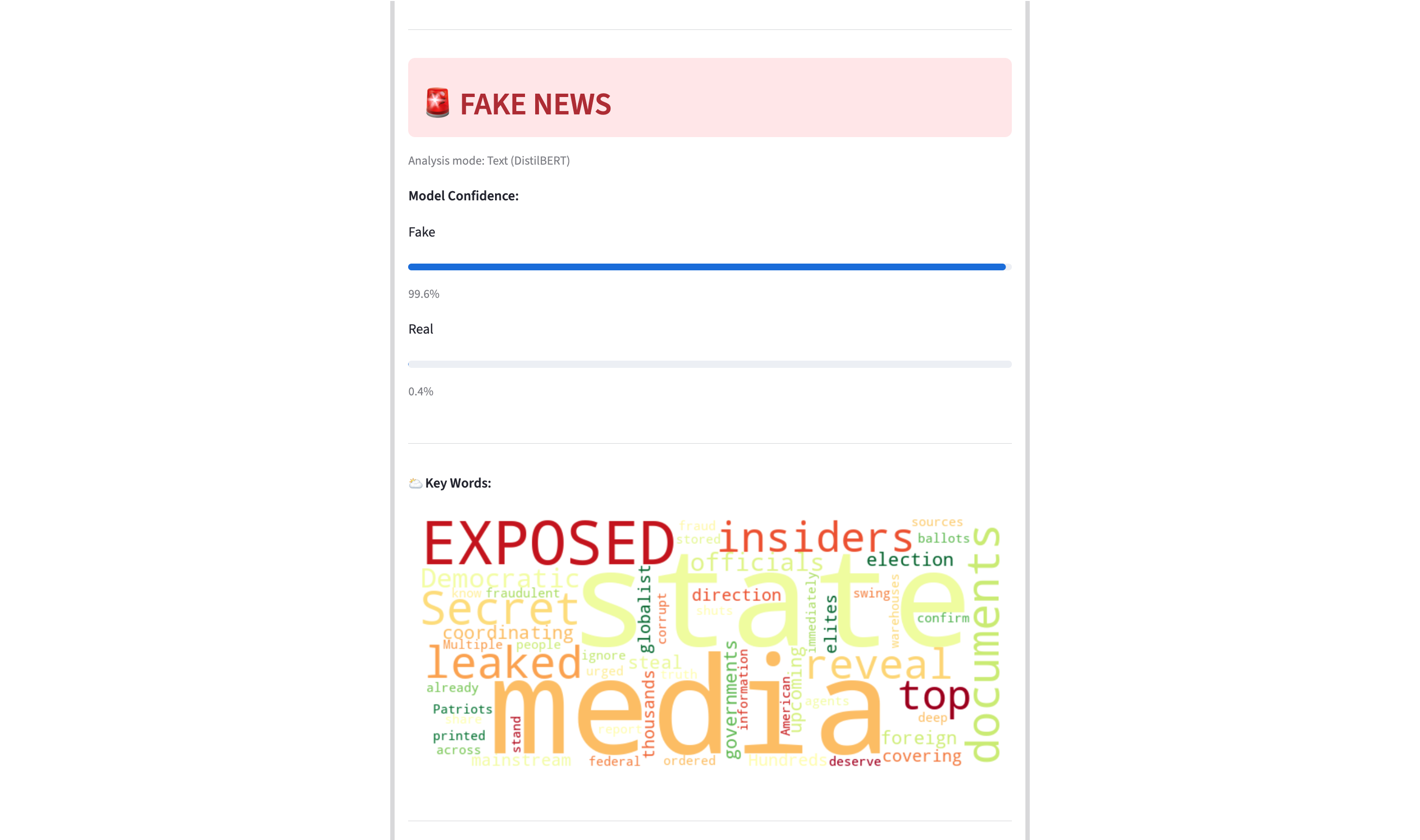
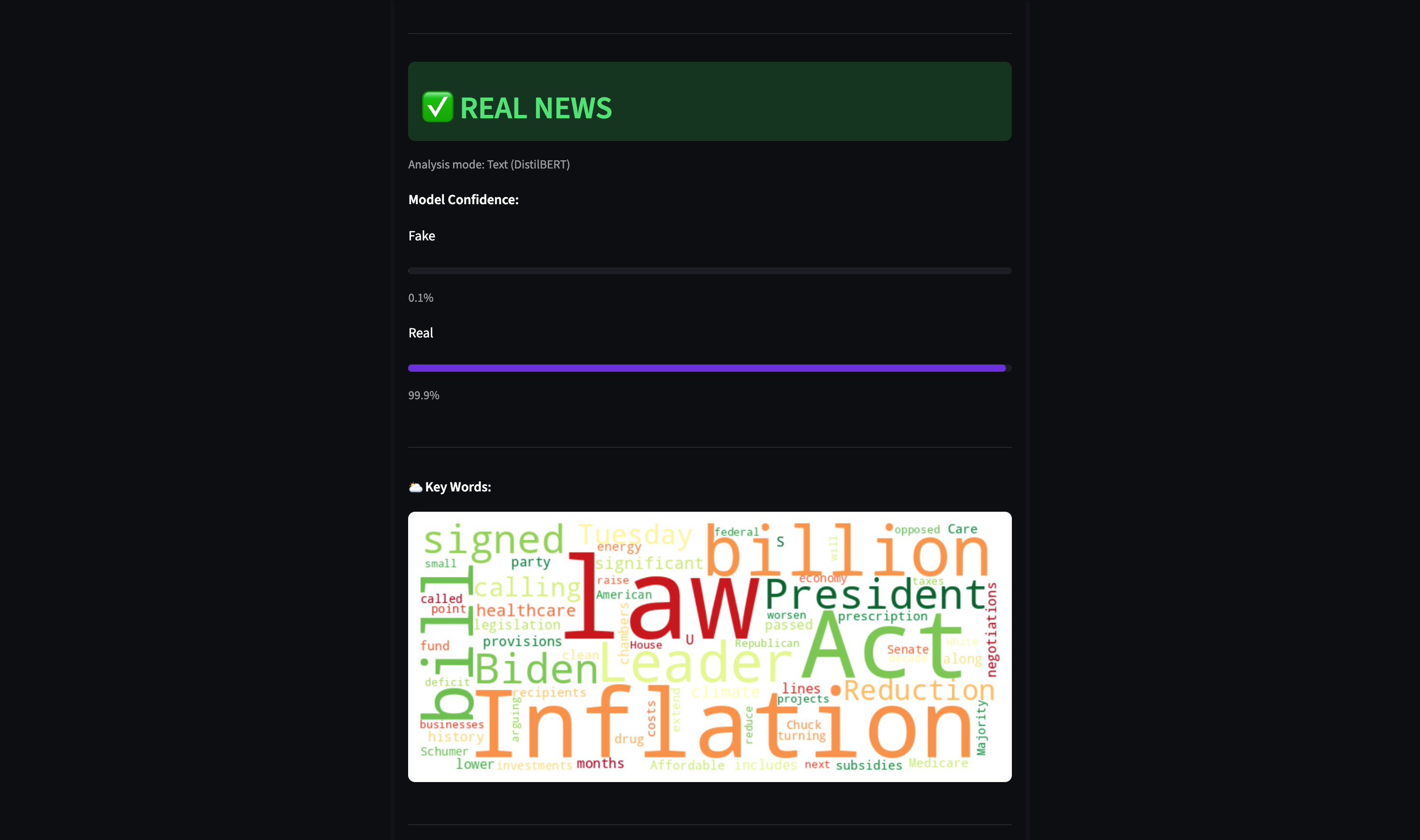
- Uncertainty flagging — Predictions below 70% confidence are flagged as ⚠️ UNCERTAIN instead of a hard verdict
- Word cloud — Visual breakdown of the most prominent words in analyzed text
Project Structure
fake-news-detector/
├── app.py # Entry point — page config and tab wiring
├── config.py # Constants (DEVICE, MAX_LEN, thresholds) and sample articles
├── loaders.py # Cached model and tokenizer loading (@st.cache_resource)
├── scraper.py # URL scraping via newspaper3k and BeautifulSoup
├── predictor.py # Text cleaning, tokenization, and inference functions
├── transcriber.py # Whisper-based audio transcription (file and URL)
├── ui.py # All Streamlit UI rendering (tabs, verdicts, word clouds)
├── model.py # TextClassifier and MultimodalClassifier model definitions
├── features.py # CLIP visual and librosa audio feature extraction
├── train_text.py # Training pipeline for the text model (WELFake + ISOT)
├── train.py # Training pipeline for the video/multimodal model
├── prep_mklab.py # MKLab FVC dataset video downloader
├── requirements.txt # Python dependencies
├── data/ # (User-created) Holds input datasets and cached features
└── model/ # (User-created) Holds trained model checkpoints
Models
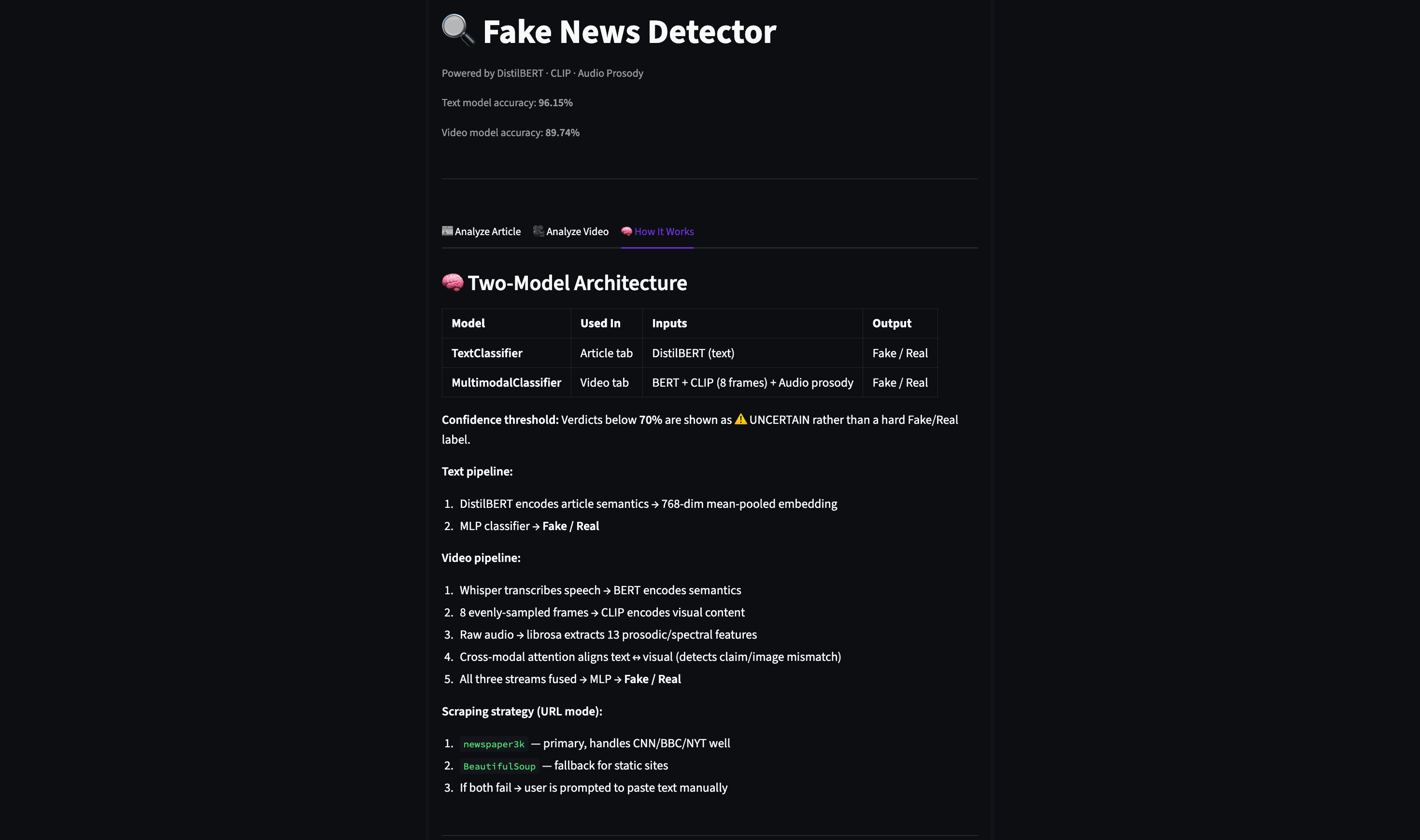
Text Model — TextClassifier
- Backbone: DistilBERT (
distilbert-base-uncased), fully frozen - Head: MLP (
Linear → LayerNorm → ReLU → Dropout → Linear) - Input: Mean-pooled 768-dim token embeddings (max 256 tokens)
- Training data: Up to 20,000 balanced samples from WELFake (and optionally ISOT)
- Optimization: Embeddings pre-computed once and cached to
data/text_embedding_cache.npz; only the MLP head is trained on subsequent runs
Video Model — MultimodalClassifier
- Text stream: BERT (
bert-base-uncased, last 2 layers unfrozen) → 768-dim - Visual stream: CLIP
ViT-B/32, 8 frames averaged → 512-dim → 256-dim projection - Audio stream: 13 prosody features (F0, spectral centroid, RMS, 7 MFCCs) → 128-dim projection
- Fusion: Cross-modal attention (text ↔ visual) → concatenation → classifier head
- Training: 25 epochs, AdamW + cosine LR decay, batch size 4, 25% modality dropout
| Dataset | Used For | Size |
|---|---|---|
| WELFake | Text model training | ~72k articles (4 corpora merged) |
| ISOT | Text model supplement | Optional |
| MKLab FVC | Video model training | Variable |
Confidence Threshold
Verdicts with confidence below 70% are displayed as ⚠️ UNCERTAIN to avoid misleading low-confidence classifications. This threshold is configured in config.py via CONFIDENCE_THRESHOLD.
Requirements
streamlit— web app frameworktransformers— DistilBERT and BERT modelsopenai-whisper— speech transcriptionopen-clip-torch— CLIP visual embeddingslibrosa— audio feature extractionnewspaper3k— article scrapingyt-dlp— video downloadingwordcloud,matplotlib— visualization
Built With
- clip
- librosa
- natural-language-processing
- python
- pytorch
- streamlit
- web-scraping
- whisper



Log in or sign up for Devpost to join the conversation.