The inspiration to create this model came when there was huge amount of fake news being spammed on news channel and social media during the pandemic. Then the idea to create a model to filter out the fake news became the inspiration to create this model.
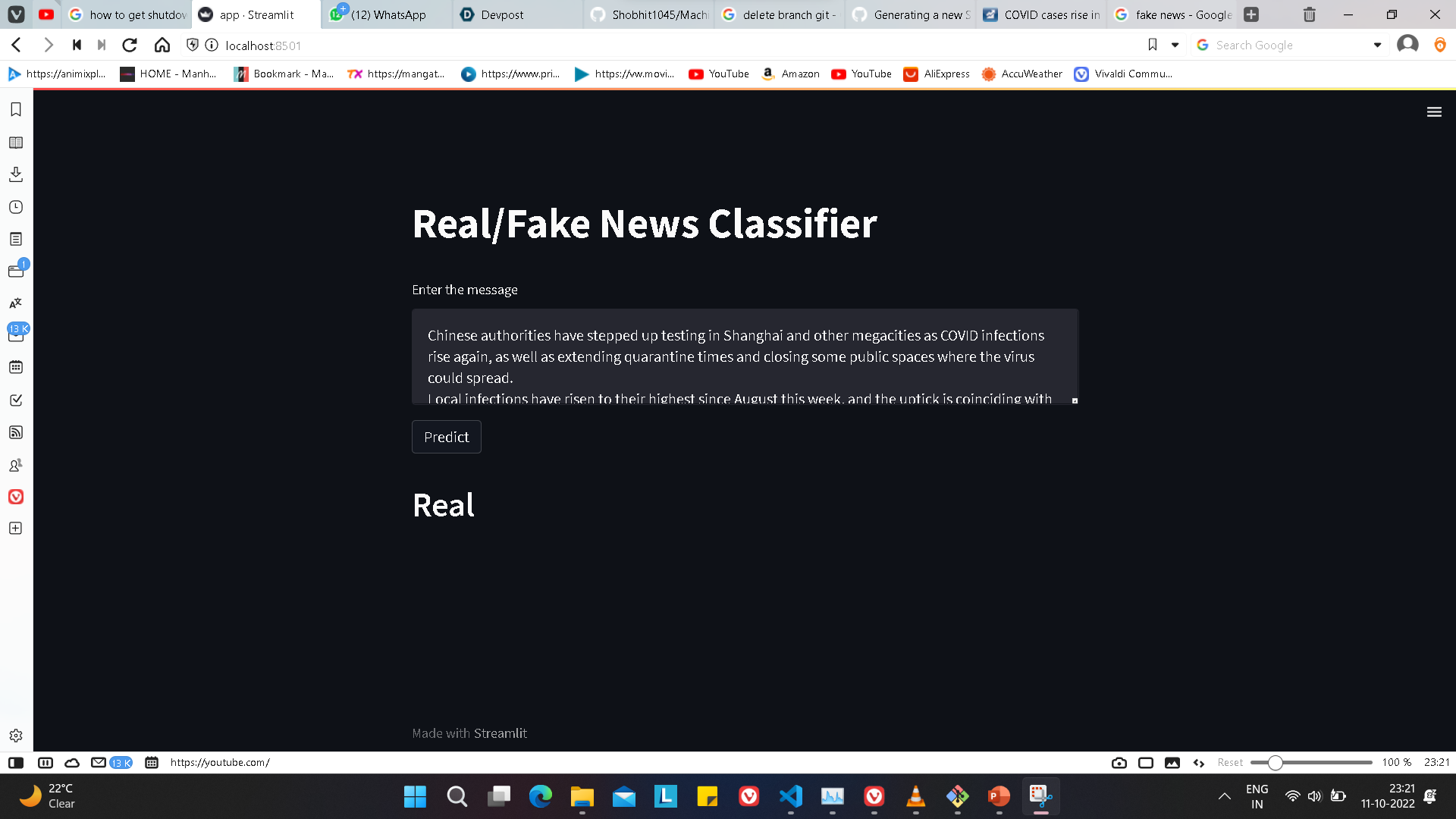
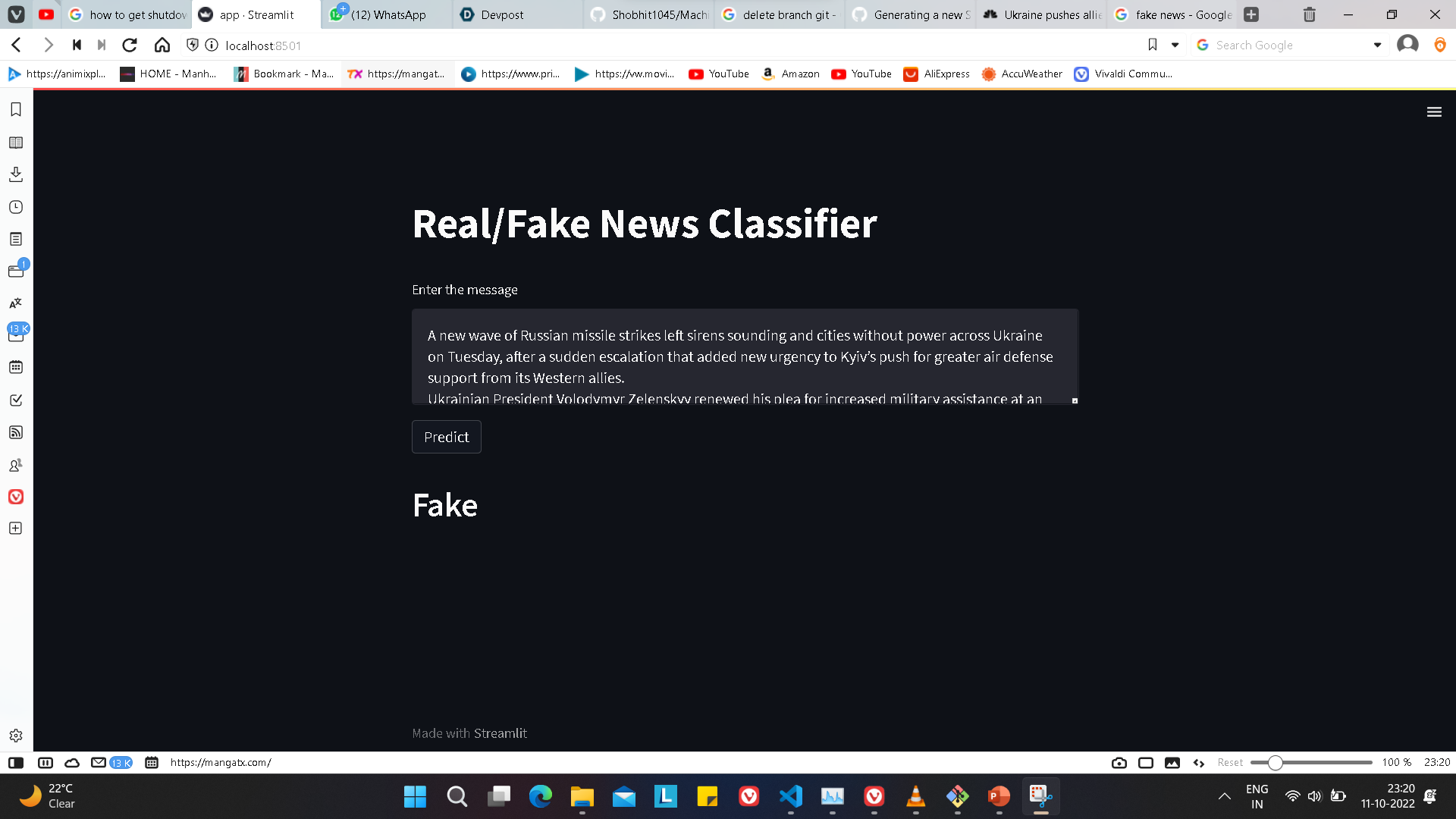
As it's name describe the purpose of this model is to differentiate out the fake and real news.
This model was built by tokenizing the data meaning taking out the root word from each word of the sentence and removing the duplicate words in that sentence. Then further finding out the most repeating words that have been tokenized throughout the whole data. And then training the model through Random Forest classifier with label coded as 0 and 1. Where 1 represent Real news and 0 represent Fake news.
The huge amount of data was a challenge in itself and also finding the best accuracy through different algorithms of machine learning took a lot of time through trial and error.
Learning how to manage big data and how to deploy a model was something new for me.

Log in or sign up for Devpost to join the conversation.