-
-
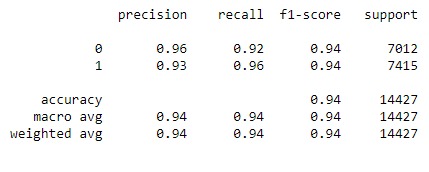
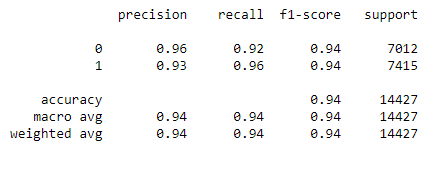
Classification Report
Inspiration
Fake news is a rising problem in the United States and around the world. Without the inherent selection that comes with paper newspapers, having to pay expensive publication costs demanding a higher level of credibility, fake news has taken over the media as a platform for sensationalist articles. With personal examples of friends and family members affected by fake news, and the disastrous effects exhibited during COVID-19, we decided to code an AI-based classification algorithm to categorize news.
What it does
The classifier algorithm trains itself on tens of thousands of test cases to classify news as real [0], and fake [1]. It takes an input of a title, in order to keep the algorithm light and efficient, and applies various functions to convert string data into a usable format for the algorithm.
How we built it
Our program uses a RandomForestClassifier to classify news as fake or real based on the title alone. It uses natural language processing libraries (namely nltk and WordCloud) in order to format titles into bows (Bag of Words) which can then be fed into the network and classified based on several key words. The dataset consists of ~70,000 test cases, 57,000 of which were used for training and the rest for testing. The dataset comes can be found at link
Challenges we ran into
There were 2 major challenges with this project. 1. The first was formatting the string data in a way that would be usable to the RandomForestClassifier. In order to keep the algorithm light and usable on all ends, we avoided neural networks and opted for a simpler classifier, which had the caveat that it could only use numerical data. We had to figure out how to process the strings to feed it into the network.
2. The second challenge was coding a single-prediction algorithm to make the program usable. The libraries we relied on were used to format CSV files, not singular strings, so additional functions had to be used to convert the string into a spreadsheet and formatted, then processed, then pulled from the CSV.
Accomplishments that we're proud of
The network was able to achieve ~94% accuracy on the testing set, signifying a reliable predictor. It also succeeded at classifying several of the individual test cases we made up. We are also proud that we were able to code a single prediction algorithm and optimize the algorithm to be as light as possible.
What we learned
In this project we mainly learned natural language processing, dataset sorting and manipulation, and research of the background of the issue.
What's next for Fake News Act
There are 2 main next steps for Fake News Act: 1. First, we would like to substitute the RandomForest algorithm with a fully-fledged natural language processing neural network, which would be able to more reliable classify new test data, and also look for more complex patterns in fake news and real news.
2. Second, we may also want to deploy the algorithm in a web app using vercel or streamlit in the future, or even produce an extension that can be used on browsers.


Log in or sign up for Devpost to join the conversation.