Inspiration
This is our project for the MAIS 202 Winter 2021 ML bootcamp.
What it does
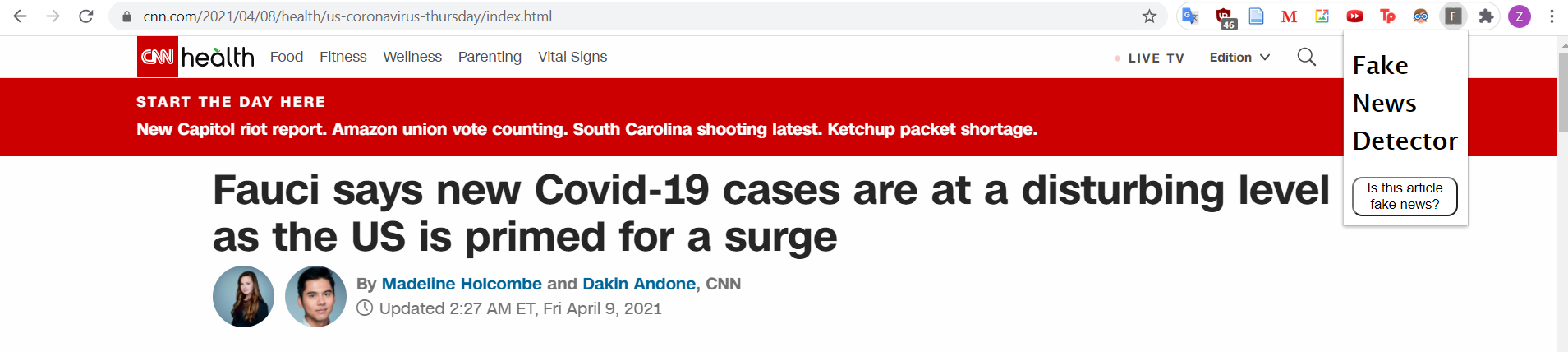
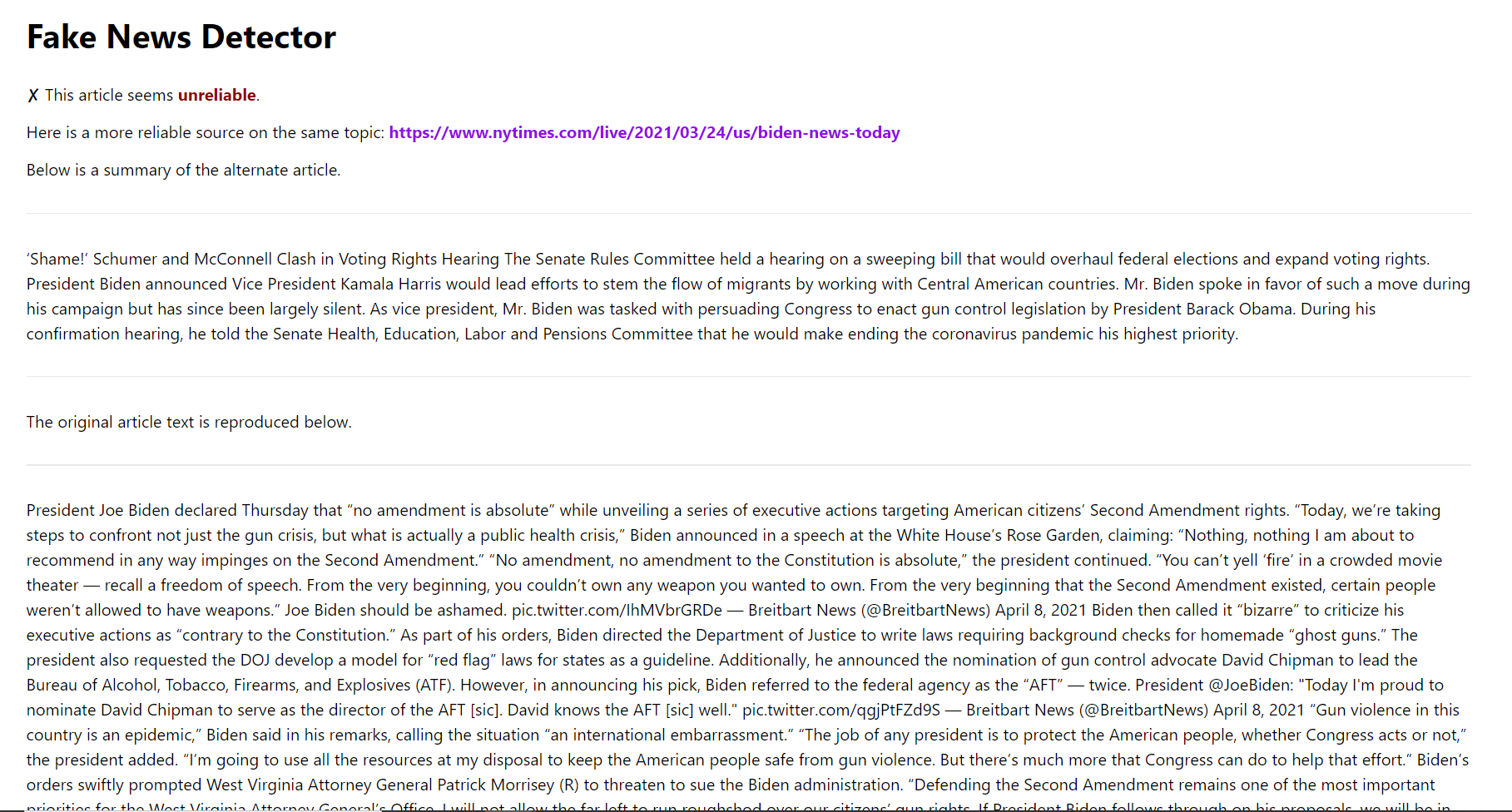
Given an article url it returns whether the article is reliable or not. In the latter case, it will scrape other news sites for similar articles and return an alternate reliable article with the greatest topic similarity.
How we built it
The project is built into a basic web app as well as a chrome extension. We used tfidf vectorization for text preprocessing, a Support Vector Machine with Stochastic Gradient Descent for the truth-label classification, and Singular Value Decomposition for the topic modelling, which combined with tfidf vectorization is also called Latent Semantic Analysis.
Challenges we ran into
It was difficult to find ways to successfully parse text as well as scrape for articles online. Furthermore, text classification encompasses way more than vocabulary use, so it is hard to get completely satisfying results with our classification model.
Accomplishments that we're proud of
As it is our first project of the sort, we're very proud to have a working end product that can sometimes return pretty satisfying results!
What we learned
ML model implementation, project building, API implementation, web development
What's next for Fake News Detector
We plan to clean out the chrome extension and add functionality like choosing specific sources to receive alternate articles from. We could also try different, more sophisticated NLP models for text classification and topic modelling.


Log in or sign up for Devpost to join the conversation.