-
-
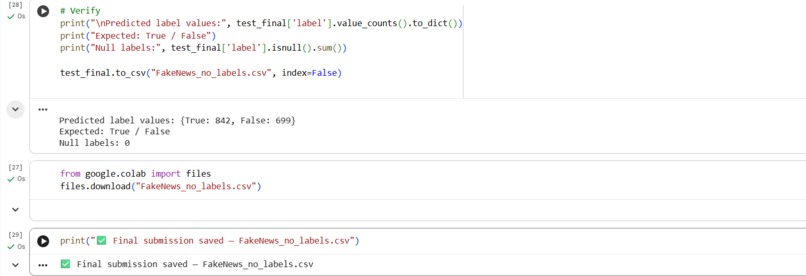
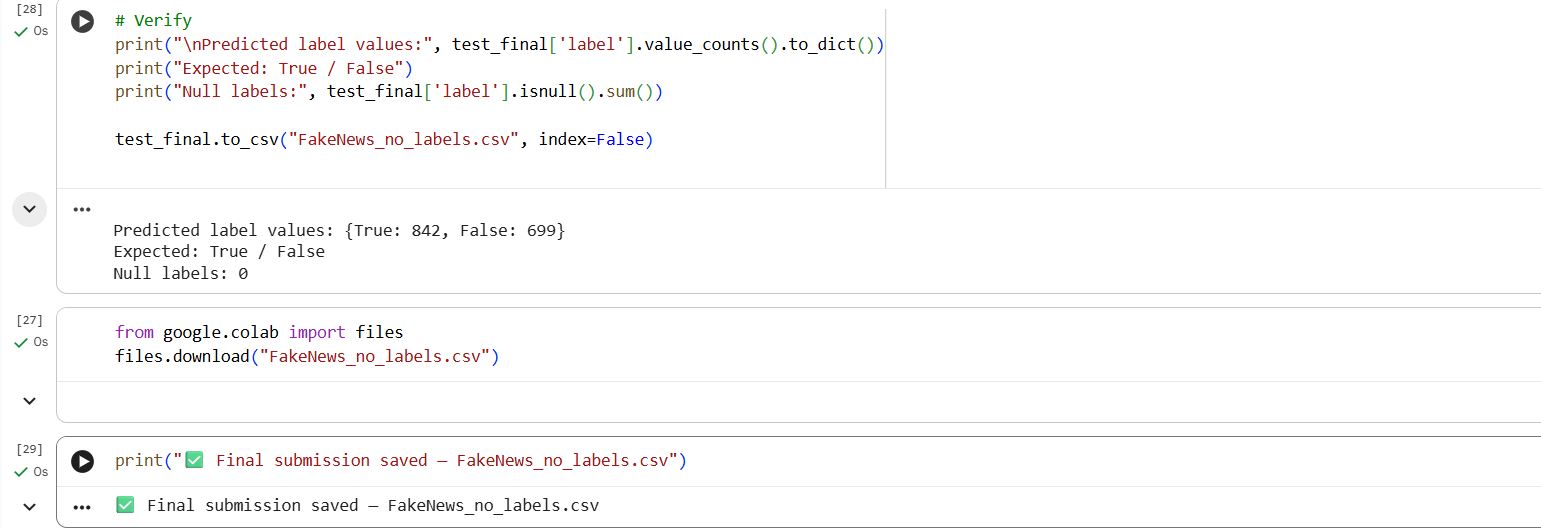
This is the screenshot of the verification of the model whether saved or not
-

This is the screenshot of the evaluation of the model , achieving an amazing accuracy of 99.87%

Inspiration
Misinformation spreads faster than facts in the digital age. Automated fake news detection at scale is critical to maintaining trust in online information ecosystems and protecting public opinion.
What IBuilt
A binary text classifier using RoBERTa-base fine-tuned to classify news articles as True (reliable) or False (fake/misleading).
How I Built It
- Combined title + [SEP] + text + [SEP] + subject columns for maximum article context
- Fine-tuned RoBERTa-base for 3 epochs on 18,176 labeled news articles
- 90/10 train-validation split with seed=42 for reproducibility
- max_length=256 to capture full article content
- Platform: Google Colab T4 GPU
Results
True → Precision: 1.00 | Recall: 1.00 | F1: 1.00
False → Precision: 1.00 | Recall: 1.00 | F1: 1.00
✅ Overall Accuracy: 99.87%
Challenges Faced
- Dataset had encoding issues (latin-1) requiring special handling
- Long news articles needed careful max_length tuning to capture full context
- Combining multiple text columns (title + text + subject) for richer feature signal
What I Learned
Combining all available text features with separator tokens significantly improves classification accuracy. RoBERTa's robust pretraining makes it extremely effective for fake news detection tasks.
Built With
- google-colab
- huggingface-transformers
- numpy
- pandas
- python
- pytorch
- roberta
- scikit-learn
- t4-gpu

Log in or sign up for Devpost to join the conversation.